Core API
Documentation of the core API of pyaerocom.
Logging
pyaerocom initializes logging automatically on import in the following way.
info-messages or worse are logged tologs/pyaerocom.log.$PIDor (dynamic feature) the file given in the environment variablePYAEROCOM_LOG_FILE- (dynamic feature) these log-files will be deleted after 7 days.warning-messages or worse are also printed on stdout. (dynamic feature) Output to stdout is disabled if the script is called non-interactive.
Besides the default records as defined in https://docs.python.org/3/library/logging.html#logrecord-attributes pyaerocom also adds a special mem_usage keyword to be able to detect memory-leaks of the python process early.
Putting a file with the name logging.ini in the scripts current working directory will use that
configuration instead of above described default. An example logging.ini doing about the same as
described above, except for the dynamic features, and enable debug logging on one package (pyaerocom.io.ungridded), is
provided here:
[loggers]
keys=root,pyaerocom-ungridded
[handlers]
keys=console,file
[formatters]
keys=plain,detailed
[formatter_plain]
format=%(message)s
[formatter_detailed]
format=%(asctime)s:%(name)s:%(mem_usage)s:%(levelname)s:%(message)s
datefmt=%F %T
[handler_console]
class=StreamHandler
formatter=plain
args=(sys.stdout,)
level=WARN
[handler_file]
class=FileHandler
formatter=detailed
level=DEBUG
file_name=logs/pyaerocom.log.%(pid)s
args=('%(file_name)s', "w")
[logger_root]
handlers=file,console
level=INFO
[logger_pyaerocom-ungridded]
handlers=file
qualname=pyaerocom.io.readungriddedbase
level=DEBUG
propagate=0
Data classes
Gridded data
- class pyaerocom.griddeddata.GriddedData(input=None, var_name=None, check_unit=True, convert_unit_on_init=True, proj_info: ProjectionInformation | None = None, **meta)[source]
pyaerocom object representing gridded data (e.g. model diagnostics)
Gridded data refers to data that can be represented on a regular, multidimensional grid. In
pyaerocomthis comprises both model output and diagnostics as well as gridded level 3 satellite data, typically with dimensions latitude, longitude, time (for surface or columnar data) and an additional dimension lev (or similar) for vertically resolved data.Under the hood, this data object is based on (but not inherited from) the
iris.cube.Cubeobject, and makes large use of the therein implemented functionality (many methods implemented here inGriddedDataare simply wrappers for Cube methods.Note
Note that the implemented functionality in this class is mostly limited to what is needed in the pyaerocom API (e.g. for
pyaerocom.colocationroutines or data import) and is not aimed at replacing or competing with similar data classes such asiris.cube.Cubeorxarray.DataArray. Rather, dependent on the use case, one or another of such gridded data objects is needed for optimal processing, which is whyGriddedDataprovides methods and / or attributes to convert to or from other such data classes (e.g.GriddedData.cubeis an instance ofiris.cube.Cubeand methodGriddedData.to_xarray()can be used to convert toxarray.DataArray). Thus,GriddedDatacan be considered rather high-level as compared to the other mentioned data classes from iris or xarray.Note
Since
GriddedDataobject is based on theiris.cube.Cubeobject it is optimised for netCDF files that follow the CF conventions and may not work out of the box for files that do not follow this standard.- Parameters:
input (
str:orCube) – data input. Can be a single .nc file or a preloaded iris Cube.var_name (
str, optional) – variable name that is extracted if input is a file path. Irrelevant if input is preloaded Cubecheck_unit (bool) – if True, the assigned unit is checked and if it is an alias to another unit the unit string will be updated. It will print a warning if the unit is invalid or not equal the associated AeroCom unit for the input variable. Set convert_unit_on_init to True, if you want an automatic conversion to AeroCom units. Defaults to True.
convert_unit_on_init (bool) – if True and if unit check indicates non-conformity with AeroCom unit it will be converted automatically, and warning will be printed if that conversion fails. Defaults to True.
- COORDS_ORDER_TSERIES = ['time', 'latitude', 'longitude']
Req. order of dimension coordinates for time-series computation
- SUPPORTED_VERT_SCHEMES = ['mean', 'max', 'min', 'surface', 'altitude', 'profile']
- property TS_TYPES
List with valid filename encryptions specifying temporal resolution
- aerocom_savename(data_id=None, var_name=None, vert_code=None, year=None, ts_type=None)[source]
Get filename for saving following AeroCom conventions
- Parameters:
data_id (str, optional) – data ID used in output filename. Defaults to None, in which case
data_idis used.var_name (str, optional) – variable name used in output filename. Defaults to None, in which case
var_nameis used.vert_code (str, optional) – vertical code used in output filename (e.g. Surface, Column, ModelLevel). Defaults to None, in which case assigned value in
metadatais used.year (str, optional) – year to be used in filename. If None, then it is attempted to be inferred from values in time dimension.
ts_type (str, optional) – frequency string to be used in filename. If None, then
ts_typeis used.
- Raises:
ValueError – if vertical code is not provided and cannot be inferred or if year is not provided and data is not single year. Note that if year is provided, then no sanity checking is done against time dimension.
- Returns:
output filename following AeroCom Phase 3 conventions.
- Return type:
- property altitude_access
- property area_weights
Area weights of lat / lon grid
- property base_year
Base year of time dimension
Note
Changing this attribute will update the time-dimension.
- change_base_year(new_year, inplace=True)[source]
Changes base year of time dimension
Relevant, e.g. for climatological analyses.
Note
This method does not account for offsets arising from leap years ( affecting daily or higher resolution data). It is thus recommended to use this method with care. E.g. if you use this method on a 2016 daily data object, containing a calendar that supports leap years, you’ll end up with 366 time stamps also in the new data object.
- Parameters:
- Returns:
modified data object
- Return type:
- check_dimcoords_tseries() None[source]
Check order of dimension coordinates for time series retrieval
For computation of time series at certain lon / lat coordinates, the data dimensions have to be in a certain order specified by
COORDS_ORDER_TSERIES.This method checks the current order (and dimensionality) of data and raises appropriate errors.
- Raises:
DataDimensionError – if dimension of data is not supported (currently, 3D or 4D data is supported)
NotImplementedError – if one of the required coordinates is associated with more than one dimension.
DimensionOrderError – if dimensions are not in the right order (in which case
reorder_dimensions_tseries()may be used to catch the Exception)
- collapsed(coords, aggregator, **kwargs)[source]
Collapse cube
Reimplementation of method
iris.cube.Cube.collapsed(), for details see here- Parameters:
coords (str or list) – string IDs of coordinate(s) that are to be collapsed (e.g.
["longitude", "latitude"])aggregator (str or Aggregator or WeightedAggretor) – the aggregator used. If input is string, it is converted into the corresponding iris Aggregator object, see
str_to_iris()for valid strings**kwargs – additional keyword args (e.g.
weights)
- Returns:
collapsed data object
- Return type:
- property computed
- property concatenated
- convert_unit(new_unit: str, inplace: bool = True) GriddedData[source]
Convert unit of data to new unit
- property coord_names
List containing coordinate names
- property coords_order
Array containing the order of coordinates
- copy_coords(other, inplace=True)[source]
Copy all coordinates from other data object
Requires the underlying data to be the same shape.
Warning
This operation will delete all existing coordinates and auxiliary coordinates and will then copy the ones from the input data object. No checks of any kind will be performed
- Parameters:
other (GriddedData or Cube) – other data object (needs to be same shape as this object)
inplace (bool) – if True, then this object will be modified and returned, else a copy.
- Returns:
data object containing coordinates from other object
- Return type:
- crop(lon_range=None, lat_range=None, time_range=None, region=None)[source]
High level function that applies cropping along multiple axes
Note
1. For cropping of longitudes and latitudes, the method
iris.cube.Cube.intersection()is used since it automatically accepts and understands longitude input based on definition 0 <= lon <= 360 as well as for -180 <= lon <= 180 2. Time extraction may be provided directly as index or in form ofpandas.Timestampobjects.- Parameters:
lon_range (
tuple, optional) – 2-element tuple containing longitude range for cropping. If None, the longitude axis remains unchanged. Example input to crop around meridian: lon_range=(-30, 30)lat_range (
tuple, optional) – 2-element tuple containing latitude range for cropping. If None, the latitude axis remains unchangedtime_range (
tuple, optional) –2-element tuple containing time range for cropping. Allowed data types for specifying the times are
a combination of 2
pandas.Timestampinstances ora combination of two strings that can be directly converted into
pandas.Timestampinstances (e.g. time_range=(“2010-1-1”, “2012-1-1”)) ordirectly a combination of indices (
int).
If None, the time axis remains unchanged.
region (
strorRegion, optional) – string ID of pyaerocom default region or directly an instance of theRegionobject. May be used instead oflon_rangeandlat_range, if these are unspecified.
- Returns:
new data object containing cropped grid
- Return type:
- property cube
Instance of underlying cube object
- property data
Data array (n-dimensional numpy array)
Note
This is a pointer to the data object of the underlying iris.Cube instance and will load the data into memory. Thus, in case of large datasets, this may lead to a memory error
- property data_id
ID of data object (e.g. model run ID, obsnetwork ID)
Note
This attribute was formerly named
namewhich is also the corresponding attribute name inmetadata
- property data_revision
Revision string from file Revision.txt in the main data directory
- delete_all_coords(inplace=True)[source]
Deletes all coordinates (dimension + auxiliary) in this object
- property delta_t
Array containing timedelta values for each time stamp
- property dimcoord_names
List containing coordinate names
- estimate_value_range_from_data(extend_percent=5)[source]
Estimate lower and upper end of value range for these data
- Parameters:
extend_percent (int) – percentage specifying to which extend min and max values are to be extended to estimate the value range. Defaults to 5.
- Returns:
float – lower end of estimated value range
float – upper end of estimated value range
- extract(constraint, inplace=False)[source]
Extract subset
- Parameters:
constraint (iris.Constraint) – constraint that is to be applied
- Returns:
new data object containing cropped data
- Return type:
- filter_altitude(alt_range=None)[source]
Currently dummy method that makes life easier in
Filter- Returns:
current instance
- Return type:
- filter_region(region_id, inplace=False, **kwargs)[source]
Filter region based on ID
This works both for rectangular regions and mask regions
- Parameters:
region_id (str) – name of region
inplace (bool) – if True, the current data object is modified, else a new object is returned
**kwargs – additional keyword args passed to
apply_region_mask()if input region is a mask.
- Returns:
filtered data object
- Return type:
- find_closest_index(**dimcoord_vals)[source]
Find the closest indices for dimension coordinate values
- property from_files
List of file paths from which this data object was created
- get_area_weighted_timeseries(region=None)[source]
Helper method to extract area weighted mean timeseries
- Parameters:
region – optional, name of AeroCom default region for which the mean is to be calculated (e.g. EUROPE)
- Returns:
station data containing area weighted mean
- Return type:
- get_xyranges() tuple[list[tuple[float, float]]][source]
Finds the max/min ranges for x and y. Done by taking first and last point in each dimension. This might be the middle point of the bounding cells
- Returns:
Two list, one for xs and one for ys
- Return type:
- Raises:
ValueError – If self has no proj_info
VariableDefinitionError – If there is a child where x or y is not found
- property grid
Underlying grid data object
- property has_data
True if sum of shape of underlying Cube instance is > 0, else False
- property has_latlon_dims
Boolean specifying whether data has latitude and longitude dimensions
- property has_time_dim
Boolean specifying whether data has latitude and longitude dimensions
- infer_ts_type()[source]
Try to infer sampling frequency from time dimension data
- Returns:
ts_type that was inferred (is assigned to metadata too)
- Return type:
- Raises:
DataDimensionError – if data object does not contain a time dimension
- interpolate(sample_points=None, scheme='nearest', collapse_scalar=True, **coords)[source]
Interpolate cube at certain discrete points
Reimplementation of method
iris.cube.Cube.interpolate(), for details see hereNote
The input coordinates may also be provided using the input arg **coords which provides a more intuitive option (e.g. input
(sample_points=[("longitude", [10, 20]), ("latitude", [1, 2])])is the same as input(longitude=[10, 20], latitude=[1,2])- Parameters:
sample_points (list) – sequence of coordinate pairs over which to interpolate. Sample coords should be sorted in ascending order without duplicates.
scheme (str or iris interpolator object) – interpolation scheme, pyaerocom default is nearest. If input is string, it is converted into the corresponding iris Interpolator object, see
str_to_iris()for valid stringscollapse_scalar (bool) – Whether to collapse the dimension of scalar sample points in the resulting cube. Default is True.
**coords – additional keyword args that may be used to provide the interpolation coordinates in an easier way than using the
Cubeargument sample_points. May also be a combination of both.
- Returns:
new data object containing interpolated data
- Return type:
- intersection(*args, **kwargs)[source]
Ectract subset using
iris.cube.Cube.intersection()See here for details related to method and input parameters.
Note
Only works if underlying grid data type is
iris.cube.Cube- Parameters:
*args – non-keyword args
**kwargs – keyword args
- Returns:
new data object containing cropped data
- Return type:
- property is_climatology
- property is_masked
Flag specifying whether data is masked or not
Note
This method only works if the data is loaded.
- property lat_res
- load_input(input, var_name=None, perform_fmt_checks=None)[source]
Import input as cube
- Parameters:
input (
str:orCube) – data input. Can be a single .nc file or a preloaded iris Cube.var_name (
str, optional) – variable name that is extracted if input is a file path . Irrelevant if input is preloaded Cubeperform_fmt_checks (bool, optional) – perform formatting checks based on information in filenames. Only relevant if input is a file
- property lon_res
- property long_name
Long name of variable
- mean(areaweighted=True)[source]
Mean value of data array
Note
Corresponds to numerical mean of underlying N-dimensional numpy array. Does not consider area-weights or any other advanced averaging.
- mean_at_coords(latitude=None, longitude=None, time_resample_kwargs=None, **kwargs)[source]
Compute mean value at all input locations
- Parameters:
latitude (1D list or similar) – list of latitude coordinates of coordinate locations. If None, please provided coords in iris style as list of (lat, lon) tuples via coords (handled via arg kwargs)
longitude (1D list or similar) – list of longitude coordinates of coordinate locations. If None, please provided coords in iris style as list of (lat, lon) tuples via coords (handled via arg kwargs)
time_resample_kwargs (dict, optional) – time resampling arguments passed to
StationData.resample_time()**kwargs – additional keyword args passed to
to_time_series()
- Returns:
mean value at coordinates over all times available in this object
- Return type:
- property metadata
- property name
ID of model to which data belongs
- property ndim
Number of dimensions
- property plot_settings
Variableinstance that contains plot settingsThe settings can be specified in the variables.ini file based on the unique var_name, see e.g. here
If no default settings can be found for this variable, all parameters will be initiated with
None, in which case the Aerocom plot method uses
- property proj_info: ProjectionInformation
- quickplot_map(time_idx=0, xlim=(-180, 180), ylim=(-90, 90), add_mean=True, **kwargs)[source]
Make a quick plot onto a map
- Parameters:
time_idx (int) – index in time to be plotted
xlim (tuple) – 2-element tuple specifying plotted longitude range
ylim (tuple) – 2-element tuple specifying plotted latitude range
add_mean (bool) – if True, the mean value over the region and period is inserted
**kwargs – additional keyword arguments passed to
pyaerocom.quickplot.plot_map()
- Returns:
matplotlib figure instance containing plot
- Return type:
fig
- property reader
Instance of reader class from which this object was created
Note
Currently only supports instances of
ReadGridded.
- regrid(other=None, lat_res_deg=None, lon_res_deg=None, scheme='areaweighted', **kwargs)[source]
Regrid this grid to grid resolution of other grid
- Parameters:
other (GriddedData or Cube, optional) – other data object to regrid to. If None, then input args lat_res and lon_res are used to regrid.
lat_res_deg (float or int, optional) – latitude resolution in degrees (is only used if input arg other is None)
lon_res_deg (float or int, optional) – longitude resolution in degrees (is only used if input arg other is None)
scheme (str) – regridding scheme (e.g. linear, neirest, areaweighted)
- Returns:
regridded data object (new instance, this object remains unchanged)
- Return type:
- remove_outliers(low=None, high=None, inplace=True)[source]
Remove outliers from data
- Parameters:
low (float) – lower end of valid range for input variable. If None, then the corresponding value from the default settings for this variable are used (cf. minimum attribute of available variables)
high (float) – upper end of valid range for input variable. If None, then the corresponding value from the default settings for this variable are used (cf. maximum attribute of available variables)
inplace (bool) – if True, this object is modified, else outliers are removed in a copy of this object
- Returns:
modified data object
- Return type:
- reorder_dimensions_tseries() None[source]
Transpose dimensions of data such that
to_time_series()works- Raises:
DataDimensionError – if not all needed coordinates are available
NotImplementedError – if one of the required coordinates is associated with more than one dimension.
- resample_time(to_ts_type, how=None, min_num_obs=None, use_iris=False)[source]
Resample time to input resolution
- Parameters:
to_ts_type (str) – either of the supported temporal resolutions (cf.
IRIS_AGGREGATORSinhelpers, e.g. “monthly”)how (str) – string specifying how the data is to be aggregated, default is mean
min_num_obs (dict or int, optional) –
integer or nested dictionary specifying minimum number of observations required to resample from higher to lower frequency. For instance, if input_data is hourly and to_ts_type is monthly, you may specify something like:
min_num_obs = {'monthly' : {'daily' : 7}, 'daily' : {'hourly' : 6}}
to require at least 6 hours per day and 7 days per month.
use_iris (bool) – option to use resampling scheme from iris library rather than xarray.
- Returns:
new data object containing downscaled data
- Return type:
- Raises:
TemporalResolutionError – if input resolution is not provided, or if it is higher temporal resolution than this object
- search_other(var_name)[source]
Searches data for another variable
The search is constrained to the time period spanned by this object and it is attempted to load the same frequency. Uses
reader(instance ofReadGriddedto search for the other variable data).- Parameters:
var_name (str) – variable to be searched
- Raises:
VariableNotFoundError – if data for input variable cannot be found.
- Returns:
input variable data
- Return type:
- sel(use_neirest=True, **dimcoord_vals)[source]
Select subset by dimension names
Note
This is a BETA version, please use with care
- Parameters:
**dimcoord_vals – key / value pairs specifying coordinate values to be extracted
- Returns:
subset data object
- Return type:
- property shape
- split_years(years=None)[source]
Generator to split data object into individual years
Note
This is a generator method and thus should be looped over
- Parameters:
years (list, optional) – List of years that should be excluded. If None, it uses output from
years_avail().- Yields:
GriddedData – single year data object
- property standard_name
Standard name of variable
- property start
Start time of dataset as datetime64 object
- property stop
Start time of dataset as datetime64 object
- property suppl_info
- time_stamps()[source]
Convert time stamps into list of numpy datetime64 objects
The conversion is done using method
cfunit_to_datetime64()- Returns:
list containing all time stamps as datetime64 objects
- Return type:
- to_netcdf(out_dir, savename=None, **kwargs)[source]
Save as NetCDF file
- Parameters:
out_dir (str) – output directory (must exist)
savename (str, optional) – name of file. If None,
aerocom_savename()is used which is generated automatically and may be modified via **kwargs**kwargs – keywords for name
- Returns:
list of output files created
- Return type:
- to_time_series(sample_points=None, scheme='nearest', vert_scheme=None, add_meta=None, use_iris=False, **coords) list[StationData][source]
Extract time-series for provided input coordinates (lon, lat)
Extract time series for each lon / lat coordinate in this cube or at predefined sample points (e.g. station data). If sample points are provided, the cube is interpolated first onto the sample points.
- Parameters:
sample_points (list) – coordinates (e.g. lon / lat) at which time series is supposed to be retrieved
scheme (str or iris interpolator object) – interpolation scheme (for details, see
interpolate())vert_scheme (str) – string specifying how to treat vertical coordinates. This is only relevant for data that contains vertical levels. It will be ignored otherwise. Note that if the input coordinate specifications contain altitude information, this parameter will be set automatically to ‘altitude’. Allowed inputs are all data collapse schemes that are supported by
pyaerocom.helpers.str_to_iris()(e.g. mean, median, sum). Further valid schemes are altitude, surface, profile. If not other specified and if altitude coordinates are provided via sample_points (or **coords parameters) then, vert_scheme will be set to altitude. Else, profile is used.add_meta (dict, optional) – dictionary specifying additional metadata for individual input coordinates. Keys are meta attribute names (e.g. station_name) and corresponding values are lists (with length of input coords) or single entries that are supposed to be assigned to each station. E.g. add_meta=dict(station_name=[<list_of_station_names>])).
