Core API
Documentation of the core API of pyaerocom.
Data classes
Gridded data
Ungridded data
Co-located data
Station data
Other data classes
Co-location routines
High-level co-location engine
Low-level co-location functions
Co-locating ungridded observations
Reading of gridded data
Gridded data specifies any dataset that can be represented and stored on a
regular grid within a certain domain (e.g. lat, lon time), for instance, model
output or level 3 satellite data, stored, for instance, as NetCDF files.
In pyaerocom, the underlying data object is GriddedData and
pyaerocom supports reading of such data for different file naming conventions.
Gridded data using AeroCom conventions
Gridded data using EMEP conventions
Reading of ungridded data
Other than gridded data, ungridded data represents data that is irregularly sampled in space and time, for instance, observations at different locations around the globe. Such data is represented in pyaerocom by UngriddedData which is essentially a point-cloud dataset. Reading of UngriddedData is typically specific for different observational data records, as they typically come in various data formats using various metadata conventions, which need to be harmonised, which is done during the data import.
The following flowchart illustrates the architecture of ungridded reading in pyaerocom. Below are information about the individual reading classes for each dataset (blue in flowchart), the abstract template base classes the reading classes are based on (dark green) and the factory class ReadUngridded (orange) which has registered all individual reading classes. The data classes that are returned by the reading class are indicated in light green.
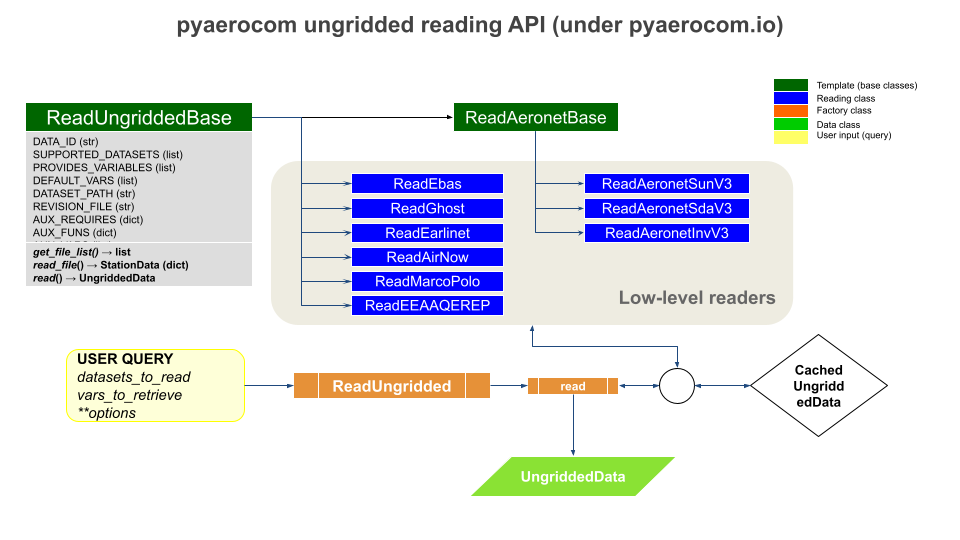
ReadUngridded factory class
Factory class that has all reading class for the individual datasets registered.
ReadUngriddedBase template class
All ungridded reading routines are based on this template class.
AERONET
Aerosol Robotic Network (AERONET)
AERONET base class
All AERONET reading classes are based on the template ReadAeronetBase
class which, in turn inherits from ReadUngriddedBase.
AERONET Sun (V3)
AERONET SDA (V3)
AERONET Inversion (V3)
EARLINET
EBAS
EBAS is a database with atmospheric measurement data hosted by the Norwegian Institute for Air Research. Declaration of AEROCOM variables in EBAS and assocaited information such as acceptable minimum and maximum values occurs in pyaerocom/data/variables.ini .
EBAS (low level)
EEA data
EEA base reader
Reader for European air pollution data from EEA AqERep files.
EEA E2a product (NRT)
Near realtime EEA data.
EEA E1a product (QC)
Quality controlled EEA data.
AirNow data
Reader for air quality measurements from North America.
MarcoPolo data
Reader for air quality measurements for China from the EU-FP7 project MarcoPolo.
GHOST
GHOST (Globally Harmonised Observational Surface Treatment) project developed at the Earth Sciences Department of the Barcelona Supercomputing Center (see e.g., Petetin et al., 2020 for more information).
Further I/O features
Note
The pyaerocom.io package also includes all relevant data import and reading routines. These are introduced above, in Section reading.
AeroCom database browser
File naming conventions
Iris helpers
Handling of cached ungridded data objects
I/O utils
I/O helpers
Metadata and vocabulary standards
Variables
Variable collection
Variable class
Variable helpers
Variable name info
Helpers for auxiliary variables
Variable categorisations
Regions and data filtering
Region class and helper functions
Region definitions
Region filter
Land / Sea masks
Time and frequencies
Handling of time frequencies
Temporal resampling
Global constants
Vertical coordinate support
Note
BETA: most functionality of this module is currently not implemented in any of the pyaerocom standard API.
Trends computation
Trends engine
Helper methods
Utility functions
Helpers
Mathematical helpers
Geodesic calculations and topography
Units and unit conversion
Units helpers in base package
Units helpers in io sub-package
Plotting / visualisation (sub package plot)
The pyaerocom.plot package contains algorithms related to data
visualisation and plotting.
Plotting of maps
Plotting coordinates on maps
Scatter plots
Heatmap plots
Colors schemes
Plot helper functions
Configuration and global constants
Basic configuration class
Will be initiated on input and is accessible via pyaerocom.const.