**coords – additional keyword args that may be used to provide the interpolation coordinates (for details, see
interpolate())
- Returns:
list of result dictionaries for each coordinate. Dictionary keys are:
longitude, latitude, var_name- Return type:
- transpose(new_order)[source]
Re-order data dimensions in object
Wrapper for
iris.cube.Cube.transpose()Note
Changes THIS object (i.e. no new instance of
GriddedDatawill be created)- Parameters:
order (list) – new index order
- property ts_type
Temporal resolution of data
- property unit
Unit of data
- property unit_ok
Boolean specifying if variable unit is AeroCom default
- property units
Unit of data
- update_meta(**kwargs)[source]
Update metadata dictionary
- Parameters:
**kwargs – metadata to be added to
metadata.
- property var_info
Print information about variable
- property var_name_aerocom
AeroCom variable name
- property vert_code
Vertical code of data (e.g. Column, Surface, ModelLevel)
Ungridded data
- class pyaerocom.ungriddeddata.UngriddedData(num_points=None, add_cols=None)[source]
Class representing point-cloud data (ungridded)
The data is organised in a 2-dimensional numpy array where the first index (rows) axis corresponds to individual measurements (i.e. one timestamp of one variable) and along the second dimension (containing 11 columns) the actual values are stored (in column 6) along with additional information, such as metadata index (can be used as key in
metadatato access additional information related to this measurement), timestamp, latitude, longitude, altitude of instrument, variable index and, in case of 3D data (e.g. LIDAR profiles), also the altitude corresponding to the data value.Note
That said, let’s look at two examples.
Example 1: Suppose you load 3 variables from 5 files, each of which contains 30 timestamps. This corresponds to a total of 3*5*30=450 data points and hence, the shape of the underlying numpy array will be 450x11.
Example 2: 3 variables, 5 files, 30 timestamps, but each variable is height resolved, containing 100 altitudes => 3*5*30*100=4500 data points, thus, the final shape will be 4500x11.
- metadata
dictionary containing meta information about the data. Keys are floating point numbers corresponding to each station, values are corresponding dictionaries containing station information.
- meta_idx
dictionary containing index mapping for each station and variable. Keys correspond to metadata key (float -> station, see
metadata) and values are dictionaries containing keys specifying variable name and corresponding values are arrays or lists, specifying indices (rows) of these station / variable information in_data. Note: this information is redundant and is there to accelerate station data extraction since the data index matches for a given metadata block do not need to be searched in the underlying numpy array.
- var_idx
mapping of variable name (keys, e.g. od550aer) to numerical variable index of this variable in data numpy array (in column specified by
_VARINDEX)
- Parameters:
- add_chunk(size=None)[source]
Extend the size of the data array
- Parameters:
size (
int, optional) – number of additional rows. If None (default) or smaller than minimum chunksize specified in attribute_CHUNKSIZE, then the latter is used.
- all_datapoints_var(var_name)[source]
Get array of all data values of input variable
- Parameters:
var_name (str) – variable name
- Returns:
1-d numpy array containing all values of this variable
- Return type:
ndarray
- Raises:
AttributeError – if variable name is not available
- append_station_data(stats, add_meta_keys=None)[source]
Append StationData(s) to this UngriddedDataContainer
- Parameters:
stats (iterator or StationData) – input data object(s)
add_meta_keys (list, optional) – list of metadata keys that are supposed to be imported from the input StationData objects, in addition to the default metadata retrieved via
StationData.get_meta().
- Raises:
ValueError – if any of the input data objects is not an instance of
StationData.- Returns:
ungridded data object created from input station data objects
- Return type:
UngriddedDataContainer
- clear_meta_no_data(inplace=True)[source]
Remove all metadata blocks that do not have data associated with it
- Parameters:
inplace (bool) – if True, the changes are applied to this instance directly, else to a copy
- Returns:
cleaned up data object
- Return type:
- Raises:
DataCoverageError – if filtering results in empty data object
- copy()[source]
Make a copy of this object
- Returns:
copy of this object
- Return type:
- Raises:
MemoryError – if copy is too big to fit into memory together with existing instance
- extract_var(var_name, check_index=True)[source]
Split this object into single-var UngriddedData objects
- Parameters:
var_name (str) – name of variable that is supposed to be extracted
check_index (Bool) – Call
_check_index()in the new data object.
- Returns:
new data object containing only input variable data
- Return type:
- extract_vars(var_names, check_index=True)[source]
Extract multiple variables from dataset
Loops over input variable names and calls
extract_var()to retrieve single variable UngriddedData objects for each variable and then merges all of these into one object- Parameters:
- Returns:
new data object containing input variables
- Return type:
- Raises:
VarNotAvailableError – if one of the input variables is not available in this data object
- static from_station_data(stats: StationData, add_meta_keys: list[str] | None = None) UngriddedData[source]
Create UngriddedData from input station data object(s)
- Parameters:
stats (iterator or StationData) – input data object(s)
add_meta_keys (list, optional) – list of metadata keys that are supposed to be imported from the input StationData objects, in addition to the default metadata retrieved via
StationData.get_meta().
- Raises:
ValueError – if any of the input data objects is not an instance of
StationData.- Returns:
ungridded data object created from input station data objects
- Return type:
UngriddedDataMeta
- property has_flag_data
Boolean specifying whether this object contains flag data
- property index
- property last_meta_idx
Index of last metadata block
- merge(other, new_obj=True)[source]
Merge another data object with this one
- Parameters:
other (UngriddedData) – other data object
new_obj (bool) – if True, this object remains unchanged and the merged data objects are returned in a new instance of
UngriddedData. If False, then this object is modified
- Returns:
merged data object
- Return type:
- Raises:
ValueError – if input object is not an instance of
UngriddedData
- merge_common_meta(ignore_keys=None)[source]
Merge all meta entries that are the same
Note
If there is an overlap in time between the data, the blocks are not merged
- Parameters:
ignore_keys (list) – list containing meta keys that are supposed to be ignored
- Returns:
merged data object
- Return type:
- remove_outliers(var_name, inplace=False, low=None, high=None, unit_ref=None, move_to_trash=True)[source]
Method that can be used to remove outliers from data
- Parameters:
var_name (str) – variable name
inplace (bool) – if True, the outliers will be removed in this object, otherwise a new object will be created and returned
low (float) – lower end of valid range for input variable. If None, then the corresponding value from the default settings for this variable are used (cf. minimum attribute of available variables)
high (float) – upper end of valid range for input variable. If None, then the corresponding value from the default settings for this variable are used (cf. maximum attribute of available variables)
unit_ref (str) – reference unit for assessment of input outlier ranges: all data needs to be in that unit, else an Exception will be raised
move_to_trash (bool) – if True, then all detected outliers will be moved to the trash column of this data object (i.e. column no. specified at
UngriddedData._TRASHINDEX).
- Returns:
ungridded data object that has all outliers for this variable removed.
- Return type:
- Raises:
ValueError – if input
move_to_trashis True and in case for some of the measurements there is already data in the trash.
- set_flags_nan(inplace=False)[source]
Set all flagged datapoints to NaN
- Parameters:
inplace (bool) – if True, the flagged datapoints will be set to NaN in this object, otherwise a new object will be created and returned
- Returns:
data object that has all flagged data values set to NaN
- Return type:
- Raises:
AttributeError – if no flags are assigned
- property shape
Shape of data array
- to_station_data(meta_idx, vars_to_convert=None, start=None, stop=None, freq=None, ts_type_preferred=None, merge_if_multi=True, merge_pref_attr=None, merge_sort_by_largest=True, insert_nans=False, allow_wildcards_station_name=True, add_meta_keys=None, resample_how=None, min_num_obs=None)[source]
Convert data from one station to
StationData- Parameters:
meta_idx (float) – index of station or name of station.
vars_to_convert (
listorstr, optional) – variables that are supposed to be converted. If None, use all variables that are available for this stationstart – start time, optional (if not None, input must be convertible into pandas.Timestamp)
stop – stop time, optional (if not None, input must be convertible into pandas.Timestamp)
freq (str) – pandas frequency string (e.g. ‘D’ for daily, ‘M’ for month end) or valid pyaerocom ts_type
merge_if_multi (bool) – if True and if data request results in multiple instances of StationData objects, then these are attempted to be merged into one
StationDataobject usingmerge_station_data()merge_pref_attr – only relevant for merging of multiple matches: preferred attribute that is used to sort the individual StationData objects by relevance. Needs to be available in each of the individual StationData objects. For details cf.
pref_attrin docstring ofmerge_station_data(). Example could be revision_date. If None, then the stations will be sorted based on the number of available data points (ifmerge_sort_by_largestis True, which is default).merge_sort_by_largest (bool) – only relevant for merging of multiple matches: cf. prev. attr. and docstring of
merge_station_data()method.insert_nans (bool) – if True, then the retrieved
StationDataobjects are filled with NaNsallow_wildcards_station_name (bool) – if True and if input meta_idx is a string (i.e. a station name or pattern), metadata matches will be identified applying wildcard matches between input meta_idx and all station names in this object.
- Returns:
StationData object(s) containing results. list is only returned if input for meta_idx is station name and multiple matches are detected for that station (e.g. data from different instruments), else single instance of StationData. All variable time series are inserted as pandas Series
- Return type:
StationData or list
- to_station_data_all(vars_to_convert=None, start=None, stop=None, freq=None, ts_type_preferred=None, by_station_name=True, ignore_index=None, **kwargs)[source]
Convert all data to
StationDataobjectsCreates one instance of
StationDatafor each metadata block in this object.- Parameters:
vars_to_convert (
listorstr, optional) – variables that are supposed to be converted. If None, use all variables that are available for this stationstart – start time, optional (if not None, input must be convertible into pandas.Timestamp)
stop – stop time, optional (if not None, input must be convertible into pandas.Timestamp)
freq (str) – pandas frequency string (e.g. ‘D’ for daily, ‘M’ for month end) or valid pyaerocom ts_type (e.g. ‘hourly’, ‘monthly’).
by_station_name (bool) – if True, then iter over unique_station_name (and merge multiple matches if applicable), else, iter over metadata index
**kwargs – additional keyword args passed to
to_station_data()(e.g. merge_if_multi, merge_pref_attr, merge_sort_by_largest, insert_nans)
- Returns:
5-element dictionary containing following key / value pairs:
stats: list of
StationDataobjectsstation_name: list of corresponding station names
station_type: list of corresponding station types, might be empty
latitude: list of latitude coordinates
longitude: list of longitude coordinates
- Return type:
Co-located data
- class pyaerocom.colocation.colocated_data.ColocatedData(data: Path | str | xr.DataArray | np.ndarray | None = None, **kwargs)[source]
Class representing colocated and unified data from two sources
Sources may be instances of
UngriddedDataorGriddedDatathat have been compared to each other.Note
It is intended that this object can either be instantiated from scratch OR created in and returned by pyaerocom objects / methods that perform colocation. This is particauarly true as pyaerocom will now be expected to read in colocated files created outside of pyaerocom. (Related CAMS2_82 development)
The purpose of this object is not the creation of colocated objects, but solely the analysis of such data as well as I/O features (e.g. save as / read from .nc files, convert to pandas.DataFrame, plot station time series overlays, scatter plots, etc.).
In the current design, such an object comprises 3 or 4 dimensions, where the first dimension (data_source, index 0) is ALWAYS length 2 and specifies the two datasets that were co-located (index 0 is obs, index 1 is model). The second dimension is time and in case of 3D colocated data the 3rd dimension is station_name while for 4D colocated data the 3rd and 4th dimension are latitude and longitude, respectively.
3D colocated data is typically created when a model is colocated with station based ground based observations ( cf
pyaerocom.colocation.colocate_gridded_ungridded()) while 4D colocated data is created when a model is colocated with another model or satellite observations, that cover large parts of Earth’s surface (other than discrete lat/lon pairs in the case of ground based station locations).- Parameters:
data (xarray.DataArray or numpy.ndarray or str, optional) – Colocated data. If str, then it is attempted to be loaded from file. Else, it is assumed that data is numpy array and that all further supplementary inputs (e.g. coords, dims) for the instantiation of
DataArrayis provided via **kwargs.**kwargs – Additional keyword args that are passed to init of
DataArrayin case input data is numpy array.
- Raises:
ValidationError – if init fails
- apply_country_filter(region_id, use_country_code=False, inplace=False)[source]
Apply country filter
- Parameters:
- Raises:
NotImplementedError – if data is 4D (i.e. it has latitude and longitude dimensions).
- Returns:
filtered data object.
- Return type:
- apply_latlon_filter(lat_range=None, lon_range=None, region_id=None, inplace=False)[source]
Apply rectangular latitude/longitude filter
- Parameters:
lat_range (list, optional) – latitude range that is supposed to be applied. If specified, then also lon_range need to be specified, else, region_id is checked against AeroCom default regions (and used if applicable)
lon_range (list, optional) – longitude range that is supposed to be applied. If specified, then also lat_range need to be specified, else, region_id is checked against AeroCom default regions (and used if applicable)
region_id (str) – name of region to be applied. If provided (i.e. not None) then input args lat_range and lon_range are ignored
inplace (bool, optional) – Apply filter to this object directly or to a copy. The default is False.
- Raises:
ValueError – if lower latitude bound exceeds upper latitude bound.
- Returns:
filtered data object
- Return type:
- apply_region_mask(region_id, inplace=False)[source]
Apply a binary regions mask filter to data object. Available binary regions IDs can be found at pyaerocom.const.HTAP_REGIONS.
- Parameters:
- Raises:
DataCoverageError – if filtering results in empty data object.
- Returns:
data – Filtered data object.
- Return type:
- property area_weights
Wrapper for
calc_area_weights()
- calc_area_weights()[source]
Calculate area weights
Note
Only applies to colocated data that has latitude and longitude dimension.
- Returns:
array containing weights for each datapoint (same shape as self.data[0])
- Return type:
ndarray
- calc_nmb_array()[source]
Calculate data array with normalised bias (NMB) values
- Returns:
NMBs at each coordinate
- Return type:
DataArray
- calc_spatial_statistics(aggr=None, use_area_weights=False, **kwargs)[source]
Calculate spatial statistics from model and obs data
Spatial statistics is computed by averaging first the time dimension and then, if data is 4D, flattening lat / lon dimensions into new station_name dimension, so that the resulting dimensions are data_source and station_name. These 2D data are then used to calculate standard statistics using
pyaerocom.stats.stats.calculate_statistics().See also
calc_statistics()andcalc_temporal_statistics().- Parameters:
aggr (str, optional) – aggregator to be used, currently only mean and median are supported. Defaults to mean.
use_area_weights (bool) – if True and if data is 4D (i.e. has lat and lon dimension), then area weights are applied when calculating the statistics based on the coordinate cell sizes. Defaults to False.
**kwargs – additional keyword args passed to
pyaerocom.stats.stats.calculate_statistics()
- Returns:
dictionary containing statistical parameters
- Return type:
- calc_statistics(use_area_weights=False, **kwargs)[source]
Calculate statistics from model and obs data
Calculate standard statistics for model assessment. This is done by taking all model and obs data points in this object as input for
pyaerocom.stats.stats.calculate_statistics(). For instance, if the object is 3D with dimensions data_source (obs, model), time (e.g. 12 monthly values) and station_name (e.g. 4 sites), then the input arrays for model and obs intopyaerocom.stats.stats.calculate_statistics()will be each of size 12x4.See also
calc_temporal_statistics()andcalc_spatial_statistics().- Parameters:
use_area_weights (bool) – if True and if data is 4D (i.e. has lat and lon dimension), then area weights are applied when calculating the statistics based on the coordinate cell sizes. Defaults to False.
**kwargs – additional keyword args passed to
pyaerocom.stats.stats.calculate_statistics()
- Returns:
dictionary containing statistical parameters
- Return type:
- calc_temporal_statistics(aggr=None, **kwargs)[source]
Calculate temporal statistics from model and obs data
Temporal statistics is computed by averaging first the spatial dimension(s) (that is, station_name for 3D data, and latitude and longitude for 4D data), so that only data_source and time remains as dimensions. These 2D data are then used to calculate standard statistics using
pyaerocom.stats.stats.calculate_statistics().See also
calc_statistics()andcalc_spatial_statistics().
- check_set_countries(assign_to_dim=None)[source]
Checks if country information is available and assigns if not.
If no country information is available, countries will be assigned for each lat/lon coordinate using
pyaerocom.geodesy.get_country_info_coords().- Parameters:
assign_to_dim (str, optional) – Name of dimension to which the country coordinate is assigned. Default is None, in which case ‘station_name’ is used.
- Returns:
self – This object with countries assigned (modified in place).
- Return type:
- property coords
Coordinates of data array
- property countries_available
Alphabetically sorted list of country names available
- Raises:
MetaDataError – if no country information is available
- Returns:
list of countries available in these data
- Return type:
- property country_codes_available
Alphabetically sorted list of country codes available
- Raises:
MetaDataError – if no country information is available
- Returns:
list of countries available in these data
- Return type:
- property data_source
Coordinate array containing data sources (z-axis)
- property dims
Names of dimensions
- filter_altitude(alt_range, inplace=False)[source]
Apply altitude filter
- Parameters:
- Raises:
NotImplementedError – If data is 4D, i.e. it contains latitude and longitude dimensions.
- Returns:
Filtered data object .
- Return type:
- filter_region(region_id, check_mask=True, check_country_meta=False, inplace=False)[source]
Filter object by region
- Parameters:
region_id (str) – ID of region
inplace (bool) – if True, the filtering is done directly in this instance, else a new instance is returned
check_mask (bool) – if True and region_id a valid name for a binary mask, then the filtering is done based on that binary mask.
check_country_meta (bool) – if True, then the input region_id is first checked against available country names in metadata. If that fails, it is assumed that this regions is either a valid name for registered rectangular regions or for available binary masks.
- Returns:
filtered data object
- Return type:
- flatten_latlondim_station_name()[source]
Stack (flatten) lat / lon dimension into new dimension station_name
- Returns:
new colocated data object with dimension station_name and lat lon arrays as additional coordinates
- Return type:
- static from_dataframe(df: DataFrame) ColocatedData[source]
Create colocated Data object from dataframe
Note
This is intended to be used as back-conversion from
to_dataframe()and methods that use the latter (e.g.to_csv()).
- get_coords_valid_obs()[source]
Get latitude / longitude coordinates where obsdata is available
- Returns:
list – latitude coordinates
list – longitude coordinates
- get_country_codes()[source]
Get country names and codes for all locations contained in these data
- Raises:
MetaDataError – if no country information is available
- Returns:
dictionary of unique country names (keys) and corresponding country codes (values)
- Return type:
- static get_meta_from_filename(file_path: str) dict[source]
Get meta information from file name
Note
This does not yet include IDs of model and obs data as these should be included in the data anyways (e.g. column names in CSV file) and may include the delimiter _ in their name.
- Returns:
dicitionary with meta information
- Return type:
- get_meta_item(key: str)[source]
Get metadata value
- Parameters:
key (str) – meta item key.
- Raises:
AttributeError – If key is not available.
- Returns:
value of metadata.
- Return type:
- get_regional_timeseries(region_id, **filter_kwargs)[source]
Compute regional timeseries both for model and obs
- Parameters:
region_id (str) – name of region for which regional timeseries is supposed to be retrieved
**filter_kwargs – additional keyword args passed to
filter_region().
- Returns:
dictionary containing regional timeseries for model (key mod) and obsdata (key obs) and name of region.
- Return type:
- get_time_resampling_settings()[source]
Returns a dictionary with relevant settings for temporal resampling
- Return type:
- property has_latlon_dims
Boolean specifying whether data has latitude and longitude dimensions
- property has_time_dim
Boolean specifying whether data has a time dimension
- property lat_range
Latitude range covered by this data object
- property latitude
Array of latitude coordinates
- property lon_range
Longitude range covered by this data object
- property longitude
Array of longitude coordinates
- max()[source]
Wrapper for
xarray.DataArray.max()called fromdata- Returns:
maximum of data
- Return type:
- property metadata
Meta data dictionary (wrapper to
data.attrs
- min()[source]
Wrapper for
xarray.DataArray.min()called fromdata- Returns:
minimum of data
- Return type:
- model_config: ClassVar[ConfigDict] = {'arbitrary_types_allowed': True, 'extra': 'allow', 'protected_namespaces': (), 'validate_assignment': True}
Configuration for the model, should be a dictionary conforming to [ConfigDict][pydantic.config.ConfigDict].
- property model_name
- property ndim
Dimension of data array
- property num_coords
Total number of lat/lon coordinate pairs
- property num_coords_with_data
Number of lat/lon coordinate pairs that contain at least one datapoint
Note
Occurrence of valid data is only checked for obsdata (first index in data_source dimension).
- property obs_name
- rename_variable(var_name, new_var_name, data_source, inplace=True)[source]
Rename a variable in this object
- Parameters:
- Returns:
instance with renamed variable
- Return type:
- Raises:
VarNotAvailableError – if input variable is not available in this object
DataSourceError – if input data_source is not available in this object
- resample_time(to_ts_type, how=None, min_num_obs=None, colocate_time=False, settings_from_meta=False, inplace=False, **kwargs)[source]
Resample time dimension
The temporal resampling is done using
TimeResampler- Parameters:
to_ts_type (str) – desired output frequency.
how (str or dict, optional) – aggregator used for resampling (e.g. max, min, mean, median). Can also be hierarchical scheme via dict, similar to min_num_obs. The default is None.
min_num_obs (int or dict, optional) – Minimum number of observations required to resample from current frequency (
ts_type) to desired output frequency.colocate_time (bool, optional) – If True, the modeldata is invalidated where obs is NaN, before resampling. The default is False (updated in v0.11.0, before was True).
settings_from_meta (bool) – if True, then input args how, min_num_obs and colocate_time are ignored and instead the corresponding values set in
metadataare used. Defaults to False.inplace (bool, optional) – If True, modify this object directly, else make a copy and resample that one. The default is False (updated in v0.11.0, before was True).
**kwargs – Additional keyword args passed to
TimeResampler.resample().
- Returns:
Resampled colocated data object.
- Return type:
- property savename_aerocom
Default save name for data object following AeroCom convention
- set_zeros_nan(inplace=True)[source]
Replace all 0’s with NaN in data
- Parameters:
inplace (bool) – Whether to modify this object or a copy. The default is True.
- Returns:
cd – modified data object
- Return type:
- property shape
Shape of data array
- stack(inplace=False, **kwargs)[source]
Stack one or more dimensions
For details see
xarray.DataArray.stack().- Parameters:
inplace (bool) – modify this object or a copy.
**kwargs – input arguments passed to
DataArray.stack()
- Returns:
stacked data object
- Return type:
- property start
Start datetime of data
- property stop
Stop datetime of data
- property time
Array containing time stamps
- to_csv(out_dir, savename=None)[source]
Save data object as .csv file
Converts data to pandas.DataFrame and then saves as csv
- Parameters:
out_dir (str) – output directory
savename (
str, optional) – name of file, if None, the default save name is used (cf.savename_aerocom)
- to_dataframe()[source]
Convert this object into pandas.DataFrame
The resulting DataFrame will have the following columns: station: The name of the station for a given value.
The following columns will be available in the resulting dataframe: - time: Time. - station_name: Station name. - data_source_obs: Data source obs (eg. EBASMC). - data_source_mod: Data source model (eg. EMEP). - latitude. - longitude. - altitude. - {var_name}_obs: Variable value of observation. - {var_name}_mod: Variable value of model.
{var_name} is the aerocom variable name of the variable name.
- to_netcdf(out_dir, savename=None, **kwargs)[source]
Save data object as NetCDF file
Wrapper for method
xarray.DataArray.to_netdcf()- Parameters:
out_dir (str) – output directory
savename (str, optional) – name of file, if None, the default save name is used (cf.
savename_aerocom)**kwargs – additional, optional keyword arguments passed to
xarray.DataArray.to_netdcf()
- Returns:
file path of stored object.
- Return type:
- property ts_type
String specifying temporal resolution of data
- property units
Unit of data
- property unitstr
String representation of obs and model units in this object
- unstack(inplace=False, **kwargs)[source]
Unstack one or more dimensions
For details see
xarray.DataArray.unstack().- Parameters:
inplace (bool) – modify this object or a copy.
**kwargs – input arguments passed to
DataArray.unstack()
- Returns:
unstacked data object
- Return type:
- property var_name
Coordinate array containing data sources (z-axis)
- pyaerocom.colocation.colocated_data.validate_dimensions(data: DataArray) None[source]
Ensure the dimensions on an xarray.DataArray passed to ColocatedData. If a ColocatedData object is created outside of pyaerocom, this checking is needed. This function is used as part of the model validator.
- pyaerocom.colocation.colocated_data.validate_structure(data: DataArray) None[source]
This check is supposed to be applied to a ColocatedData’s .data property as an additional check for validity. It is not currently part of the pydantic validation.
While passing this check does not guarantee a correct colocated data object it should give increased confidence.
Things to check (Not all implemented currently): - Object contains exactly one variable name recognized by pyaerocom. - Latitude and longitude exist and are named latitude and longitude. - Metadata (ie. netcdf attributes) contain the necessary metadata specified in the tutorial (https://pyaerocom.readthedocs.io/en/latest/pyaerocom-tutorials/making_a_colocated_data_object_with_pyaerocom.html). - No duplicate station names.
- Raises:
ValueError or KeyError – If Validation fails.
Station data
- class pyaerocom.stationdata.StationData(**meta_info)[source]
Dict-like base class for single station data
ToDo: write more detailed introduction
Note
Variable data (e.g. numpy array or pandas Series) can be directly assigned to the object. When assigning variable data it is recommended to add variable metadata (e.g. unit, ts_type) in
var_info, where key is variable name and value is dict with metadata entries.- data_err
dictionary that may be used to store uncertainty timeseries or data arrays associated with the different variable data.
- Type:
- overlap
dictionary that may be filled to store overlapping timeseries data associated with one variable. This is, for instance, used in
merge_vardata()to store overlapping data from another station.- Type:
- PROTECTED_KEYS = ['dtime', 'var_info', 'station_coords', 'data_err', 'overlap', 'numobs', 'data_flagged']
Keys that are ignored when accessing metadata
- STANDARD_COORD_KEYS = ['latitude', 'longitude', 'altitude']
List of keys that specify standard metadata attribute names. This is used e.g. in
get_meta()
- STANDARD_META_KEYS = ['filename', 'station_id', 'station_name', 'instrument_name', 'PI', 'country', 'country_code', 'ts_type', 'latitude', 'longitude', 'altitude', 'data_id', 'dataset_name', 'data_product', 'data_version', 'data_level', 'framework', 'instr_vert_loc', 'revision_date', 'website', 'ts_type_src', 'stat_merge_pref_attr']
- VALID_TS_TYPES = ('minutely', 'hourly', 'daily', 'weekly', 'monthly', 'yearly', 'native', 'coarsest')
- calc_climatology(var_name: str, start=None, stop=None, min_num_obs=None, clim_mincount=None, clim_freq=None, set_year=None, resample_how=None) StationData[source]
Calculate climatological timeseries for input variable
- Parameters:
var_name (str) – name of data variable
start – start time of data used to compute climatology
stop – start time of data used to compute climatology
min_num_obs (dict or int, optional) – minimum number of observations required per period (when downsampling). For details see
pyaerocom.time_resampler.TimeResampler.resample())clim_micount (int, optional) – minimum number of of monthly values required per month of climatology
set_year (int, optional) – if specified, the output data will be assigned the input year. Else the middle year of the climatological interval is used.
resample_how (str) – how should the resampled data be averaged (e.g. mean, median)
**kwargs – Additional keyword args passed to
pyaerocom.time_resampler.TimeResampler.resample()
- Returns:
new instance of StationData containing climatological data
- Return type:
- check_var_unit_aerocom(var_name: str)[source]
Check if unit of input variable is AeroCom default, if not, convert
- Parameters:
var_name (str) – name of variable
- Raises:
MetaDataError – if unit information is not accessible for input variable name
UnitConversionError – if current unit cannot be converted into specified unit (e.g. 1 vs m-1)
DataUnitError – if current unit is not equal to AeroCom default and cannot be converted.
- convert_unit(var_name: str, to_unit: str) None[source]
Try to convert unit of data
Requires that unit of input variable is available in
var_info- Parameters:
- Raises:
MetaDataError – if variable unit cannot be accessed
UnitConversionError – if conversion failed
- copy() StationData[source]
- property default_vert_grid
AeroCom default grid for vertical regridding
For details, see
DEFAULT_VERT_GRID_DEFinConfig- Returns:
numpy array specifying default coordinates
- Return type:
ndarray
- dist_other(other: StationData) float[source]
Distance to other station in km
- Parameters:
other (StationData) – other data object
- Returns:
distance between this and other station in km
- Return type:
- get_meta(force_single_value: bool = True, quality_check: bool = True, add_none_vals: bool = False, add_meta_keys: str | list[str] | None = None)[source]
Return meta-data as dictionary
By default, only default metadata keys are considered, use parameter add_meta_keys to add additional metadata.
- Parameters:
force_single_value (bool) – if True, then each meta value that is list or array,is converted to a single value.
quality_check (bool) – if True, and coordinate values are lists or arrays, then the standard deviation in the values is compared to the upper limits allowed in the local variation. The upper limits are specified in attr.
COORD_MAX_VAR.add_none_vals (bool) – Add metadata keys which have value set to None.
add_meta_keys (str or list, optional) – Add none-standard metadata.
- Returns:
dictionary containing the retrieved meta-data
- Return type:
- Raises:
AttributeError – if one of the meta entries is invalid
MetaDataError – in case of consistencies in meta data between individual time-stamps
- get_station_coords(force_single_value: bool = True) dict[str, float][source]
Return coordinates as dictionary
This method uses the standard coordinate names defined in
STANDARD_COORD_KEYS(latitude, longitude and altitude) to get the station coordinates. For each of these parameters tt first looks instation_coordsif the parameter is defined (i.e. it is not None) and if not it checks if this object has an attribute that has this name and uses that one.- Parameters:
force_single_value (bool) – if True and coordinate values are lists or arrays, then they are collapsed to single value using mean
- Returns:
dictionary containing the retrieved coordinates
- Return type:
- Raises:
AttributeError – if one of the coordinate values is invalid
CoordinateError – if local variation in either of the three spatial coordinates is found too large
- get_unit(var_name: str) str[source]
Get unit of variable data
- Parameters:
var_name (str) – name of variable
- Returns:
unit of variable
- Return type:
- Raises:
MetaDataError – if unit cannot be accessed for variable
- get_var_ts_type(var_name: str, try_infer: bool = True) TsType[source]
Get ts_type for a certain variable
Note
Converts to ts_type string if assigned ts_type is in pandas format
- Parameters:
- Returns:
the corresponding data time resolution
- Return type:
- Raises:
MetaDataError – if no metadata is available for this variable (e.g. if
var_namecannot be found invar_info)
- insert_nans_timeseries(var_name: str) StationData[source]
Fill up missing values with NaNs in an existing time series
Note
This method does a resample of the data onto a regular grid. Thus, if the input
ts_typeis different from the actual currentts_typeof the data, this method will not only insert NaNs but at the same.- Parameters:
var_name (str) – variable name
- Returns:
the modified station data object
- Return type:
- merge_meta_same_station(other: StationData, coord_tol_km: float | None = None, check_coords: bool = True, inplace: bool = True, add_meta_keys: str | list[str] | None = None, raise_on_error: bool = False) StationData[source]
Merge meta information from other object
Note
Coordinate attributes (latitude, longitude and altitude) are not copied as they are required to be the same in both stations. The latter can be checked and ensured using input argument
check_coords- Parameters:
other (StationData) – other data object
coord_tol_km (float) – maximum distance in km between coordinates of input StationData object and self. Only relevant if
check_coordsis True. If None, then_COORD_MAX_VARis used which is defined in the class header.check_coords (bool) – if True, the coordinates are compared and checked if they are lying within a certain distance to each other (cf.
coord_tol_km).inplace (bool) – if True, the metadata from the other station is added to the metadata of this station, else, a new station is returned with the merged attributes.
add_meta_keys (str or list, optional) – additional non-standard metadata keys that are supposed to be considered for merging.
raise_on_error (bool) – if True, then an Exception will be raised in case one of the metadata items cannot be merged, which is most often due to unresolvable type differences of metadata values between the two objects
- merge_other(other: StationData, var_name: str, add_meta_keys: str | list[str] | None = None, **kwargs) StationData[source]
Merge other station data object
- Parameters:
other (StationData) – other data object
var_name (str) – variable name for which info is to be merged (needs to be both available in this object and the provided other object)
add_meta_keys (str or list, optional) – additional non-standard metadata keys that are supposed to be considered for merging.
kwargs – keyword args passed on to
merge_vardata()(e.g time resampling settings)
- Returns:
this object that has merged the other station
- Return type:
- merge_vardata(other: StationData, var_name: str, **kwargs)[source]
Merge variable data from other object into this object
Note
This merges also the information about this variable in the dict
var_info. It is required, that variable meta-info is specified in both StationData objects.Note
This method removes NaN’s from the existing time series in the data objects. In order to fill up the time-series with NaNs again after merging, call
insert_nans_timeseries()- Parameters:
other (StationData) – other data object
var_name (str) – variable name for which info is to be merged (needs to be both available in this object and the provided other object)
kwargs – keyword args passed on to
_merge_vardata_2d()
- Returns:
this object merged with other object
- Return type:
- merge_varinfo(other: StationData, var_name: str) StationData[source]
Merge variable specific meta information from other object
- Parameters:
other (StationData) – other data object
var_name (str) – variable name for which info is to be merged (needs to be both available in this object and the provided other object)
- plot_timeseries(var_name: str, add_overlaps: bool = False, legend: bool = True, tit: str | None = None, **kwargs)[source]
Plot timeseries for variable
Note
If you set input arg
add_overlaps = Truethe overlapping timeseries data - if it exists - will be plotted on top of the actual timeseries using red colour and dashed line. As the overlapping data may be identical with the actual data, you might want to increase the line width of the actual timeseries using an additional input argumentlw=4, or similar.- Parameters:
- Returns:
matplotlib.axes instance of plot
- Return type:
axes
- Raises:
KeyError – if variable key does not exist in this dictionary
ValueError – if length of data array does not equal the length of the time array
- remove_outliers(var_name: str, low: float | None = None, high: float | None = None, unit_ref=None, check_unit: bool = True)[source]
Remove outliers from one of the variable timeseries
- Parameters:
var_name (str) – variable name
low (float) – lower end of valid range for input variable. If None, then the corresponding value from the default settings for this variable are used (cf. minimum attribute of available variables)
high (float) – upper end of valid range for input variable. If None, then the corresponding value from the default settings for this variable are used (cf. maximum attribute of available variables)
check_unit (bool) – if True, the unit of the data is checked against AeroCom default
- remove_variable(var_name: str)[source]
Remove variable data
- Parameters:
var_name (str) – name of variable that is to be removed
- Returns:
current instance of this object, with data removed
- Return type:
- Raises:
VarNotAvailableError – if the input variable is not available in this object
- resample_time(var_name: str, ts_type: str, how=None, min_num_obs=None, inplace=False, **kwargs)[source]
Resample one of the time-series in this object
- Parameters:
var_name (str) – name of data variable
ts_type (str) – new frequency string (can be pyaerocom ts_type or valid pandas frequency string)
how (str) – how should the resampled data be averaged (e.g. mean, median)
min_num_obs (dict or int, optional) – minimum number of observations required per period (when downsampling). For details see
pyaerocom.time_resampler.TimeResampler.resample())inplace (bool) – if True, then the current data object stored in self, will be overwritten with the resampled time-series
**kwargs – Additional keyword args passed to
pyaerocom.time_resampler.TimeResampler.resample()
- Returns:
with resampled variable timeseries
- Return type:
- resample_timeseries(var_name: str, **kwargs)[source]
Wrapper for
resample_time()(for backwards compatibility)Note
For backwards compatibility, this method will return a pandas Series instead of the actual StationData object
- same_coords(other: StationData, tol_km: float | None = None) bool[source]
Compare station coordinates of other station with this station
- Parameters:
other (StationData) – other data object
tol_km (float) – distance tolerance in km
- Returns:
if True, then the two object are located within the specified tolerance range
- Return type:
- select_altitude(var_name: str, altitudes: list) Series | DataArray[source]
Extract variable data within certain altitude range
Note
Beta version
- Parameters:
- Returns:
data object within input altitude range
- Return type:
pandas. Series or xarray.DataArray
- to_timeseries(var_name: str, **kwargs) Series[source]
Get pandas.Series object for one of the data columns
- Parameters:
var_name (str) – name of variable (e.g. “od550aer”)
- Returns:
time series object
- Return type:
Series
- Raises:
KeyError – if variable key does not exist in this dictionary
ValueError – if length of data array does not equal the length of the time array
- property vars_available
Number of variables available in this data object
Other data classes
- class pyaerocom.vertical_profile.VerticalProfile(data: _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | bool | int | float | complex | str | bytes | _NestedSequence[bool | int | float | complex | str | bytes], altitude: _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | bool | int | float | complex | str | bytes | _NestedSequence[bool | int | float | complex | str | bytes], dtime, var_name: str, data_err: _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | bool | int | float | complex | str | bytes | _NestedSequence[bool | int | float | complex | str | bytes] | None, var_unit: str, altitude_unit: str)[source]
Object representing single variable profile data
- property altitude
Array containing altitude values corresponding to data
- property data
Array containing data values corresponding to data
- property data_err
Array containing data values corresponding to data
Co-location routines
High-level co-location engine
Classes and methods to perform high-level colocation.
- class pyaerocom.colocation.colocator.Colocator(colocation_setup: ColocationSetup | dict, **kwargs)[source]
High level class for running co-location
Note
This object requires and instance from
ColocationSetup.- get_model_name()[source]
Get name of model
Note
Not to be confused with
model_idwhich is always the database ID of the model, while model_name can differ from that and is used for output files, etc.- Raises:
AttributeError – If neither model_id or model_name are set
- Returns:
preferably
model_name, elsemodel_id- Return type:
- get_nc_files_in_coldatadir()[source]
Get list of NetCDF files in colocated data directory
- Returns:
list of NetCDF file paths found
- Return type:
- get_obs_name()[source]
Get name of obsdata source
Note
Not to be confused with
obs_idwhich is always the database ID of the observation dataset, while obs_name can differ from that and is used for output files, etc.- Raises:
AttributeError – If neither obs_id or obs_name are set
- Returns:
preferably
obs_name, elseobs_id- Return type:
- property model_reader
Model data reader
- property model_readers
Model data readers
- property model_vars
List of all model variables specified in config
Note
This method does not check if the variables are valid or available.
- Returns:
list of all model variables specified in this setup.
- Return type:
- property obs_reader
Observation data reader
- prepare_run(var_list: list[str] | None = None) dict[str, str][source]
Prepare colocation run for current setup.
- Parameters:
var_name (str, optional) – Variable name that is supposed to be analysed. The default is None, in which case all defined variables are attempted to be colocated.
- Raises:
AttributeError – If no observation variables are defined (
obs_varsempty).- Returns:
vars_to_process – Mapping of variables to be processed, keys are model vars, values are obs vars.
- Return type:
- run(var_list: list[str] | None = None)[source]
Perform colocation for current setup
See also
prepare_run().- Parameters:
var_list (list, optional) – list of variables supposed to be analysed. The default is None, in which case all defined variables are attempted to be colocated.
- Returns:
nested dictionary, where keys are model variables, values are dictionaries comprising key / value pairs of obs variables and associated instances of
ColocatedData.- Return type:
- class pyaerocom.colocation.colocation_setup.ColocationSetup(model_id: str | None = None, pyaro_config: PyaroConfig | None = None, obs_id: str | None = None, obs_vars: tuple[str, ...] | None = (), ts_type: str = 'monthly', start: Timestamp | int | None = None, stop: Timestamp | int | None = None, basedir_coldata: str = '/home/docs/MyPyaerocom/colocated_data', save_coldata: bool = False, *, OBS_VERT_TYPES_ALT: dict[str, str] = {'2D': '2D', 'Surface': 'ModelLevel'}, CRASH_ON_INVALID: bool = False, FORBIDDEN_KEYS: list[str] = ['var_outlier_ranges', 'var_ref_outlier_ranges', 'remove_outliers'], filter_name: str = 'ALL-wMOUNTAINS', obs_name: str | None = None, obs_data_dir: Path | str | None = None, obs_use_climatology: ClimatologyConfig | bool = False, obs_cache_only: bool = False, obs_vert_type: str | None = None, obs_ts_type_read: str | dict | None = None, obs_filters: dict = {}, colocation_layer_limits: tuple[LayerLimits, ...] | None = None, profile_layer_limits: tuple[LayerLimits, ...] | None = None, read_opts_ungridded: dict | None = {}, model_name: str | None = None, model_data_dir: Path | str | list[str] | list[Path] | None = None, model_read_opts: dict = {}, model_use_vars: dict[str, str] = {}, model_rename_vars: dict[str, str] | None = {}, model_add_vars: dict[str, tuple[str, ...]] = {}, model_to_stp: bool = False, model_ts_type_read: str | dict | None = None, model_read_aux: dict[str, dict[Literal['vars_required', 'fun'], list[str] | Callable]] | None = {}, model_use_climatology: bool = False, gridded_reader_id: dict[str, str] = {'model': 'ReadGridded', 'obs': 'ReadGridded'}, flex_ts_type: bool = True, min_num_obs: dict | int | None = None, resample_how: str | dict | None = 'mean', obs_remove_outliers: bool = False, model_remove_outliers: bool = False, obs_outlier_ranges: dict[str, tuple[float, float]] | None = {}, model_outlier_ranges: dict[str, tuple[float, float]] | None = {}, zeros_to_nan: bool = False, harmonise_units: bool = False, regrid_res_deg: float | RegridResDeg | None = None, colocate_time: bool = False, reanalyse_existing: bool = True, raise_exceptions: bool = False, keep_data: bool = True, add_meta: dict | None = {}, model_kwargs: dict = {}, main_freq: str = 'monthly', freqs: list[str] = ['monthly', 'yearly'])[source]
Setup class for high-level model / obs co-location.