Config details related to observations
Settings and helper methods / classes for I/O of obervation data
Note
Some settings like paths etc can be found in pyaerocom.config.py
- class pyaerocom.obs_io.AuxInfoUngridded(data_id, vars_supported, aux_requires, aux_merge_how, aux_funs=None, aux_units=None)[source]
- MAX_VARS_PER_METHOD = 2
- check_status()[source]
Check if specifications are correct and consistent
- Raises:
ValueError – If one of the class attributes is invalid
NotImplementedError – If computation method contains more than 2 variables / datasets
- pyaerocom.obs_io.OBS_ALLOW_ALT_WAVELENGTHS = True
This boolean can be used to enable / disable the former (i.e. use available wavelengths of variable in a certain range around variable wavelength).
- pyaerocom.obs_io.OBS_WAVELENGTH_TOL_NM = 10.0
Wavelength tolerance for observations if data for required wavelength is not available
Access to minimal test dataset
Low-level helper classes and functions
Small helper utility functions for pyaerocom
- class pyaerocom._lowlevel_helpers.AsciiFileLoc(default=None, assert_exists=False, auto_create=False, tooltip=None, logger=None)[source]
- class pyaerocom._lowlevel_helpers.BrowseDict(*args, **kwargs)[source]
Dictionary-like object with getattr and setattr options
Extended dictionary that supports dynamic value generation (i.e. if an assigned value is callable, it will be executed on demand).
- ADD_GLOB = []
- FORBIDDEN_KEYS = []
- IGNORE_JSON = []
Keys to be ignored when converting to json
- MAXLEN_KEYS = 100.0
- SETTER_CONVERT = {}
- import_from(other) None[source]
Import key value pairs from other object
Other than
update()this method will silently ignore input keys that are not contained in this object.- Parameters:
other (dict or BrowseDict) – other dict-like object containing content to be updated.
- Raises:
ValueError – If input is inalid type.
- Return type:
None
- class pyaerocom._lowlevel_helpers.ConstrainedContainer(*args, **kwargs)[source]
Restrictive dict-like class with fixed keys
This class enables to create dict-like objects that have a fixed set of keys and value types (once assigned). Optional values may be instantiated as None, in which case the first time instantiation definecs its type.
Note
The limitations for assignments are only restricted to setitem operations and attr assignment via “.” works like in every other class.
Example
- class MyContainer(ConstrainedContainer):
- def __init__(self):
self.val1 = 1 self.val2 = 2 self.option = None
>>> mc = MyContainer() >>> mc['option'] = 42
- CRASH_ON_INVALID = True
- class pyaerocom._lowlevel_helpers.DirLoc(default=None, assert_exists=False, auto_create=False, tooltip=None, logger=None)[source]
- class pyaerocom._lowlevel_helpers.FlexList[source]
list that can be instantated via input str, tuple or list or None
- class pyaerocom._lowlevel_helpers.JSONFile(default=None, assert_exists=False, auto_create=False, tooltip=None, logger=None)[source]
- class pyaerocom._lowlevel_helpers.Loc(default=None, assert_exists=False, auto_create=False, tooltip=None, logger=None)[source]
Abstract descriptor representing a path location
Descriptor??? See here: https://docs.python.org/3/howto/descriptor.html#complete-practical-example
Note
Child classes need to implement
create()value is allowed to be None in which case no checks are performed
- pyaerocom._lowlevel_helpers.check_dir_access(path)[source]
Uses multiprocessing approach to check if location can be accessed
- pyaerocom._lowlevel_helpers.check_make_json(fp, indent=4)[source]
Make sure input json file exists
- Parameters:
- Raises:
ValueError – if filepath does not exist.
- Returns:
input filepath.
- Return type:
- pyaerocom._lowlevel_helpers.check_write_access(path)[source]
Check if input location provides write access
- Parameters:
path (str) – directory to be tested
- pyaerocom._lowlevel_helpers.chk_make_subdir(base, name)[source]
Check if sub-directory exists in parent directory
- pyaerocom._lowlevel_helpers.dict_to_str(dictionary, indent=0, ignore_null=False)[source]
Custom function to convert dictionary into string (e.g. for print)
- pyaerocom._lowlevel_helpers.invalid_input_err_str(argname, argval, argopts)[source]
Just a small helper to format an input error string for functions
- pyaerocom._lowlevel_helpers.list_to_shortstr(lst, indent=0)[source]
Custom function to convert a list into a short string representation
- pyaerocom._lowlevel_helpers.merge_dicts(dict1, dict2, discard_failing=True)[source]
Merge two dictionaries
- Parameters:
dict1 (dict) – first dictionary
dict2 (dict) – second dictionary
discard_failing (bool) – if True, any key, value pair that cannot be merged from the 2nd into the first will be skipped, which means, the value of the output dict for that key will be the one of the first input dict. All keys that could not be merged can be accessed via key ‘merge_failed’ in output dict. If False, any Exceptions that may occur will be raised.
- Returns:
merged dictionary
- Return type:
- pyaerocom._lowlevel_helpers.round_floats(in_data, precision=5)[source]
simple helper method to change all floats of a data structure to a given precision. For nested structures, this method is called recursively to go through all levels
- pyaerocom._lowlevel_helpers.sort_dict_by_name(d, pref_list: list | None = None) dict[source]
Sort entries of input dictionary by their names and return ordered
Custom exceptions
Module containing pyaerocom custom exceptions