An instance of this setup class can be used to run a colocation analysis between a model and an observation network and will create a number of
pya.ColocatedDatainstances, which can be saved automatically as NetCDF files.Apart from co-location, this class also handles reading of the input data for co-location. Supported co-location options are:
1. gridded vs. ungridded data For instance 3D model data (instance of
GriddedData) with lat, lon and time dimension that is co-located with station based observations which are represented in pyaerocom throughUngriddedDataobjects. The co-location function used ispyaerocom.colocation.colocated_gridded_ungridded(). For this type of co-location, the output co-located data object will be 3-dimensional, with dimensions data_source (index 0: obs, index 1: model), time and station_name.2. gridded vs. gridded data For instance 3D model data that is co-located with 3D satellite data (both instances of
GriddedData), both objects with lat, lon and time dimensions. The co-location function used ispyaerocom.colocation.colocated_gridded_gridded(). For this type of co-location, the output co-located data object will be 4-dimensional, with dimensions data_source (index 0: obs, index 1: model), time and latitude and longitude.- pyaro_config
In the case Pyaro is used, a config must be provided. In that case obs_id(see below) is ignored and only the config is used.
- Type:
PyaroConfig
- obs_vars
Variables to be analysed (need to be available in input obs dataset). Variables that are not available in the model data output will be skipped. Alternatively, model variables to be used for a given obs variable can also be specified via attributes
model_use_varsandmodel_add_vars.
- start
Start time of colocation. Input can be integer denoting the year or anything that can be converted into
pandas.Timestampusingpyaerocom.helpers.to_pandas_timestamp(). If None, than the first available date in the model data is used.
- stop
stop time of colocation. int or anything that can be converted into
pandas.Timestampusingpyaerocom.helpers.to_pandas_timestamp()or None. If None and ifstartis on resolution of year (e.g.start=2010) thenstopwill be automatically set to the end of that year. Else, it will be set to the last available timestamp in the model data.
- filter_name
name of filter to be applied. If None, no filter is used (to be precise, if None, then
pyaerocom.const.DEFAULT_REG_FILTERis used which should default to ALL-wMOUNTAINS, that is, no filtering).- Type:
- obs_name
if provided, this string will be used in colocated data filename to specify obsnetwork, else obs_id will be used.
- Type:
str, optional
- obs_data_dir
location of obs data. If None, attempt to infer obs location based on obs ID.
- Type:
str, optional
- obs_use_climatology
Configuration for climatology. If True is given, a default configuration is made. With False, climatology is turned off
- Type:
ClimatologyConfig | bool, optional
- obs_vert_type
AeroCom vertical code encoded in the model filenames (only AeroCom 3 and later). Specifies which model file should be read in case there are multiple options (e.g. surface level data can be read from a Surface.nc file as well as from a ModelLevel.nc file). If input is string (e.g. ‘Surface’), then the corresponding vertical type code is used for reading of all variables that are colocated (i.e. that are specified in
obs_vars).- Type:
- obs_ts_type_read
may be specified to explicitly define the reading frequency of the observation data (so far, this does only apply to gridded obsdata such as satellites), either as str (same for all obs variables) or variable specific as dict. For ungridded reading, the frequency may be specified via
obs_id, where applicable (e.g. AeronetSunV3Lev2.daily). Not to be confused withts_type, which specifies the frequency used for colocation. Can be specified variable specific in form of dictionary.
- obs_filters
filters applied to the observational dataset before co-location. In case of gridded / gridded, these are filters that can be passed to
pyaerocom.io.ReadGridded.read_var(), for instance, flex_ts_type, or constraints. In case the obsdata is ungridded (gridded / ungridded co-locations) these are filters that are handled through keyword filter_post inpyaerocom.io.ReadUngridded.read(). These filters are applied to theUngriddedDataobjects after reading and caching the data, so changing them, will not invalidate the latest cache of theUngriddedData.- Type:
- read_opts_ungridded
dictionary that specifies reading constraints for ungridded reading, and are passed as **kwargs to
pyaerocom.io.ReadUngridded.read(). Note that - other than for obs_filters these filters are applied during the reading of theUngriddedDataobjects and specifying them will deactivate caching.- Type:
dict, optional
- model_name
if provided, this string will be used in colocated data filename to specify model, else obs_id will be used.
- Type:
str, optional
- model_data_dir
Location of model data. If None, attempt to infer model location based on model ID.
- Type:
str, optional
- model_read_opts
options for model reading (passed as keyword args to
pyaerocom.io.ReadUngridded.read()).- Type:
dict, optional
- model_use_vars
dictionary that specifies mapping of model variables. Keys are observation variables, values are the corresponding model variables (e.g. model_use_vars=dict(od550aer=’od550csaer’)). Example: your observation has var od550aer but your model model uses a different variable name for that variable, say od550. Then, you can specify this via model_use_vars = {‘od550aer’ : ‘od550’}. NOTE: in this case, a model variable od550aer will be ignored, even if it exists (cf
model_add_vars).- Type:
dict, optional
- model_rename_vars
rename certain model variables after co-location, before storing the associated
ColocatedDataobject on disk. Keys are model variables, values are new names (e.g. model_rename_vars={‘od550aer’:’MyAOD’}). Note: this does not impact which variables are read from the model.- Type:
dict, optional
- model_add_vars
additional model variables to be processed for one obs variable. E.g. model_add_vars={‘od550aer’: [‘od550so4’, ‘od550gt1aer’]} would co-locate both model SO4 AOD (od550so4) and model coarse mode AOD (od550gt1aer) with total AOD (od550aer) from obs (in addition to od550aer vs od550aer if applicable).
- Type:
dict, optional
- model_to_stp
ALPHA (please do not use): convert model data values to STP conditions after co-location. Note: this only works for very particular settings at the moment and needs revision, as it relies on access to meteorological data.
- Type:
- model_ts_type_read
may be specified to explicitly define the reading frequency of the model data, either as str (same for all obs variables) or variable specific as dict. Not to be confused with
ts_type, which specifies the output frequency of the co-located data.
- model_read_aux
may be used to specify additional computation methods of variables from models. Keys are variables to be computed, values are dictionaries with keys vars_required (list of required variables for computation of var and fun (method that takes list of read data objects and computes and returns var).
- Type:
dict, optional
- model_use_climatology
if True, attempt to use climatological model data field. Note: this only works if model data is in AeroCom conventions (climatological fields are indicated with 9999 as year in the filename) and if this is active, only single year analysis are supported (i.e. provide int to
startto specify the year and leavestopempty).- Type:
- model_kwargs
Key word arguments to be given to the model reader class’s read_var and init function
- Type:
- gridded_reader_id
BETA: dictionary specifying which gridded reader is supposed to be used for model (and gridded obs) reading. Note: this is a workaround solution and will likely be removed in the future when the gridded reading API is more harmonised (see https://github.com/metno/pyaerocom/issues/174).
- Type:
- flex_ts_type
Boolean specifying whether reading frequency of gridded data is allowed to be flexible. This includes all gridded data, whether it is model or gridded observation (e.g. satellites). Defaults to True.
- Type:
- min_num_obs
time resampling constraints applied, defaults to None, in which case no constraints are applied. For instance, say your input is in daily resolution and you want output in monthly and you want to make sure to have roughly 50% daily coverage for the monthly averages. Then you may specify min_num_obs=15 which will ensure that at least 15 daily averages are available to compute a monthly average. However, you may also define a hierarchical scheme that first goes from daily to weekly and then from weekly to monthly, via a dict. E.g. min_num_obs=dict(monthly=dict(weekly=4), weekly=dict(daily=3)) would ensure that each week has at least 3 daily values, as well as that each month has at least 4 weekly values.
- resample_how
string specifying how data should be aggregated when resampling in time. Default is “mean”. Can also be a nested dictionary, e.g. resample_how={‘conco3’: ‘daily’: {‘hourly’ : ‘max’}} would use the maximum value to aggregate from hourly to daily for variable conco3, rather than the mean.
- obs_remove_outliers
if True, outliers are removed from obs data before colocation, else not. Default is False. Custom outlier ranges for each variable can be specified via
obs_outlier_ranges, and for all other variables, the pyaerocom default outlier ranges are used. The latter are specified in variables.ini file via minimum and maximum attributes and can also be accessed throughpyaerocom.variable.Variable.minimumandpyaerocom.variable.Variable.maximum, respectively.- Type:
- model_remove_outliers
if True, outliers are removed from model data (normally this should be set to False, as the models are supposed to be assessed, including outlier cases). Default is False. Custom outlier ranges for each variable can be specified via
model_outlier_ranges, and for all other variables, the pyaerocom default outlier ranges are used. The latter are specified in variables.ini file via minimum and maximum attributes and can also be accessed throughpyaerocom.variable.Variable.minimumandpyaerocom.variable.Variable.maximum, respectively.- Type:
- obs_outlier_ranges
dictionary specifying outlier ranges for individual obs variables. (e.g. dict(od550aer = [-0.05, 10], ang4487aer=[0,4])). Only relevant if
obs_remove_outliersis True.- Type:
dict, optional
- model_outlier_ranges
like
obs_outlier_rangesbut for model variables. Only relevant ifmodel_remove_outliersis True.- Type:
dict, optional
- zeros_to_nan
If True, zero’s in output co-located data object will be converted to NaN. Default is False.
- Type:
- harmonise_units
if True, units are attempted to be harmonised during co-location (note: raises Exception if True and in case units cannot be harmonised).
- Type:
- regrid_res_deg
regrid resolution in degrees. If specified, the input gridded data objects will be regridded in lon / lat dimension to the input resolution (if input is float, both lat and lon are regridded to that resolution, if input is dict, use keys lat_res_deg and lon_res_deg to specify regrid resolutions, respectively). Default is None.
- colocate_time
if True and if obs and model sampling frequency (e.g. daily) are higher than output colocation frequency (e.g. monthly), then the datasets are first colocated in time (e.g. on a daily basis), before the monthly averages are calculated. Default is False. NOTE: If there are missing data in the model, having this true will interpolate the missing model data!
- Type:
- reanalyse_existing
if True, always redo co-location, even if there is already an existing co-located NetCDF file (under the output location specified by
basedir_coldata) for the given variable combination to be co-located. If False and output already exists, then co-location is skipped for the associated variable. This flag is also used for contour-plots. Default is True.- Type:
- raise_exceptions
if True, Exceptions that may occur for individual variables to be processed, are raised, else the analysis is skipped for such cases.
- Type:
- keep_data
if True, then all colocated data objects computed when running
run()will be stored indata. Defaults to True.- Type:
- add_meta
additional metadata that is supposed to be added to each output
ColocatedDataobject.- Type:
- main_freq
Main output frequency for AeroVal (some of the AeroVal processing steps are only done for this resolution, since they would create too much output otherwise, such as statistics timeseries or scatter plot in “Overall Evaluation” tab on AeroVal). Note that this frequency needs to be included in next setting “freqs”.
- Type:
- CRASH_ON_INVALID: bool
do not raise Exception if invalid item is attempted to be assigned (Overwritten from base class)
- OBS_VERT_TYPES_ALT: dict[str, str]
Dictionary specifying alternative vertical types that may be used to read model data. E.g. consider the variable is ec550aer, obs_vert_type=’Surface’ and obs_vert_type_alt=dict(Surface=’ModelLevel’). Now, if a model that is used for the analysis does not contain a data file for ec550aer at the surface (’ec550aer*Surface.nc’), then, the colocation routine will look for ‘ec550aer*ModelLevel.nc’ and if this exists, it will load it and extract the surface level.
- add_glob_meta(**kwargs)[source]
Add global metadata to
add_meta- Parameters:
kwargs – metadata to be added
- Return type:
None
- model_config: ClassVar[ConfigDict] = {'allow': 'extra', 'arbitrary_types_allowed': True, 'protected_namespaces': ()}
Configuration for the model, should be a dictionary conforming to [ConfigDict][pydantic.config.ConfigDict].
- validate_profile_and_colocation_layer_limits()[source]
Validate that colocation_layer_limits and profile_layer_limits are set correctly. If colocation_layer_limits is set, profile_layer_limits must also be set. If profile_layer_limits is set, colocation_layer_limits must also be set. Additionally, neither of these values can match.
TODO: Implement saving of the colocated data files such that this validation is not needed anymore. The issue to get around is that we save the colocated data objects per layer in the same directory. Only after they are read in is the boolean just_for_viz checked, which is used to determine whether to compute the full range of statistics on the colocated data or not. Hence, if the colocation_layer_limits and profile_layer_limits are the same, then one of the saved colocated data objects gets over written. This is not a problem if the colocation_layer_limits and profile_layer_limits are different, as then the saved colocated data objects are distinct.
- class pyaerocom.colocation.uemep.colocator.UEMEPColocator(uemep_station_data: PathLike | str | list[PathLike | str], *, obs: dict[str, str] | list[str], var_names: str | list[str] | None = None, out_dir: PathLike | None = None)[source]
Helper class for colcating uEMEP station data with observation data.
Limitations:
Only colocates hourly model data with hourly obs data. No temporal
resampling occurs. - Only works for EBAS data currently.
:param uemep_station_data : Path to folder containing uemep_station_data, or list of files. Files must be readable using xarray’s open_mfdataset(). :param obs : dict or list with observations to be colocated against. If list, must be data_ids understood by ReadUngridded. If dict, must be a mapping from identifier to data_id understood by ReadUngridded. The identifier can be chosen freely and is only used for metadata (which is shown on Aeroval). :var_names : A list of variables. If not provided, all variables defined in uemep_variables.toml will be tried. :out_dir : Directory where colocated data objects will be written. Note that output will be one file per variable/observation combination. Variables will be stored as files following aerocom convention.
Low-level co-location functions
Methods and / or classes to perform colocation
- pyaerocom.colocation.colocation_utils.colocate_gridded_gridded(data, data_ref, ts_type=None, start=None, stop=None, filter_name=None, regrid_res_deg: float | RegridResDeg | None = None, regrid_scheme: str = 'areaweighted', update_baseyear_gridded=None, min_num_obs=None, colocate_time=False, resample_how=None, **kwargs)[source]
Colocate 2 gridded data objects
- Parameters:
data (GriddedData) – gridded data (e.g. model results)
data_ref (GriddedData) – reference data (e.g. gridded satellite object) that is co-located with data. observation data or other model)
ts_type (str, optional) – desired temporal resolution of output colocated data (e.g. “monthly”). Defaults to None, in which case the highest possible resolution is used.
start (str or datetime64 or similar, optional) – start time for colocation, if None, the start time of the input
GriddedDataobject is usedstop (str or datetime64 or similar, optional) – stop time for colocation, if None, the stop time of the input
GriddedDataobject is usedfilter_name (str, optional) – string specifying filter used (cf.
pyaerocom.filter.Filterfor details). If None, then it is set to ‘ALL-wMOUNTAINS’, which corresponds to no filtering (world with mountains). Use ALL-noMOUNTAINS to exclude mountain sites.regrid_res_deg (int or dict, optional) – regrid resolution in degrees. If specified, the input gridded data objects will be regridded in lon / lat dimension to the input resolution (if input is integer, both lat and lon are regridded to that resolution, if input is dict, use keys lat_res_deg and lon_res_deg to specify regrid resolutions, respectively).
regrid_scheme (str) – iris scheme used for regridding (defaults to area weighted regridding)
update_baseyear_gridded (int, optional) – optional input that can be set in order to redefine the time dimension in the first gridded data object `data`to be analysed. E.g., if the data object is a climatology (one year of data) that has set the base year of the time dimension to a value other than the specified input start / stop time this may be used to update the time in order to make co-location possible.
min_num_obs (int or dict, optional) – minimum number of observations for resampling of time
colocate_time (bool) – if True and if original time resolution of data is higher than desired time resolution (ts_type), then both datasets are colocated in time before resampling to lower resolution. NOTE: If there are missing data in the model, having this true will interpolate the missing model data!
resample_how (str or dict) – string specifying how data should be aggregated when resampling in time. Default is “mean”. Can also be a nested dictionary, e.g. resample_how={‘daily’: {‘hourly’ : ‘max’}} would use the maximum value to aggregate from hourly to daily, rather than the mean.
**kwargs – additional keyword args (not used here, but included such that factory class can handle different methods with different inputs)
- Returns:
instance of colocated data
- Return type:
- pyaerocom.colocation.colocation_utils.colocate_gridded_ungridded(data: GriddedDataContainer, data_ref: UngriddedDataContainer, ts_type=None, start=None, stop=None, filter_name=None, regrid_res_deg: float | RegridResDeg | None = None, regrid_scheme: str = 'areaweighted', var_ref=None, update_baseyear_gridded=None, min_num_obs=None, colocate_time=False, use_climatology_ref=False, resample_how=None, **kwargs)[source]
Colocate gridded with ungridded data (low level method)
For high-level colocation see
pyaerocom.colocation.Colocatorandpyaerocom.ColocationSetupNote
Uses the variable that is contained in input
GriddedDataobject (since these objects only contain a single variable). If this variable is not contained in observation data (or contained but using a different variable name) you may specify the obs variable to be used via input arg var_ref- Parameters:
data (GriddedData) – gridded data object (e.g. model results).
data_ref (UngriddedDataContainer) – ungridded data object (e.g. observations).
ts_type (str) – desired temporal resolution of colocated data (must be valid AeroCom ts_type str such as daily, monthly, yearly.).
start (
strordatetime64or similar, optional) – start time for colocation, if None, the start time of the inputGriddedDataobject is used.stop (
strordatetime64or similar, optional) – stop time for colocation, if None, the stop time of the inputGriddedDataobject is usedfilter_name (str) – string specifying filter used (cf.
pyaerocom.filter.Filterfor details). If None, then it is set to ‘ALL-wMOUNTAINS’, which corresponds to no filtering (world with mountains). Use ALL-noMOUNTAINS to exclude mountain sites.regrid_res_deg (int or dict, optional) – regrid resolution in degrees. If specified, the input gridded data object will be regridded in lon / lat dimension to the input resolution (if input is integer, both lat and lon are regridded to that resolution, if input is dict, use keys lat_res_deg and lon_res_deg to specify regrid resolutions, respectively).
var_ref (
str, optional) – variable against which data in arg data is supposed to be compared. If None, then the same variable is used (i.e. data.var_name).update_baseyear_gridded (int, optional) – optional input that can be set in order to re-define the time dimension in the gridded data object to be analysed. E.g., if the data object is a climatology (one year of data) that has set the base year of the time dimension to a value other than the specified input start / stop time this may be used to update the time in order to make colocation possible.
min_num_obs (int or dict, optional) – minimum number of observations for resampling of time
colocate_time (bool) – if True and if original time resolution of data is higher than desired time resolution (ts_type), then both datasets are colocated in time before resampling to lower resolution. NOTE: If there are missing data in the model, having this true will interpolate the missing model data!
use_climatology_ref (ClimateConfig | bool, optional.) – Configuration for calculating the climatology. If set to a bool, this will not be done
resample_how (str or dict) – string specifying how data should be aggregated when resampling in time. Default is “mean”. Can also be a nested dictionary, e.g. resample_how={‘daily’: {‘hourly’ : ‘max’}} would use the maximum value to aggregate from hourly to daily, rather than the mean.
**kwargs – additional keyword args (passed to
UngriddedData.to_station_data_all())
- Returns:
instance of colocated data
- Return type:
- Raises:
VarNotAvailableError – if grid data variable is not available in ungridded data object
AttributeError – if instance of input
UngriddedDataContainerobject contains more than one datasetTimeMatchError – if gridded data time range does not overlap with input time range
ColocationError – if none of the data points in input
UngriddedDataContainermatches the input colocation constraints
- pyaerocom.colocation.colocation_utils.correct_model_stp_coldata(coldata, p0=None, t0=273.15, inplace=False)[source]
Correct modeldata in colocated data object to STP conditions
Note
BETA version, quite unelegant coded (at 8pm 3 weeks before IPCC deadline), but should do the job for 2010 monthly colocated data files (AND NOTHING ELSE)!
- pyaerocom.colocation.colocation_utils.resolve_var_name(data: GriddedData) tuple[str, str][source]
Check variable name of GriddedData against AeroCom default
Checks whether the variable name set in the data corresponds to the AeroCom variable name, or whether it is an alias. Returns both the variable name set and the AeroCom variable name.
- Parameters:
data (GriddedData) – Data to be checked.
- Returns:
str – variable name as set in data (may be alias, but may also be AeroCom variable name, in which case first and second return parameter are the same).
str – corresponding AeroCom variable name
Methods and / or classes to perform 3D colocation
- class pyaerocom.colocation.colocation_3d.ColocatedDataLists(colocateddata_for_statistics, colocateddata_for_profile_viz)[source]
- colocateddata_for_profile_viz: list[ColocatedData]
Alias for field number 1
- colocateddata_for_statistics: list[ColocatedData]
Alias for field number 0
- pyaerocom.colocation.colocation_3d.colocate_vertical_profile_gridded(data, data_ref, ts_type: str | None = None, start: str | None = None, stop: str | None = None, filter_name: str | None = None, regrid_res_deg: float | RegridResDeg | None = None, harmonise_units: bool = True, regrid_scheme: str = 'areaweighted', var_ref: str | None = None, update_baseyear_gridded: int | None = None, min_num_obs: int | dict | None = None, colocate_time: bool = False, use_climatology_ref: dict = False, resample_how: str | dict | None = None, colocation_layer_limits: tuple[LayerLimits, ...] | None = None, profile_layer_limits: tuple[LayerLimits, ...] | None = None, **kwargs) ColocatedDataLists[source]
Colocated vertical profile data with gridded (model) data
The guts of this function are placed in a helper function as not to repeat the code. This is done because colocation must occur twice:
at the the statistics are computed
at a finer vertical resolution for profile visualization
Some things you do not want to compute twice, however. So (most of) the things that correspond to both colocation instances are computed here, and then passed to the helper function.
- Returns
colocated_data_lists : ColocatedDataLists
Co-locating ungridded observations
- pyaerocom.combine_vardata_ungridded.combine_vardata_ungridded(data_ids_and_vars, match_stats_how='closest', match_stats_tol_km=1, merge_how='combine', merge_eval_fun=None, var_name_out=None, data_id_out=None, var_unit_out=None, resample_how=None, min_num_obs=None, add_meta_keys=None)[source]
Combine and colocate different variables from UngriddedData
This method allows to combine different variable timeseries from different ungridded observation records in multiple ways. The source data may be all included in a single instance of UngriddedData or in multiple, for details see first input parameter :param:`data_ids_and_vars`. Merging can be done in flexible ways, e.g. by combining measurements of the same variable from 2 different datasets or by computing new variables based on 2 measured variables (e.g. concox=concno2+conco3). Doing this requires colocation of site locations and timestamps of both input observation records, which is done in this method.
It comprises 2 major steps:
- Compute list of
StationDataobjects for both input data combinations (data_id1 & var1; data_id2 & var2) and based on these, find the coincident locations. Finding coincident sites can either be done based on site location name or based on their lat/lon locations. The method to use can be specified via input arg :param:`match_stats_how`.
- Compute list of
- For all coincident locations, a new instance of
StationDatais computed that has merged the 2 timeseries in the way that can be specified through input args :param:`merge_how` and :param:`merge_eval_fun`. If the 2 original timeseries from both sites come in different temporal resolutions, they will be resampled to the lower of both resolutions. Resampling constraints that are supposed to be applied in that case can be provided via the respective input args for temporal resampling. Default is pyaerocom default, which corresponds to ~25% coverage constraint (as of 22.10.2020) for major resolution steps, such as daily->monthly.
- For all coincident locations, a new instance of
Note
Currently, only 2 variables can be combined to a new one (e.g. concox=conco3+concno2).
Note
Be aware of unit conversion issues that may arise if your input data is not in AeroCom default units. For details see below.
- Parameters:
data_ids_and_vars (list) – list of 3 element tuples, each containing, in the following order 1. instance of
UngriddedData; 2. dataset ID (remember that UngriddedData can contain more than one dataset); and 3. variable name. Note that currently only 2 of such tuples can be combined.match_stats_how (str, optional) – String specifying how site locations are supposed to be matched. The default is ‘closest’. Supported are ‘closest’ and ‘station_name’.
match_stats_tol_km (float, optional) – radius tolerance in km for matching site locations when using ‘closest’ for site location matching. The default is 1.
merge_how (str, optional) – String specifying how to merge variable data at site locations. The default is ‘combine’. If both input variables are the same and combine is used, then the first input variable will be preferred over the other. Supported are ‘combine’, ‘mean’ and ‘eval’, for the latter, merge_eval_fun needs to be specified explicitly.
merge_eval_fun (str, optional) – String specifying how var1 and var2 data should be evaluated (only relevant if merge_how=’eval’ is used) . The default is None. E.g. if one wants to retrieve the column aerosol fine mode fraction at 550nm (fmf550aer) through AERONET, this could be done through the SDA product by prodiding data_id1 and var1 are ‘AeronetSDA’ and ‘od550aer’ and second input data_id2 and var2 are ‘AeronetSDA’ and ‘od550lt1aer’ and merge_eval_fun could then be ‘fmf550aer=(AeronetSDA;od550lt1aer/AeronetSDA;od550aer)*100’. Note that the input variables will be converted to their AeroCom default units, so the specification of merge_eval_fun should take that into account in case the originally read obsdata is not in default units.
var_name_out (str, optional) – Name of output variable. Default is None, in which case it is attempted to be inferred.
data_id_out (str, optional) – data_id set in output StationData objects. Default is None, in which case it is inferred from input data_ids (e.g. in above example of merge_eval_fun, the output data_id would be ‘AeronetSDA’ since both input IDs are the same.
var_unit_out (str) – unit of output variable.
resample_how (str, optional) – String specifying how temporal resampling should be done. The default is ‘mean’.
min_num_obs (int or dict, optional) – Minimum number of observations for temporal resampling. The default is None in which case pyaerocom default is used, which is available via pyaerocom.const.OBS_MIN_NUM_RESAMPLE.
add_meta_keys (list, optional) – additional metadata keys to be added to output StationData objects from input data. If None, then only the pyaerocom default keys are added (see StationData.STANDARD_META_KEYS).
- Raises:
ValueError – If input for merge_how or match_stats_how is invalid.
NotImplementedError – If one of the input UngriddedData objects contains more than one dataset.
- Returns:
merged_stats – list of StationData objects containing the colocated and combined variable data.
- Return type:
Reading of gridded data
Gridded data specifies any dataset that can be represented and stored on a
regular grid within a certain domain (e.g. lat, lon time), for instance, model
output or level 3 satellite data, stored, for instance, as NetCDF files.
In pyaerocom, the underlying data object is GriddedData and
pyaerocom supports reading of such data for different file naming conventions.
Gridded data using AeroCom conventions
- class pyaerocom.io.readgridded.ReadGridded(data_id=None, data_dir=None, file_convention='aerocom3')[source]
Class for reading gridded files using AeroCom file conventions
- data_id
string ID for model or obsdata network (see e.g. Aerocom interface map plots lower left corner)
- Type:
- data
imported data object
- Type:
- start
start time for data import
- Type:
- stop
stop time for data import
- Type:
- file_convention
class specifying details of the file naming convention for the model
- Type:
FileConventionRead
- files
list containing all filenames that were found. Filled, e.g. in
ReadGridded.get_model_files()- Type:
- from_files
List of all netCDF files that were used to concatenate the current data cube (i.e. that can be based on certain matching settings such as var_name or time interval).
- Type:
- ts_types
list of all sampling frequencies (e.g. hourly, daily, monthly) that were inferred from filenames (based on Aerocom file naming convention) of all files that were found
- Type:
- vars
list containing all variable names (e.g. od550aer) that were inferred from filenames based on Aerocom model file naming convention
- Type:
- Parameters:
data_id (str) – string ID of model (e.g. “AATSR_SU_v4.3”,”CAM5.3-Oslo_CTRL2016”)
data_dir (str, optional) – directory containing data files. If provided, only this directory is considered for data files, else the input data_id is used to search for the corresponding directory.
file_convention (str) – string ID specifying the file convention of this model (cf. installation file file_conventions.ini)
init (bool) – if True, the model directory is searched (
search_data_dir()) on instantiation and if it is found, all valid files for this model are searched usingsearch_all_files().
- AUX_ADD_ARGS = {'concprcpoxn': {'prlim': 0.0001, 'prlim_set_under': nan, 'prlim_units': 'm d-1', 'ts_type': 'daily'}, 'concprcpoxs': {'prlim': 0.0001, 'prlim_set_under': nan, 'prlim_units': 'm d-1', 'ts_type': 'daily'}, 'concprcprdn': {'prlim': 0.0001, 'prlim_set_under': nan, 'prlim_units': 'm d-1', 'ts_type': 'daily'}}
Additional arguments passed to computation methods for auxiliary data This is optional and defined per-variable like in AUX_FUNS
- AUX_ALT_VARS = {'ac550dryaer': ['ac550aer'], 'od440aer': ['od443aer'], 'od870aer': ['od865aer']}
- AUX_FUNS = {'ang4487aer': <function compute_angstrom_coeff_cubes>, 'angabs4487aer': <function compute_angstrom_coeff_cubes>, 'conc*': <function multiply_cubes>, 'concNhno3': <function calc_concNhno3_from_vmr>, 'concNnh3': <function calc_concNnh3_from_vmr>, 'concNnh4': <function calc_concNnh4>, 'concNno3pm10': <function calc_concNno3pm10>, 'concNno3pm25': <function calc_concNno3pm25>, 'concNtnh': <function calc_concNtnh>, 'concNtno3': <function calc_concNtno3>, 'concno3': <function add_cubes>, 'concno3pm10': <function calc_concno3pm10>, 'concno3pm25': <function calc_concno3pm25>, 'concox': <function add_cubes>, 'concsspm10': <function add_cubes>, 'concsspm25': <function calc_sspm25>, 'dryoa': <function add_cubes>, 'fmf550aer': <function divide_cubes>, 'mmr*': <function mmr_from_vmr>, 'od550gt1aer': <function subtract_cubes>, 'sc550dryaer': <function subtract_cubes>, 'vmrox': <function add_cubes>, 'wetoa': <function add_cubes>}
- AUX_REQUIRES = {'ang4487aer': ('od440aer', 'od870aer'), 'angabs4487aer': ('abs440aer', 'abs870aer'), 'conc*': ('mmr*', 'rho'), 'concNhno3': ('vmrhno3',), 'concNnh3': ('vmrnh3',), 'concNnh4': ('concnh4',), 'concNno3pm10': ('concno3f', 'concno3c'), 'concNno3pm25': ('concno3f', 'concno3c'), 'concNtnh': ('concnh4', 'vmrnh3'), 'concNtno3': ('concno3f', 'concno3c', 'vmrhno3'), 'concno3': ('concno3c', 'concno3f'), 'concno3pm10': ('concno3f', 'concno3c'), 'concno3pm25': ('concno3f', 'concno3c'), 'concox': ('concno2', 'conco3'), 'concprcpoxn': ('wetoxn', 'pr'), 'concprcpoxs': ('wetoxs', 'pr'), 'concprcprdn': ('wetrdn', 'pr'), 'concsspm10': ('concss25', 'concsscoarse'), 'concsspm25': ('concss25', 'concsscoarse'), 'dryoa': ('drypoa', 'drysoa'), 'fmf550aer': ('od550lt1aer', 'od550aer'), 'mmr*': ('vmr*',), 'od550gt1aer': ('od550aer', 'od550lt1aer'), 'rho': ('ts', 'ps'), 'sc550dryaer': ('ec550dryaer', 'ac550dryaer'), 'vmrox': ('vmrno2', 'vmro3'), 'wetoa': ('wetpoa', 'wetsoa')}
- CONSTRAINT_OPERATORS = {'!=': <ufunc 'not_equal'>, '<': <ufunc 'less'>, '<=': <ufunc 'less_equal'>, '==': <ufunc 'equal'>, '>': <ufunc 'greater'>, '>=': <ufunc 'greater_equal'>}
- property TS_TYPES
List with valid filename encryptions specifying temporal resolution
Update 7.11.2019: not in use anymore due to improved handling of all possible frequencies now using TsType class.
- VERT_ALT = {'Surface': 'ModelLevel'}
- apply_read_constraint(data, constraint, **kwargs)[source]
Filter a GriddeData object by value in another variable
Note
BETA version, that was hacked down in a rush to be able to apply AOD>0.1 threshold when reading AE.
- Parameters:
data (GriddedData) – data object to which constraint is applied
constraint (dict) – dictionary defining read constraint (see
check_constraint_valid()for minimum requirement). If constraint contains key var_name (not mandatory), then the corresponding variable is attempted to be read and is used to evaluate constraint and the corresponding boolean mask is then applied to input data. Wherever this mask is True (i.e. constraint is met), the current value in input data will be replaced with numpy.ma.masked or, if specified, with entry new_val in input constraint dict.**kwargs (TYPE) – reading arguments in case additional variable data needs to be loaded, to determine filter mask (i.e. if var_name is specified in input constraint). Parse to
read_var().
- Raises:
ValueError – If constraint is invalid (cf.
check_constraint_valid()for details).- Returns:
modified data objects (all grid-points that met constraint are replaced with either numpy.ma.masked or with a value that can be specified via key new_val in input constraint).
- Return type:
- browser
This object can be used to
- check_compute_var(var_name)[source]
Check if variable name belongs to family that can be computed
For instance, if input var_name is concdust this method will check
AUX_REQUIRESto see if there is a variable family pattern (conc*) defined that specifies how to compute these variables. If a match is found, the required variables and computation method is added viaadd_aux_compute().
- check_constraint_valid(constraint)[source]
Check if reading constraint is valid
- Parameters:
constraint (dict) – reading constraint. Requires at lest entries for following keys: - operator (str): for valid operators see
CONSTRAINT_OPERATORS- filter_val (float): value against which data is evaluated wrt to operator- Raises:
ValueError – If constraint is invalid
- Return type:
None.
- compute_var(var_name, start=None, stop=None, ts_type=None, experiment=None, vert_which=None, flex_ts_type=True, prefer_longer=False, vars_to_read=None, aux_fun=None, try_convert_units=True, aux_add_args=None, rename_var=None, **kwargs)[source]
Compute auxiliary variable
Like
read_var()but for auxiliary variables (cf. AUX_REQUIRES)- Parameters:
var_name (str) – variable that are supposed to be read
start (Timestamp or str, optional) – start time of data import (if valid input, then the current
startwill be overwritten)stop (Timestamp or str, optional) – stop time of data import
ts_type (str) – string specifying temporal resolution (choose from hourly, 3hourly, daily, monthly). If None, prioritised of the available resolutions is used
experiment (str) – name of experiment (only relevant if this dataset contains more than one experiment)
vert_which (str) – valid AeroCom vertical info string encoded in name (e.g. Column, ModelLevel)
flex_ts_type (bool) – if True and if applicable, then another ts_type is used in case the input ts_type is not available for this variable
prefer_longer (bool) – if True and applicable, the ts_type resulting in the longer time coverage will be preferred over other possible frequencies that match the query.
try_convert_units (bool) – if True, units of GriddedData objects are attempted to be converted to AeroCom default. This applies both to the GriddedData objects being read for computation as well as the variable computed from the forme objects. This is, for instance, useful when computing concentration in precipitation from wet deposition and precipitation amount.
rename_var (str) – if this is set, the var_name attribute of the output GriddedData object will be updated accordingly.
**kwargs – additional keyword args passed to
_load_var()
- Returns:
loaded data object
- Return type:
- concatenate_cubes(cubes)[source]
Concatenate list of cubes into one cube
- Parameters:
CubeList – list of individual cubes
- Returns:
Single cube that contains concatenated cubes from input list
- Return type:
Cube
- Raises:
iris.exceptions.ConcatenateError – if concatenation of all cubes failed
- property file_type
File type of data files
- filter_files(var_name=None, ts_type=None, start=None, stop=None, experiment=None, vert_which=None, is_at_stations=False, df=None)[source]
Filter file database
- Parameters:
var_name (str) – variable that are supposed to be read
ts_type (str) – string specifying temporal resolution (choose from “hourly”, “3hourly”, “daily”, “monthly”). If None, prioritised of the available resolutions is used
start (Timestamp or str, optional) – start time of data import
stop (Timestamp or str, optional) – stop time of data import
experiment (str) – name of experiment (only relevant if this dataset contains more than one experiment)
vert_which (str or dict, optional) – valid AeroCom vertical info string encoded in name (e.g. Column, ModelLevel) or dictionary containing var_name as key and vertical coded string as value, accordingly
flex_ts_type (bool) – if True and if applicable, then another ts_type is used in case the input ts_type is not available for this variable
prefer_longer (bool) – if True and applicable, the ts_type resulting in the longer time coverage will be preferred over other possible frequencies that match the query.
- filter_query(var_name, ts_type=None, start=None, stop=None, experiment=None, vert_which=None, is_at_stations=False, flex_ts_type=True, prefer_longer=False)[source]
Filter files for read query based on input specs
- Returns:
dataframe containing filtered dataset
- Return type:
DataFrame
- find_common_ts_type(vars_to_read, start=None, stop=None, ts_type=None, experiment=None, vert_which=None, flex_ts_type=True)[source]
Find common ts_type for list of variables to be read
- Parameters:
vars_to_read (list) – list of variables that is supposed to be read
start (Timestamp or str, optional) – start time of data import (if valid input, then the current start will be overwritten)
stop (Timestamp or str, optional) – stop time of data import (if valid input, then the current
startwill be overwritten)ts_type (str) – string specifying temporal resolution (choose from hourly, 3hourly, daily, monthly). If None, prioritised of the available resolutions is used
experiment (str) – name of experiment (only relevant if this dataset contains more than one experiment)
vert_which (str) – valid AeroCom vertical info string encoded in name (e.g. Column, ModelLevel)
flex_ts_type (bool) – if True and if applicable, then another ts_type is used in case the input ts_type is not available for this variable
- Returns:
common ts_type for input variable
- Return type:
- Raises:
DataCoverageError – if no match can be found
- get_files(var_name, ts_type=None, start=None, stop=None, experiment=None, vert_which=None, is_at_stations=False, flex_ts_type=True, prefer_longer=False)[source]
Get data files based on input specs
- get_var_info_from_files() dict[source]
Creates dictionary that contains variable specific meta information
- Returns:
dictionary where keys are available variables and values (for each variable) contain information about available ts_types, years, etc.
- Return type:
- property name
Deprecated name of attribute data_id
- read(vars_to_retrieve=None, start=None, stop=None, ts_type=None, experiment=None, vert_which=None, flex_ts_type=True, prefer_longer=False, require_all_vars_avail=False, **kwargs)[source]
Read all variables that could be found
Reads all variables that are available (i.e. in
vars_filename)- Parameters:
vars_to_retrieve (list or str, optional) – variables that are supposed to be read. If None, all variables that are available are read.
start (Timestamp or str, optional) – start time of data import
stop (Timestamp or str, optional) – stop time of data import
ts_type (str, optional) – string specifying temporal resolution (choose from “hourly”, “3hourly”, “daily”, “monthly”). If None, prioritised of the available resolutions is used
experiment (str) – name of experiment (only relevant if this dataset contains more than one experiment)
vert_which (str or dict, optional) – valid AeroCom vertical info string encoded in name (e.g. Column, ModelLevel) or dictionary containing var_name as key and vertical coded string as value, accordingly
flex_ts_type (bool) – if True and if applicable, then another ts_type is used in case the input ts_type is not available for this variable
prefer_longer (bool) – if True and applicable, the ts_type resulting in the longer time coverage will be preferred over other possible frequencies that match the query.
require_all_vars_avail (bool) – if True, it is strictly required that all input variables are available.
**kwargs – optional and support for deprecated input args
- Returns:
loaded data objects (type
GriddedData)- Return type:
- Raises:
IOError – if input variable names is not list or string
if
require_all_vars_avail=Trueand one or more of the desired variables is not available in this class 2. ifrequire_all_vars_avail=Trueand if none of the input variables is available in this object
- read_var(var_name, start=None, stop=None, ts_type=None, experiment=None, vert_which=None, flex_ts_type=True, prefer_longer=False, aux_vars=None, aux_fun=None, constraints=None, try_convert_units=True, rename_var=None, **kwargs)[source]
Read model data for a specific variable
This method searches all valid files for a given variable and for a provided temporal resolution (e.g. daily, monthly), optionally within a certain time window, that may be specified on class instantiation or using the corresponding input parameters provided in this method.
The individual NetCDF files for a given temporal period are loaded as instances of the
iris.Cubeobject and appended to an instance of theiris.cube.CubeListobject. The latter is then used to concatenate the individual cubes in time into a single instance of thepyaerocom.GriddedDataclass. In order to ensure that this works, several things need to be ensured, which are listed in the following and which may be controlled within the global settings for NetCDF import using the attributeGRID_IO(instance ofOnLoad) in the default instance of thepyaerocom.config.Configobject accessible viapyaerocom.const.- Parameters:
var_name (str) – variable that are supposed to be read
start (Timestamp or str, optional) – start time of data import
stop (Timestamp or str, optional) – stop time of data import
ts_type (str) – string specifying temporal resolution (choose from “hourly”, “3hourly”, “daily”, “monthly”). If None, prioritised of the available resolutions is used
experiment (str) – name of experiment (only relevant if this dataset contains more than one experiment)
vert_which (str or dict, optional) – valid AeroCom vertical info string encoded in name (e.g. Column, ModelLevel) or dictionary containing var_name as key and vertical coded string as value, accordingly
flex_ts_type (bool) – if True and if applicable, then another ts_type is used in case the input ts_type is not available for this variable
prefer_longer (bool) – if True and applicable, the ts_type resulting in the longer time coverage will be preferred over other possible frequencies that match the query.
aux_vars (list) – only relevant if var_name is not available for reading but needs to be computed: list of variables that are required to compute var_name
aux_fun (callable) – only relevant if var_name is not available for reading but needs to be computed: custom method for computation (cf.
add_aux_compute()for details)constraints (list, optional) – list of reading constraints (dict type). See
check_constraint_valid()andapply_read_constraint()for details related to format of the individual constraints.try_convert_units (bool) – if True, then the unit of the variable data is checked against AeroCom default unit for that variable and if it deviates, it is attempted to be converted to the AeroCom default unit. Default is True.
rename_var (str) – if this is set, the var_name attribute of the output GriddedData object will be updated accordingly.
**kwargs – additional keyword args parsed to
_load_var()
- Returns:
loaded data object
- Return type:
- Raises:
AttributeError – if none of the ts_types identified from file names is valid
VarNotAvailableError – if specified ts_type is not supported
- property registered_var_patterns
List of string patterns for computation of variables
The information is extracted from
AUX_REQUIRES- Returns:
list of variable patterns
- Return type:
- search_all_files(update_file_convention=True)[source]
Search all valid model files for this model
This method browses the data directory and finds all valid files, that is, file that are named according to one of the aerocom file naming conventions. The file list is stored in
files.Note
It is presumed, that naming conventions of files in the data directory are not mixed but all correspond to either of the conventions defined in
- Parameters:
update_file_convention (bool) – if True, the first file in data_dir is used to identify the file naming convention (cf.
FileConventionRead)- Raises:
DataCoverageError – if no valid files could be found
- search_data_dir()[source]
Search data directory based on model ID
Wrapper for method
search_data_dir_aerocom()
- property start
First available year in the dataset (inferred from filenames)
- property stop
Last available year in the dataset (inferred from filenames)
- property ts_types
Available frequencies
- update(**kwargs)[source]
Update one or more valid parameters
- Parameters:
**kwargs – keyword args that will be used to update (overwrite) valid class attributes such as data, data_dir, files
- property vars
- property vars_filename
- property vars_provided
Variables provided by this dataset
Gridded data using EMEP conventions
Reading of ungridded data
Other than gridded data, ungridded data represents data that is irregularly sampled in space and time, for instance, observations at different locations around the globe. Such data is represented in pyaerocom by UngriddedData which is essentially a point-cloud dataset. Reading of UngriddedData is typically specific for different observational data records, as they typically come in various data formats using various metadata conventions, which need to be harmonised, which is done during the data import.
The following flowchart illustrates the architecture of ungridded reading in pyaerocom. Below are information about the individual reading classes for each dataset (blue in flowchart), the abstract template base classes the reading classes are based on (dark green) and the factory class ReadUngridded (orange) which has registered all individual reading classes. The data classes that are returned by the reading class are indicated in light green.
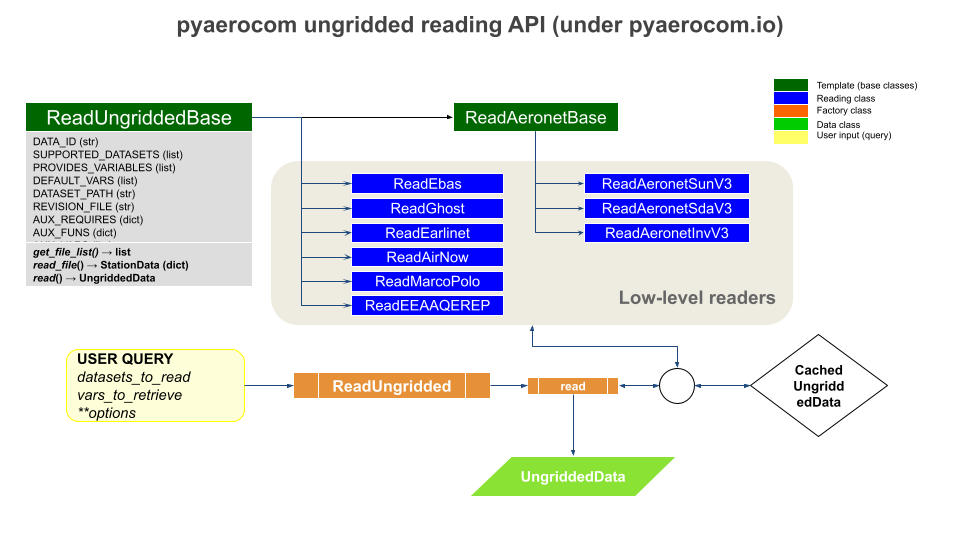
ReadUngridded factory class
Factory class that has all reading class for the individual datasets registered.
- class pyaerocom.io.readungridded.ReadUngridded(data_ids=None, ignore_cache=False, data_dirs=None, configs: PyaroConfig | list[PyaroConfig] | None = None)[source]
Factory class for reading of ungridded data based on obsnetwork ID
This class also features reading functionality that goes beyond reading of individual observation datasets; including, reading of multiple datasets and post computation of new variables based on datasets that can be read.
- Parameters:
SOON (COMING)
- DONOTCACHE_NAME = 'DONOTCACHE'
- property INCLUDED_DATASETS
- INCLUDED_READERS = [<class 'pyaerocom.io.read_aeronet_invv3.ReadAeronetInvV3'>, <class 'pyaerocom.io.read_aeronet_sdav3.ReadAeronetSdaV3'>, <class 'pyaerocom.io.read_aeronet_sunv3.ReadAeronetSunV3'>, <class 'pyaerocom.io.read_earlinet.ReadEarlinet'>, <class 'pyaerocom.io.read_eprofile.ReadEprofile'>, <class 'pyaerocom.io.read_ebas.ReadEbas'>, <class 'pyaerocom.io.read_aasetal.ReadAasEtal'>, <class 'pyaerocom.io.read_airnow.ReadAirNow'>, <class 'pyaerocom.io.read_eea_aqerep.ReadEEAAQEREP'>, <class 'pyaerocom.io.read_eea_aqerep_v2.ReadEEAAQEREP_V2'>, <class 'pyaerocom.io.cams2_83.read_obs.ReadCAMS2_83'>, <class 'pyaerocom.io.gaw.reader.ReadGAW'>, <class 'pyaerocom.io.ghost.reader.ReadGhost'>, <class 'pyaerocom.io.cnemc.reader.ReadCNEMC'>, <class 'pyaerocom.io.icos.reader.ReadICOS'>, <class 'pyaerocom.io.icpforests.reader.ReadICPForest'>, <class 'pyaerocom.io.sonde_like.reader.ReadEvdcOzoneSondeDataHdf'>, <class 'pyaerocom.io.sonde_like.reader.ReadEvdcOzoneSondeDataHarp'>]
- property SUPPORTED_DATASETS
Returns list of strings containing all supported dataset names
- SUPPORTED_READERS: list[type[ReadUngriddedBase]] = [<class 'pyaerocom.io.read_aeronet_invv3.ReadAeronetInvV3'>, <class 'pyaerocom.io.read_aeronet_sdav3.ReadAeronetSdaV3'>, <class 'pyaerocom.io.read_aeronet_sunv3.ReadAeronetSunV3'>, <class 'pyaerocom.io.read_earlinet.ReadEarlinet'>, <class 'pyaerocom.io.read_eprofile.ReadEprofile'>, <class 'pyaerocom.io.read_ebas.ReadEbas'>, <class 'pyaerocom.io.read_aasetal.ReadAasEtal'>, <class 'pyaerocom.io.read_airnow.ReadAirNow'>, <class 'pyaerocom.io.read_eea_aqerep.ReadEEAAQEREP'>, <class 'pyaerocom.io.read_eea_aqerep_v2.ReadEEAAQEREP_V2'>, <class 'pyaerocom.io.cams2_83.read_obs.ReadCAMS2_83'>, <class 'pyaerocom.io.gaw.reader.ReadGAW'>, <class 'pyaerocom.io.ghost.reader.ReadGhost'>, <class 'pyaerocom.io.cnemc.reader.ReadCNEMC'>, <class 'pyaerocom.io.icos.reader.ReadICOS'>, <class 'pyaerocom.io.icpforests.reader.ReadICPForest'>, <class 'pyaerocom.io.sonde_like.reader.ReadEvdcOzoneSondeDataHdf'>, <class 'pyaerocom.io.sonde_like.reader.ReadEvdcOzoneSondeDataHarp'>, <class 'pyaerocom.io.pyaro.read_pyaro.ReadPyaro'>]
- add_config(config: PyaroConfig) None[source]
Adds single PyaroConfig to self.configs
- Parameters:
config (PyaroConfig)
- Raises:
ValueError – If config is not PyaroConfig
- add_pyaro_reader(config: PyaroConfig) ReadUngriddedBase[source]
- property configs
List configs
- property data_id
ID of dataset
Note
Only works if exactly one dataset is assigned to the reader, that is, length of
data_idsis 1.- Raises:
AttributeError – if number of items in
data_idsis unequal one.- Returns:
data ID
- Return type:
- property data_ids
List of datasets supposed to be read
- get_lowlevel_reader(data_id: str | None = None) ReadUngriddedBase[source]
Helper method that returns initiated reader class for input ID
- Parameters:
data_id (str) – Name of dataset
- Returns:
instance of reading class (needs to be implementation of base class
ReadUngriddedBase).- Return type:
- get_vars_supported(obs_id: str, vars_desired: list[str])[source]
Filter input list of variables by supported ones for a certain data ID
- property ignore_cache
Boolean specifying whether caching is active or not
- property post_compute
Information about datasets that can be computed in post
- read(data_ids=None, vars_to_retrieve=None, only_cached=False, filter_post=None, configs: PyaroConfig | list[PyaroConfig] | None = None, **kwargs)[source]
Read observations
Iter over all datasets in
data_ids, callread_dataset()and append to data object- Parameters:
data_ids (str or list) – data ID or list of all datasets to be imported
vars_to_retrieve (str or list) – variable or list of variables to be imported
only_cached (bool) – if True, then nothing is reloaded but only data is loaded that is available as cached objects (not recommended to use but may be used if working offline without connection to database)
filter_post (dict, optional) – filters applied to UngriddedDataContainer object AFTER it is read into memory, via
UngriddedDataContainer.apply_filters(). This option was introduced in pyaerocom version 0.10.0 and should be used preferably over **kwargs. There is a certain flexibility with respect to how these filters can be defined, for instance, sub dicts for each data_id. The most common way would be to provide directly the input needed for UngriddedDataContainer.apply_filters. If you want to read multiple variables from one or more datasets, and if you want to apply variable specific filters, it is recommended to read the data individually for each variable and corresponding set of filters and then merge the individual filtered UngriddedDataContainer objects afterwards, e.g. using data_var1 & data_var2.**kwargs – Additional input options for reading of data, which are applied WHILE the data is read. If any such additional options are provided that are applied during the reading, then automatic caching of the output UngriddedDataContainer object will be deactivated. Thus, it is recommended to handle data filtering via filter_post argument whenever possible, which will result in better performance as the unconstrained original data is read in and cached, and then the filtering is applied.
Example
>>> import pyaerocom.io.readungridded as pio >>> from pyaerocom import const >>> obj = pio.ReadUngridded(data_ids=const.AERONET_SUN_V3L15_AOD_ALL_POINTS_NAME) >>> obj.read() >>> print(obj) >>> print(obj.metadata[0.]['latitude'])
- read_dataset(data_id, vars_to_retrieve=None, only_cached=False, filter_post=None, **kwargs)[source]
Read dataset into an instance of
ReadUngridded- Parameters:
data_id (str) – name of dataset
vars_to_retrieve (list) – variable or list of variables to be imported
only_cached (bool) – if True, then nothing is reloaded but only data is loaded that is available as cached objects (not recommended to use but may be used if working offline without connection to database)
filter_post (dict, optional) – filters applied to UngriddedDataContainer object AFTER it is read into memory, via
UngriddedDataContainer.apply_filters(). This option was introduced in pyaerocom version 0.10.0 and should be used preferably over **kwargs. There is a certain flexibility with respect to how these filters can be defined, for instance, sub dicts for each data_id. The most common way would be to provide directly the input needed for UngriddedDataContainer.apply_filters. If you want to read multiple variables from one or more datasets, and if you want to apply variable specific filters, it is recommended to read the data individually for each variable and corresponding set of filters and then merge the individual filtered UngriddedDataContainer objects afterwards, e.g. using data_var1 & data_var2.**kwargs – Additional input options for reading of data, which are applied WHILE the data is read. If any such additional options are provided that are applied during the reading, then automatic caching of the output UngriddedDataContainer object will be deactivated. Thus, it is recommended to handle data filtering via filter_post argument whenever possible, which will result in better performance as the unconstrained original data is read in and cached, and then the filtering is applied.
- Returns:
data object
- Return type:
UngriddedDataContainer
- read_dataset_post(data_id, vars_to_retrieve, only_cached=False, filter_post=None, **kwargs)[source]
Read dataset into an instance of
ReadUngridded- Parameters:
data_id (str) – name of dataset
vars_to_retrieve (list) – variable or list of variables to be imported
only_cached (bool) – if True, then nothing is reloaded but only data is loaded that is available as cached objects (not recommended to use but may be used if working offline without connection to database)
filter_post (dict, optional) – filters applied to UngriddedDataContainer object AFTER it is read into memory, via
UngriddedDataContainer.apply_filters(). This option was introduced in pyaerocom version 0.10.0 and should be used preferably over **kwargs. There is a certain flexibility with respect to how these filters can be defined, for instance, sub dicts for each data_id. The most common way would be to provide directly the input needed for UngriddedDataContainer.apply_filters. If you want to read multiple variables from one or more datasets, and if you want to apply variable specific filters, it is recommended to read the data individually for each variable and corresponding set of filters and then merge the individual filtered UngriddedDataContainer objects afterwards, e.g. using data_var1 & data_var2.**kwargs – Additional input options for reading of data, which are applied WHILE the data is read. If any such additional options are provided that are applied during the reading, then automatic caching of the output UngriddedDataContainer object will be deactivated. Thus, it is recommended to handle data filtering via filter_post argument whenever possible, which will result in better performance as the unconstrained original data is read in and cached, and then the filtering is applied.
- Returns:
data object
- Return type:
UngriddedDataContainer
- property supported_datasets
Wrapper for
SUPPORTED_DATASETS
ReadUngriddedBase template class
All ungridded reading routines are based on this template class.
- class pyaerocom.io.readungriddedbase.ReadUngriddedBase(data_id: str | None = None, data_dir: str | None = None)[source]
TEMPLATE: Abstract base class template for reading of ungridded data
Note
The two dictionaries
AUX_REQUIRESandAUX_FUNScan be filled with variables that are not contained in the original data files but are computed during the reading. The former specifies what additional variables are required to perform the computation and the latter specifies functions used to perform the computations of the auxiliary variables. See, for instance, the classReadAeronetSunV3, which includes the computation of the AOD at 550nm and the Angstrom coefficient (in 440-870 nm range) from AODs measured at other wavelengths.- AUX_FUNS = {}
Functions that are used to compute additional variables (i.e. one for each variable defined in AUX_REQUIRES)
- AUX_REQUIRES = {}
dictionary containing information about additionally required variables for each auxiliary variable (i.e. each variable that is not provided by the original data but computed on import)
- property AUX_VARS
List of auxiliary variables (keys of attr.
AUX_REQUIRES)Auxiliary variables are those that are not included in original files but are computed from other variables during import
- abstract property DEFAULT_VARS
List containing default variables to read
- IGNORE_META_KEYS = []
- property REVISION_FILE
Name of revision file located in data directory
- abstract property TS_TYPE
Temporal resolution of dataset
This should be defined in the header of an implementation class if it can be globally defined for the corresponding obs-network or in other cases it should be initiated as string
undefinedand then, if applicable, updated in the reading routine of a file.The TS_TYPE information should ultimately be written into the meta-data of objects returned by the implementation of
read_file()(e.g. instance ofStationDataor a normal dictionary) and the methodread()(which should ALWAYS return an instance of theUngriddedDataclass).Note
Please use
"undefined"if the derived class is not sampled on a regular basis.If applicable please use Aerocom ts_type (i.e. hourly, 3hourly, daily, monthly, yearly)
Note also, that the ts_type in a derived class may or may not be defined in a general case. For instance, in the EBAS database the resolution code can be found in the file header and may thus be initiated as
"undefined"in the initiation of the reading class and then updated when the class is being readFor derived implementation classes that support reading of multiple network versions, you may also assign
- check_vars_to_retrieve(vars_to_retrieve)[source]
Separate variables that are in file from those that are computed
Some of the provided variables by this interface are not included in the data files but are computed within this class during data import (e.g. od550aer, ang4487aer).
The latter may require additional parameters to be retrieved from the file, which is specified in the class header (cf. attribute
AUX_REQUIRES).This function checks the input list that specifies all required variables and separates them into two lists, one that includes all variables that can be read from the files and a second list that specifies all variables that are computed in this class.
- compute_additional_vars(data, vars_to_compute)[source]
Compute all additional variables
The computations for each additional parameter are done using the specified methods in
AUX_FUNS.- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_compute (list) – list of variable names that are supposed to be computed. Variables that are required for the computation of the variables need to be specified in
AUX_VARSand need to be available as data vectors in the provided data dictionary (key is the corresponding variable name of the required variable).
- Returns:
updated data object now containing also computed variables
- Return type:
- property data_dir: str
Location of the dataset
Note
This can be set explicitly when instantiating the class (e.g. if data is available on local machine). If unspecified, the data location is attempted to be inferred via
get_obsnetwork_dir()- Raises:
FileNotFoundError – if data directory does not exist or cannot be retrieved automatically
- Type:
- property data_id
ID of dataset
- property data_revision
Revision string from file Revision.txt in the main data directory
- find_in_file_list(pattern=None)[source]
Find all files that match a certain wildcard pattern
- Parameters:
pattern (
str, optional) – wildcard pattern that may be used to narrow down the search (e.g. usepattern=*Berlin*to find only files that contain Berlin in their filename)- Returns:
list containing all files in
filesthat match pattern- Return type:
- Raises:
IOError – if no matches can be found
- get_file_list(pattern=None)[source]
Search all files to be read
Uses
_FILEMASK(+ optional input search pattern, e.g. station_name) to find valid files for query.
- abstract read(vars_to_retrieve=None, files=[], first_file=None, last_file=None)[source]
Method that reads list of files as instance of
UngriddedData- Parameters:
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loadedfiles (
list, optional) – list of files to be read. If None, then the file list is used that is returned onget_file_list().first_file (
int, optional) – index of first file in file list to read. If None, the very first file in the list is usedlast_file (
int, optional) – index of last file in list to read. If None, the very last file in the list is used
- Returns:
instance of ungridded data object containing data from all files.
- Return type:
- abstract read_file(filename, vars_to_retrieve=None)[source]
Read single file
- Parameters:
filename (str) – string specifying filename
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loaded
- Returns:
imported data in a suitable format that can be handled by
read()which is supposed to append the loaded results from this method (which reads one datafile) to an instance ofUngriddedDatafor all files.- Return type:
dictorStationData, or other…
- read_first_file(**kwargs)[source]
Read first file returned from
get_file_list()Note
This method may be used for test purposes.
- Parameters:
**kwargs – keyword args passed to
read_file()(e.g. vars_to_retrieve)- Returns:
dictionary or similar containing loaded results from first file
- Return type:
dict-like
- read_station(station_id_filename, **kwargs)[source]
Read data from a single station into
UngriddedDataFind all files that contain the station ID in their filename and then call
read(), providing the reduced filelist as input, in order to read all files from this station into data object.- Parameters:
- Returns:
loaded data
- Return type:
- Raises:
IOError – if no files can be found for this station ID
- remove_outliers(data, vars_to_retrieve, **valid_rng_vars)[source]
Remove outliers from data
- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_retrieve (list) – list of variable names for which outliers will be removed from data
**valid_rng_vars – additional keyword args specifying variable name and corresponding min / max interval (list or tuple) that specifies valid range for the variable. For each variable that is not explicitly defined here, the default minimum / maximum value is used (accessed via
pyaerocom.const.VARS[var_name])
- var_supported(var_name)[source]
Check if input variable is supported
- Parameters:
var_name (str) – AeroCom variable name or alias
- Raises:
VariableDefinitionError – if input variable is not supported by pyaerocom
- Returns:
True, if variable is supported by this interface, else False
- Return type:
AERONET
Aerosol Robotic Network (AERONET)
AERONET base class
All AERONET reading classes are based on the template ReadAeronetBase
class which, in turn inherits from ReadUngriddedBase.
- class pyaerocom.io.readaeronetbase.ReadAeronetBase(data_id=None, data_dir=None)[source]
Bases:
ReadUngriddedBaseTEMPLATE: Abstract base class template for reading of Aeronet data
Extended abstract base class, derived from low-level base class
ReadUngriddedBasethat contains some more functionality.- ALT_VAR_NAMES_FILE = {}
dictionary specifying alternative column names for variables defined in
VAR_NAMES_FILE- Type:
OPTIONAL
- AUX_FUNS = {}
Functions that are used to compute additional variables (i.e. one for each variable defined in AUX_REQUIRES)
- AUX_REQUIRES = {}
dictionary containing information about additionally required variables for each auxiliary variable (i.e. each variable that is not provided by the original data but computed on import)
- property AUX_VARS
List of auxiliary variables (keys of attr.
AUX_REQUIRES)Auxiliary variables are those that are not included in original files but are computed from other variables during import
- COL_DELIM = ','
column delimiter in data block of files
- DEFAULT_UNIT = '1'
Default data unit that is assigned to all variables that are not specified in UNITS dictionary (cf.
UNITS)
- abstract property DEFAULT_VARS
List containing default variables to read
- IGNORE_META_KEYS = ['date', 'time', 'day_of_year']
- INSTRUMENT_NAME = 'sun_photometer'
name of measurement instrument
- META_NAMES_FILE = {}
dictionary specifying the file column names (values) for each metadata key (cf. attributes of
StationData, e.g. ‘station_name’, ‘longitude’, ‘latitude’, ‘altitude’)
- META_NAMES_FILE_ALT = ({},)
- property REVISION_FILE
Name of revision file located in data directory
- property TS_TYPE
Default implementation of string for temporal resolution
- TS_TYPES = {}
dictionary assigning temporal resolution flags for supported datasets that are provided in a defined temporal resolution. Key is the name of the dataset and value is the corresponding ts_type
- UNITS = {}
Variable specific units, only required for variables that deviate from
DEFAULT_UNIT(is irrelevant for all variables that are so far supported by the implemented Aeronet products, i.e. all variables are dimensionless as specified inDEFAULT_UNIT)
- VAR_NAMES_FILE = {}
dictionary specifying the file column names (values) for each Aerocom variable (keys)
- VAR_PATTERNS_FILE = {}
Mappings for identifying variables in file (may be specified in addition to explicit variable names specified in VAR_NAMES_FILE)
- check_vars_to_retrieve(vars_to_retrieve)
Separate variables that are in file from those that are computed
Some of the provided variables by this interface are not included in the data files but are computed within this class during data import (e.g. od550aer, ang4487aer).
The latter may require additional parameters to be retrieved from the file, which is specified in the class header (cf. attribute
AUX_REQUIRES).This function checks the input list that specifies all required variables and separates them into two lists, one that includes all variables that can be read from the files and a second list that specifies all variables that are computed in this class.
- property col_index
Dictionary that specifies the index for each data column
Note
Implementation depends on the data. For instance, if the variable information is provided in all files (of all stations) and always in the same column, then this can be set as a fixed dictionary in the __init__ function of the implementation (see e.g. class
ReadAeronetSunV2). In other cases, it may not be ensured that each variable is available in all files or the column definition may differ between different stations. In the latter case you may automise the column index retrieval by providing the header names for each meta and data column you want to extract using the attribute dictionariesMETA_NAMES_FILEandVAR_NAMES_FILEby calling_update_col_index()in your implementation ofread_file()when you reach the line that contains the header information.
- compute_additional_vars(data, vars_to_compute)
Compute all additional variables
The computations for each additional parameter are done using the specified methods in
AUX_FUNS.- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_compute (list) – list of variable names that are supposed to be computed. Variables that are required for the computation of the variables need to be specified in
AUX_VARSand need to be available as data vectors in the provided data dictionary (key is the corresponding variable name of the required variable).
- Returns:
updated data object now containing also computed variables
- Return type:
- property data_dir: str
Location of the dataset
Note
This can be set explicitly when instantiating the class (e.g. if data is available on local machine). If unspecified, the data location is attempted to be inferred via
get_obsnetwork_dir()- Raises:
FileNotFoundError – if data directory does not exist or cannot be retrieved automatically
- Type:
- property data_id
ID of dataset
- property data_revision
Revision string from file Revision.txt in the main data directory
- find_in_file_list(pattern=None)
Find all files that match a certain wildcard pattern
- Parameters:
pattern (
str, optional) – wildcard pattern that may be used to narrow down the search (e.g. usepattern=*Berlin*to find only files that contain Berlin in their filename)- Returns:
list containing all files in
filesthat match pattern- Return type:
- Raises:
IOError – if no matches can be found
- get_file_list(pattern=None)
Search all files to be read
Uses
_FILEMASK(+ optional input search pattern, e.g. station_name) to find valid files for query.
- infer_wavelength_colname(colname, low=250, high=2000)[source]
Get variable wavelength from column name
- Parameters:
- Returns:
wavelength in nm as floating str
- Return type:
- Raises:
ValueError – if None or more than one number is detected in variable string
- read(vars_to_retrieve=None, files=None, first_file=None, last_file=None, file_pattern=None, common_meta=None)[source]
Method that reads list of files as instance of
UngriddedData- Parameters:
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loadedfiles (
list, optional) – list of files to be read. If None, then the file list is used that is returned onget_file_list().first_file (
int, optional) – index of first file in file list to read. If None, the very first file in the list is used. Note: is ignored if input parameter file_pattern is specified.last_file (
int, optional) – index of last file in list to read. If None, the very last file in the list is used. Note: is ignored if input parameter file_pattern is specified.file_pattern (str, optional) – string pattern for file search (cf
get_file_list())common_meta (dict, optional) – dictionary that contains additional metadata shared for this network (assigned to each metadata block of the
UngriddedDataobject that is returned)
- Returns:
data object
- Return type:
- abstract read_file(filename, vars_to_retrieve=None)
Read single file
- Parameters:
filename (str) – string specifying filename
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loaded
- Returns:
imported data in a suitable format that can be handled by
read()which is supposed to append the loaded results from this method (which reads one datafile) to an instance ofUngriddedDatafor all files.- Return type:
dictorStationData, or other…
- read_first_file(**kwargs)
Read first file returned from
get_file_list()Note
This method may be used for test purposes.
- Parameters:
**kwargs – keyword args passed to
read_file()(e.g. vars_to_retrieve)- Returns:
dictionary or similar containing loaded results from first file
- Return type:
dict-like
- read_station(station_id_filename, **kwargs)
Read data from a single station into
UngriddedDataFind all files that contain the station ID in their filename and then call
read(), providing the reduced filelist as input, in order to read all files from this station into data object.- Parameters:
- Returns:
loaded data
- Return type:
- Raises:
IOError – if no files can be found for this station ID
- remove_outliers(data, vars_to_retrieve, **valid_rng_vars)
Remove outliers from data
- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_retrieve (list) – list of variable names for which outliers will be removed from data
**valid_rng_vars – additional keyword args specifying variable name and corresponding min / max interval (list or tuple) that specifies valid range for the variable. For each variable that is not explicitly defined here, the default minimum / maximum value is used (accessed via
pyaerocom.const.VARS[var_name])
- var_supported(var_name)
Check if input variable is supported
- Parameters:
var_name (str) – AeroCom variable name or alias
- Raises:
VariableDefinitionError – if input variable is not supported by pyaerocom
- Returns:
True, if variable is supported by this interface, else False
- Return type:
AERONET Sun (V3)
- class pyaerocom.io.read_aeronet_sunv3.ReadAeronetSunV3(data_id=None, data_dir=None)[source]
Bases:
ReadAeronetBaseInterface for reading Aeronet direct sun version 3 Level 1.5 and 2.0 data
See also
Base classes
ReadAeronetBaseandReadUngriddedBase- ALT_VAR_NAMES_FILE = {}
dictionary specifying alternative column names for variables defined in
VAR_NAMES_FILE- Type:
OPTIONAL
- AUX_FUNS = {'ang44&87aer': <function calc_ang4487aer>, 'od550aer': <function calc_od550aer>, 'od550lt1ang': <function calc_od550lt1ang>, 'proxyod550aerh2o': <function calc_od550aer>, 'proxyod550bc': <function calc_od550aer>, 'proxyod550dust': <function calc_od550aer>, 'proxyod550nh4': <function calc_od550aer>, 'proxyod550no3': <function calc_od550aer>, 'proxyod550oa': <function calc_od550aer>, 'proxyod550so4': <function calc_od550aer>, 'proxyod550ss': <function calc_od550aer>, 'proxyzaerosol': <function calc_od550aer>, 'proxyzdust': <function calc_od550aer>}
Functions that are used to compute additional variables (i.e. one for each variable defined in AUX_REQUIRES)
- AUX_REQUIRES = {'ang44&87aer': ['od440aer', 'od870aer'], 'od550aer': ['od440aer', 'od500aer', 'ang4487aer'], 'od550lt1ang': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyod550aerh2o': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyod550bc': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyod550dust': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyod550nh4': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyod550no3': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyod550oa': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyod550so4': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyod550ss': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyzaerosol': ['od440aer', 'od500aer', 'ang4487aer'], 'proxyzdust': ['od440aer', 'od500aer', 'ang4487aer']}
dictionary containing information about additionally required variables for each auxiliary variable (i.e. each variable that is not provided by the original data but computed on import)
- property AUX_VARS
List of auxiliary variables (keys of attr.
AUX_REQUIRES)Auxiliary variables are those that are not included in original files but are computed from other variables during import
- COL_DELIM = ','
column delimiter in data block of files
- DEFAULT_UNIT = '1'
Default data unit that is assigned to all variables that are not specified in UNITS dictionary (cf.
UNITS)
- DEFAULT_VARS = ['od550aer', 'ang4487aer']
default variables for read method
- IGNORE_META_KEYS = ['date', 'time', 'day_of_year']
- INSTRUMENT_NAME = 'sun_photometer'
name of measurement instrument
- META_NAMES_FILE = {'altitude': 'Site_Elevation(m)', 'data_quality_level': 'Data_Quality_Level', 'date': 'Date(dd:mm:yyyy)', 'day_of_year': 'Day_of_Year', 'instrument_number': 'AERONET_Instrument_Number', 'latitude': 'Site_Latitude(Degrees)', 'longitude': 'Site_Longitude(Degrees)', 'station_name': 'AERONET_Site', 'time': 'Time(hh:mm:ss)'}
dictionary specifying the file column names (values) for each metadata key (cf. attributes of
StationData, e.g. ‘station_name’, ‘longitude’, ‘latitude’, ‘altitude’)
- META_NAMES_FILE_ALT = {'AERONET_Site': ['AERONET_Site_Name']}
- NAN_VAL = -999.0
- PROVIDES_VARIABLES: list[str] = ['od340aer', 'od440aer', 'od500aer', 'od870aer', 'ang4487aer']
List of variables that are provided by this dataset (will be extended by auxiliary variables on class init, for details see __init__ method of base class ReadUngriddedBase)
- property REVISION_FILE
Name of revision file located in data directory
- SUPPORTED_DATASETS: list[str] = ['AeronetSunV3Lev1.5.daily', 'AeronetSunV3Lev1.5.AP', 'AeronetSunV3Lev2.daily', 'AeronetSunV3Lev2.AP']
List of all datasets supported by this interface
- property TS_TYPE
Default implementation of string for temporal resolution
- TS_TYPES = {'AeronetSunV3Lev1.5.daily': 'daily', 'AeronetSunV3Lev2.daily': 'daily'}
dictionary assigning temporal resolution flags for supported datasets that are provided in a defined temporal resolution
- UNITS = {'proxyzaerosol': 'km', 'proxyzdust': 'km'}
Variable specific units, only required for variables that deviate from
DEFAULT_UNIT(is irrelevant for all variables that are so far supported by the implemented Aeronet products, i.e. all variables are dimensionless as specified inDEFAULT_UNIT)
- VAR_NAMES_FILE = {'ang4487aer': '440-870_Angstrom_Exponent', 'od340aer': 'AOD_340nm', 'od440aer': 'AOD_440nm', 'od500aer': 'AOD_500nm', 'od870aer': 'AOD_870nm'}
dictionary specifying the file column names (values) for each Aerocom variable (keys)
- VAR_PATTERNS_FILE = {'AOD_([0-9]*)nm': 'od*aer'}
Mappings for identifying variables in file
- check_vars_to_retrieve(vars_to_retrieve)
Separate variables that are in file from those that are computed
Some of the provided variables by this interface are not included in the data files but are computed within this class during data import (e.g. od550aer, ang4487aer).
The latter may require additional parameters to be retrieved from the file, which is specified in the class header (cf. attribute
AUX_REQUIRES).This function checks the input list that specifies all required variables and separates them into two lists, one that includes all variables that can be read from the files and a second list that specifies all variables that are computed in this class.
- property col_index
Dictionary that specifies the index for each data column
Note
Implementation depends on the data. For instance, if the variable information is provided in all files (of all stations) and always in the same column, then this can be set as a fixed dictionary in the __init__ function of the implementation (see e.g. class
ReadAeronetSunV2). In other cases, it may not be ensured that each variable is available in all files or the column definition may differ between different stations. In the latter case you may automise the column index retrieval by providing the header names for each meta and data column you want to extract using the attribute dictionariesMETA_NAMES_FILEandVAR_NAMES_FILEby calling_update_col_index()in your implementation ofread_file()when you reach the line that contains the header information.
- compute_additional_vars(data, vars_to_compute)
Compute all additional variables
The computations for each additional parameter are done using the specified methods in
AUX_FUNS.- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_compute (list) – list of variable names that are supposed to be computed. Variables that are required for the computation of the variables need to be specified in
AUX_VARSand need to be available as data vectors in the provided data dictionary (key is the corresponding variable name of the required variable).
- Returns:
updated data object now containing also computed variables
- Return type:
- property data_dir: str
Location of the dataset
Note
This can be set explicitly when instantiating the class (e.g. if data is available on local machine). If unspecified, the data location is attempted to be inferred via
get_obsnetwork_dir()- Raises:
FileNotFoundError – if data directory does not exist or cannot be retrieved automatically
- Type:
- property data_id
ID of dataset
- property data_revision
Revision string from file Revision.txt in the main data directory
- find_in_file_list(pattern=None)
Find all files that match a certain wildcard pattern
- Parameters:
pattern (
str, optional) – wildcard pattern that may be used to narrow down the search (e.g. usepattern=*Berlin*to find only files that contain Berlin in their filename)- Returns:
list containing all files in
filesthat match pattern- Return type:
- Raises:
IOError – if no matches can be found
- get_file_list(pattern=None)
Search all files to be read
Uses
_FILEMASK(+ optional input search pattern, e.g. station_name) to find valid files for query.
- infer_wavelength_colname(colname, low=250, high=2000)
Get variable wavelength from column name
- Parameters:
- Returns:
wavelength in nm as floating str
- Return type:
- Raises:
ValueError – if None or more than one number is detected in variable string
- print_all_columns()
- read(vars_to_retrieve=None, files=None, first_file=None, last_file=None, file_pattern=None, common_meta=None)
Method that reads list of files as instance of
UngriddedData- Parameters:
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loadedfiles (
list, optional) – list of files to be read. If None, then the file list is used that is returned onget_file_list().first_file (
int, optional) – index of first file in file list to read. If None, the very first file in the list is used. Note: is ignored if input parameter file_pattern is specified.last_file (
int, optional) – index of last file in list to read. If None, the very last file in the list is used. Note: is ignored if input parameter file_pattern is specified.file_pattern (str, optional) – string pattern for file search (cf
get_file_list())common_meta (dict, optional) – dictionary that contains additional metadata shared for this network (assigned to each metadata block of the
UngriddedDataobject that is returned)
- Returns:
data object
- Return type:
- read_file(filename, vars_to_retrieve=None, vars_as_series=False)[source]
Read Aeronet Sun V3 level 1.5 or 2 file
- Parameters:
filename (str) – absolute path to filename to read
vars_to_retrieve (
list, optional) – list of str with variable names to read. If None, useDEFAULT_VARSvars_as_series (bool) – if True, the data columns of all variables in the result dictionary are converted into pandas Series objects
- Returns:
dict-like object containing results
- Return type:
- read_first_file(**kwargs)
Read first file returned from
get_file_list()Note
This method may be used for test purposes.
- Parameters:
**kwargs – keyword args passed to
read_file()(e.g. vars_to_retrieve)- Returns:
dictionary or similar containing loaded results from first file
- Return type:
dict-like
- read_station(station_id_filename, **kwargs)
Read data from a single station into
UngriddedDataFind all files that contain the station ID in their filename and then call
read(), providing the reduced filelist as input, in order to read all files from this station into data object.- Parameters:
- Returns:
loaded data
- Return type:
- Raises:
IOError – if no files can be found for this station ID
- remove_outliers(data, vars_to_retrieve, **valid_rng_vars)
Remove outliers from data
- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_retrieve (list) – list of variable names for which outliers will be removed from data
**valid_rng_vars – additional keyword args specifying variable name and corresponding min / max interval (list or tuple) that specifies valid range for the variable. For each variable that is not explicitly defined here, the default minimum / maximum value is used (accessed via
pyaerocom.const.VARS[var_name])
- var_supported(var_name)
Check if input variable is supported
- Parameters:
var_name (str) – AeroCom variable name or alias
- Raises:
VariableDefinitionError – if input variable is not supported by pyaerocom
- Returns:
True, if variable is supported by this interface, else False
- Return type:
AERONET SDA (V3)
- class pyaerocom.io.read_aeronet_sdav3.ReadAeronetSdaV3(data_id=None, data_dir=None)[source]
Bases:
ReadAeronetBaseInterface for reading Aeronet Sun SDA V3 Level 1.5 and 2.0 data
See also
Base classes
ReadAeronetBaseandReadUngriddedBase- ALT_VAR_NAMES_FILE = {}
dictionary specifying alternative column names for variables defined in
VAR_NAMES_FILE- Type:
OPTIONAL
- AUX_FUNS = {'od550aer': <function calc_od550aer>, 'od550dust': <function calc_od550gt1aer>, 'od550gt1aer': <function calc_od550gt1aer>, 'od550lt1aer': <function calc_od550lt1aer>}
Functions that are used to compute additional variables (i.e. one for each variable defined in AUX_REQUIRES)
- AUX_REQUIRES = {'od550aer': ['od500aer', 'ang4487aer'], 'od550dust': ['od500gt1aer', 'ang4487aer'], 'od550gt1aer': ['od500gt1aer', 'ang4487aer'], 'od550lt1aer': ['od500lt1aer', 'ang4487aer']}
dictionary containing information about additionally required variables for each auxiliary variable (i.e. each variable that is not provided by the original data but computed on import)
- property AUX_VARS
List of auxiliary variables (keys of attr.
AUX_REQUIRES)Auxiliary variables are those that are not included in original files but are computed from other variables during import
- COL_DELIM = ','
column delimiter in data block of files
- DEFAULT_UNIT = '1'
Default data unit that is assigned to all variables that are not specified in UNITS dictionary (cf.
UNITS)
- DEFAULT_VARS = ['od550aer', 'od550gt1aer', 'od550lt1aer', 'od550dust']
default variables for read method
- IGNORE_META_KEYS = ['date', 'time', 'day_of_year']
- INSTRUMENT_NAME = 'sun_photometer'
name of measurement instrument
- META_NAMES_FILE = {'altitude': 'Site_Elevation(m)', 'data_quality_level': 'Data_Quality_Level', 'date': 'Date_(dd:mm:yyyy)', 'day_of_year': 'Day_of_Year', 'instrument_number': 'AERONET_Instrument_Number', 'latitude': 'Site_Latitude(Degrees)', 'longitude': 'Site_Longitude(Degrees)', 'station_name': 'AERONET_Site', 'time': 'Time_(hh:mm:ss)'}
dictionary specifying the file column names (values) for each metadata key (cf. attributes of
StationData, e.g. ‘station_name’, ‘longitude’, ‘latitude’, ‘altitude’)
- META_NAMES_FILE_ALT = ({},)
- NAN_VAL = -999.0
value corresponding to invalid measurement
- PROVIDES_VARIABLES: list[str] = ['od500gt1aer', 'od500lt1aer', 'od500aer', 'ang4487aer', 'od500dust']
List of variables that are provided by this dataset (will be extended by auxiliary variables on class init, for details see __init__ method of base class ReadUngriddedBase)
- property REVISION_FILE
Name of revision file located in data directory
- SUPPORTED_DATASETS: list[str] = ['AeronetSDAV3Lev1.5.daily', 'AeronetSDAV3Lev2.daily']
List of all datasets supported by this interface
- property TS_TYPE
Default implementation of string for temporal resolution
- TS_TYPES = {'AeronetSDAV3Lev1.5.daily': 'daily', 'AeronetSDAV3Lev2.daily': 'daily'}
dictionary assigning temporal resolution flags for supported datasets that are provided in a defined temporal resolution
- UNITS = {}
Variable specific units, only required for variables that deviate from
DEFAULT_UNIT(is irrelevant for all variables that are so far supported by the implemented Aeronet products, i.e. all variables are dimensionless as specified inDEFAULT_UNIT)
- VAR_NAMES_FILE = {'ang4487aer': 'Angstrom_Exponent(AE)-Total_500nm[alpha]', 'od500aer': 'Total_AOD_500nm[tau_a]', 'od500dust': 'Coarse_Mode_AOD_500nm[tau_c]', 'od500gt1aer': 'Coarse_Mode_AOD_500nm[tau_c]', 'od500lt1aer': 'Fine_Mode_AOD_500nm[tau_f]'}
dictionary specifying the file column names (values) for each Aerocom variable (keys)
- VAR_PATTERNS_FILE = {}
Mappings for identifying variables in file (may be specified in addition to explicit variable names specified in VAR_NAMES_FILE)
- check_vars_to_retrieve(vars_to_retrieve)
Separate variables that are in file from those that are computed
Some of the provided variables by this interface are not included in the data files but are computed within this class during data import (e.g. od550aer, ang4487aer).
The latter may require additional parameters to be retrieved from the file, which is specified in the class header (cf. attribute
AUX_REQUIRES).This function checks the input list that specifies all required variables and separates them into two lists, one that includes all variables that can be read from the files and a second list that specifies all variables that are computed in this class.
- property col_index
Dictionary that specifies the index for each data column
Note
Implementation depends on the data. For instance, if the variable information is provided in all files (of all stations) and always in the same column, then this can be set as a fixed dictionary in the __init__ function of the implementation (see e.g. class
ReadAeronetSunV2). In other cases, it may not be ensured that each variable is available in all files or the column definition may differ between different stations. In the latter case you may automise the column index retrieval by providing the header names for each meta and data column you want to extract using the attribute dictionariesMETA_NAMES_FILEandVAR_NAMES_FILEby calling_update_col_index()in your implementation ofread_file()when you reach the line that contains the header information.
- compute_additional_vars(data, vars_to_compute)
Compute all additional variables
The computations for each additional parameter are done using the specified methods in
AUX_FUNS.- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_compute (list) – list of variable names that are supposed to be computed. Variables that are required for the computation of the variables need to be specified in
AUX_VARSand need to be available as data vectors in the provided data dictionary (key is the corresponding variable name of the required variable).
- Returns:
updated data object now containing also computed variables
- Return type:
- property data_dir: str
Location of the dataset
Note
This can be set explicitly when instantiating the class (e.g. if data is available on local machine). If unspecified, the data location is attempted to be inferred via
get_obsnetwork_dir()- Raises:
FileNotFoundError – if data directory does not exist or cannot be retrieved automatically
- Type:
- property data_id
ID of dataset
- property data_revision
Revision string from file Revision.txt in the main data directory
- find_in_file_list(pattern=None)
Find all files that match a certain wildcard pattern
- Parameters:
pattern (
str, optional) – wildcard pattern that may be used to narrow down the search (e.g. usepattern=*Berlin*to find only files that contain Berlin in their filename)- Returns:
list containing all files in
filesthat match pattern- Return type:
- Raises:
IOError – if no matches can be found
- get_file_list(pattern=None)
Search all files to be read
Uses
_FILEMASK(+ optional input search pattern, e.g. station_name) to find valid files for query.
- infer_wavelength_colname(colname, low=250, high=2000)
Get variable wavelength from column name
- Parameters:
- Returns:
wavelength in nm as floating str
- Return type:
- Raises:
ValueError – if None or more than one number is detected in variable string
- print_all_columns()
- read(vars_to_retrieve=None, files=None, first_file=None, last_file=None, file_pattern=None, common_meta=None)
Method that reads list of files as instance of
UngriddedData- Parameters:
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loadedfiles (
list, optional) – list of files to be read. If None, then the file list is used that is returned onget_file_list().first_file (
int, optional) – index of first file in file list to read. If None, the very first file in the list is used. Note: is ignored if input parameter file_pattern is specified.last_file (
int, optional) – index of last file in list to read. If None, the very last file in the list is used. Note: is ignored if input parameter file_pattern is specified.file_pattern (str, optional) – string pattern for file search (cf
get_file_list())common_meta (dict, optional) – dictionary that contains additional metadata shared for this network (assigned to each metadata block of the
UngriddedDataobject that is returned)
- Returns:
data object
- Return type:
- read_file(filename, vars_to_retrieve=None, vars_as_series=False)[source]
Read Aeronet SDA V3 file and return it in a dictionary
- Parameters:
filename (str) – absolute path to filename to read
vars_to_retrieve (
list, optional) – list of str with variable names to read. If None, useDEFAULT_VARSvars_as_series (bool) – if True, the data columns of all variables in the result dictionary are converted into pandas Series objects
- Returns:
dict-like object containing results
- Return type:
- read_first_file(**kwargs)
Read first file returned from
get_file_list()Note
This method may be used for test purposes.
- Parameters:
**kwargs – keyword args passed to
read_file()(e.g. vars_to_retrieve)- Returns:
dictionary or similar containing loaded results from first file
- Return type:
dict-like
- read_station(station_id_filename, **kwargs)
Read data from a single station into
UngriddedDataFind all files that contain the station ID in their filename and then call
read(), providing the reduced filelist as input, in order to read all files from this station into data object.- Parameters:
- Returns:
loaded data
- Return type:
- Raises:
IOError – if no files can be found for this station ID
- remove_outliers(data, vars_to_retrieve, **valid_rng_vars)
Remove outliers from data
- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_retrieve (list) – list of variable names for which outliers will be removed from data
**valid_rng_vars – additional keyword args specifying variable name and corresponding min / max interval (list or tuple) that specifies valid range for the variable. For each variable that is not explicitly defined here, the default minimum / maximum value is used (accessed via
pyaerocom.const.VARS[var_name])
- var_supported(var_name)
Check if input variable is supported
- Parameters:
var_name (str) – AeroCom variable name or alias
- Raises:
VariableDefinitionError – if input variable is not supported by pyaerocom
- Returns:
True, if variable is supported by this interface, else False
- Return type:
AERONET Inversion (V3)
- class pyaerocom.io.read_aeronet_invv3.ReadAeronetInvV3(data_id=None, data_dir=None)[source]
Bases:
ReadAeronetBaseInterface for reading Aeronet inversion V3 Level 1.5 and 2.0 data
- Parameters:
data_id – string specifying either of the supported datasets that are defined in
SUPPORTED_DATASETS
- ALT_VAR_NAMES_FILE = {}
dictionary specifying alternative column names for variables defined in
VAR_NAMES_FILE- Type:
OPTIONAL
- AUX_FUNS = {'abs550aer': <function calc_abs550aer>, 'od550aer': <function calc_od550aer>}
Functions that are used to compute additional variables (i.e. one for each variable defined in AUX_REQUIRES)
- AUX_REQUIRES = {'abs550aer': ['abs440aer', 'angabs4487aer'], 'od550aer': ['od440aer', 'ang4487aer']}
dictionary containing information about additionally required variables for each auxiliary variable (i.e. each variable that is not provided by the original data but computed on import)
- property AUX_VARS
List of auxiliary variables (keys of attr.
AUX_REQUIRES)Auxiliary variables are those that are not included in original files but are computed from other variables during import
- COL_DELIM = ','
column delimiter in data block of files
- DEFAULT_UNIT = '1'
Default data unit that is assigned to all variables that are not specified in UNITS dictionary (cf.
UNITS)
- DEFAULT_VARS = ['abs550aer', 'od550aer']
default variables for read method
- IGNORE_META_KEYS = ['date', 'time', 'day_of_year']
- INSTRUMENT_NAME = 'sun_photometer'
name of measurement instrument
- META_NAMES_FILE = {'altitude': 'Elevation(m)', 'date': 'Date(dd:mm:yyyy)', 'day_of_year': 'Day_of_Year(fraction)', 'latitude': 'Latitude(Degrees)', 'longitude': 'Longitude(Degrees)', 'station_name': 'AERONET_Site', 'time': 'Time(hh:mm:ss)'}
dictionary specifying the file column names (values) for each metadata key (cf. attributes of
StationData, e.g. ‘station_name’, ‘longitude’, ‘latitude’, ‘altitude’)
- META_NAMES_FILE_ALT = ({},)
- NAN_VAL = -999.0
value corresponding to invalid measurement
- PROVIDES_VARIABLES: list[str] = ['abs440aer', 'angabs4487aer', 'od440aer', 'ang4487aer', 'ssa675aer', 'ssa670aer']
List of variables that are provided by this dataset (will be extended by auxiliary variables on class init, for details see __init__ method of base class ReadUngriddedBase)
- property REVISION_FILE
Name of revision file located in data directory
- SUPPORTED_DATASETS: list[str] = ['AeronetInvV3Lev2.daily', 'AeronetInvV3Lev1.5.daily']
List of all datasets supported by this interface
- property TS_TYPE
Default implementation of string for temporal resolution
- TS_TYPES = {'AeronetInvV3Lev1.5.daily': 'daily', 'AeronetInvV3Lev2.daily': 'daily'}
dictionary assigning temporal resolution flags for supported datasets that are provided in a defined temporal resolution
- UNITS = {}
Variable specific units, only required for variables that deviate from
DEFAULT_UNIT(is irrelevant for all variables that are so far supported by the implemented Aeronet products, i.e. all variables are dimensionless as specified inDEFAULT_UNIT)
- VAR_NAMES_FILE = {'abs440aer': 'Absorption_AOD[440nm]', 'ang4487aer': 'Extinction_Angstrom_Exponent_440-870nm-Total', 'angabs4487aer': 'Absorption_Angstrom_Exponent_440-870nm', 'od440aer': 'AOD_Extinction-Total[440nm]', 'ssa670aer': 'Single_Scattering_Albedo[675nm]', 'ssa675aer': 'Single_Scattering_Albedo[675nm]'}
dictionary specifying the file column names (values) for each Aerocom variable (keys)
- VAR_PATTERNS_FILE = {}
Mappings for identifying variables in file (may be specified in addition to explicit variable names specified in VAR_NAMES_FILE)
- check_vars_to_retrieve(vars_to_retrieve)
Separate variables that are in file from those that are computed
Some of the provided variables by this interface are not included in the data files but are computed within this class during data import (e.g. od550aer, ang4487aer).
The latter may require additional parameters to be retrieved from the file, which is specified in the class header (cf. attribute
AUX_REQUIRES).This function checks the input list that specifies all required variables and separates them into two lists, one that includes all variables that can be read from the files and a second list that specifies all variables that are computed in this class.
- property col_index
Dictionary that specifies the index for each data column
Note
Implementation depends on the data. For instance, if the variable information is provided in all files (of all stations) and always in the same column, then this can be set as a fixed dictionary in the __init__ function of the implementation (see e.g. class
ReadAeronetSunV2). In other cases, it may not be ensured that each variable is available in all files or the column definition may differ between different stations. In the latter case you may automise the column index retrieval by providing the header names for each meta and data column you want to extract using the attribute dictionariesMETA_NAMES_FILEandVAR_NAMES_FILEby calling_update_col_index()in your implementation ofread_file()when you reach the line that contains the header information.
- compute_additional_vars(data, vars_to_compute)
Compute all additional variables
The computations for each additional parameter are done using the specified methods in
AUX_FUNS.- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_compute (list) – list of variable names that are supposed to be computed. Variables that are required for the computation of the variables need to be specified in
AUX_VARSand need to be available as data vectors in the provided data dictionary (key is the corresponding variable name of the required variable).
- Returns:
updated data object now containing also computed variables
- Return type:
- property data_dir: str
Location of the dataset
Note
This can be set explicitly when instantiating the class (e.g. if data is available on local machine). If unspecified, the data location is attempted to be inferred via
get_obsnetwork_dir()- Raises:
FileNotFoundError – if data directory does not exist or cannot be retrieved automatically
- Type:
- property data_id
ID of dataset
- property data_revision
Revision string from file Revision.txt in the main data directory
- find_in_file_list(pattern=None)
Find all files that match a certain wildcard pattern
- Parameters:
pattern (
str, optional) – wildcard pattern that may be used to narrow down the search (e.g. usepattern=*Berlin*to find only files that contain Berlin in their filename)- Returns:
list containing all files in
filesthat match pattern- Return type:
- Raises:
IOError – if no matches can be found
- get_file_list(pattern=None)
Search all files to be read
Uses
_FILEMASK(+ optional input search pattern, e.g. station_name) to find valid files for query.
- infer_wavelength_colname(colname, low=250, high=2000)
Get variable wavelength from column name
- Parameters:
- Returns:
wavelength in nm as floating str
- Return type:
- Raises:
ValueError – if None or more than one number is detected in variable string
- print_all_columns()
- read(vars_to_retrieve=None, files=None, first_file=None, last_file=None, file_pattern=None, common_meta=None)
Method that reads list of files as instance of
UngriddedData- Parameters:
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loadedfiles (
list, optional) – list of files to be read. If None, then the file list is used that is returned onget_file_list().first_file (
int, optional) – index of first file in file list to read. If None, the very first file in the list is used. Note: is ignored if input parameter file_pattern is specified.last_file (
int, optional) – index of last file in list to read. If None, the very last file in the list is used. Note: is ignored if input parameter file_pattern is specified.file_pattern (str, optional) – string pattern for file search (cf
get_file_list())common_meta (dict, optional) – dictionary that contains additional metadata shared for this network (assigned to each metadata block of the
UngriddedDataobject that is returned)
- Returns:
data object
- Return type:
- read_file(filename, vars_to_retrieve=None, vars_as_series=False)[source]
Read Aeronet file containing results from v2 inversion algorithm
- Parameters:
- Returns:
dict-like object containing results
- Return type:
Example
>>> import pyaerocom.io as pio >>> obj = pio.read_aeronet_invv3.ReadAeronetInvV3() >>> files = obj.get_file_list() >>> filedata = obj.read_file(files[0])
- read_first_file(**kwargs)
Read first file returned from
get_file_list()Note
This method may be used for test purposes.
- Parameters:
**kwargs – keyword args passed to
read_file()(e.g. vars_to_retrieve)- Returns:
dictionary or similar containing loaded results from first file
- Return type:
dict-like
- read_station(station_id_filename, **kwargs)
Read data from a single station into
UngriddedDataFind all files that contain the station ID in their filename and then call
read(), providing the reduced filelist as input, in order to read all files from this station into data object.- Parameters:
- Returns:
loaded data
- Return type:
- Raises:
IOError – if no files can be found for this station ID
- remove_outliers(data, vars_to_retrieve, **valid_rng_vars)
Remove outliers from data
- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_retrieve (list) – list of variable names for which outliers will be removed from data
**valid_rng_vars – additional keyword args specifying variable name and corresponding min / max interval (list or tuple) that specifies valid range for the variable. For each variable that is not explicitly defined here, the default minimum / maximum value is used (accessed via
pyaerocom.const.VARS[var_name])
- var_supported(var_name)
Check if input variable is supported
- Parameters:
var_name (str) – AeroCom variable name or alias
- Raises:
VariableDefinitionError – if input variable is not supported by pyaerocom
- Returns:
True, if variable is supported by this interface, else False
- Return type:
EARLINET
European Aerosol Research Lidar Network (EARLINET)
- class pyaerocom.io.read_earlinet.ReadEarlinet(data_id=None, data_dir=None)[source]
Bases:
ReadUngriddedBaseInterface for reading of EARLINET data
- ALTITUDE_ID = 'altitude'
variable name of altitude in files
- AUX_FUNS = {}
Functions that are used to compute additional variables (i.e. one for each variable defined in AUX_REQUIRES)
- AUX_REQUIRES = {}
dictionary containing information about additionally required variables for each auxiliary variable (i.e. each variable that is not provided by the original data but computed on import)
- property AUX_VARS
List of auxiliary variables (keys of attr.
AUX_REQUIRES)Auxiliary variables are those that are not included in original files but are computed from other variables during import
- CLOUD_FILTERS = {'cirrus_contamination': 2, 'cloud_mask_type': 0}
- DEFAULT_VARS = ['bsc532aer', 'ec532aer']
default variables for read method
- ERR_VARNAMES = {'ec355aer': 'error_extinction', 'ec532aer': 'error_extinction'}
Variable names of uncertainty data
- EXCLUDE_CASES = ['cirrus.txt']
- IGNORE_META_KEYS = []
- KEEP_ADD_META = ['location', 'wavelength', 'zenith_angle', 'comment', 'shots', 'backscatter_evaluation_method']
Metadata keys from
META_NAMES_FILEthat are additional to standard keys defined inStationMetaDataand that are supposed to be inserted intoUngriddedDataobject created inread()
- META_NAMES_FILE = {'PI': 'PI', 'altitude': 'altitude', 'comment': 'comment', 'dataset_name': 'title', 'instrument_name': 'system', 'location': 'location', 'start_utc': 'measurement_start_datetime', 'stop_utc': 'measurement_stop_datetime', 'wavelength_emis': 'wavelength', 'website': 'references'}
- META_NEEDED = ['location', 'measurement_start_datetime', 'measurement_start_datetime']
metadata keys that are needed for reading (must be values in
META_NAMES_FILE)
- READ_ERR = True
If true, the uncertainties are also read (where available, cf. ERR_VARNAMES)
- property REVISION_FILE
Name of revision file located in data directory
- TS_TYPE = 'hourly'
- VAR_NAMES_FILE = {'bsc1064aer': 'backscatter', 'bsc355aer': 'backscatter', 'bsc532aer': 'backscatter', 'ec1064aer': 'extinction', 'ec355aer': 'extinction', 'ec532aer': 'extinction', 'zdust': 'DustLayerHeight'}
dictionary specifying the file column names (values) for each Aerocom variable (keys)
- VAR_PATTERNS_FILE = {'bsc1064aer': '_b1064', 'bsc355aer': '_b0355', 'bsc532aer': '_b0532', 'ec355aer': '_e0355', 'ec532aer': '_e0532'}
- VAR_UNIT_NAMES = {'altitude': 'units', 'backscatter': ['units'], 'dustlayerheight': ['units'], 'extinction': ['units']}
Attribute access names for unit reading of variable data
- check_vars_to_retrieve(vars_to_retrieve)
Separate variables that are in file from those that are computed
Some of the provided variables by this interface are not included in the data files but are computed within this class during data import (e.g. od550aer, ang4487aer).
The latter may require additional parameters to be retrieved from the file, which is specified in the class header (cf. attribute
AUX_REQUIRES).This function checks the input list that specifies all required variables and separates them into two lists, one that includes all variables that can be read from the files and a second list that specifies all variables that are computed in this class.
- compute_additional_vars(data, vars_to_compute)
Compute all additional variables
The computations for each additional parameter are done using the specified methods in
AUX_FUNS.- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_compute (list) – list of variable names that are supposed to be computed. Variables that are required for the computation of the variables need to be specified in
AUX_VARSand need to be available as data vectors in the provided data dictionary (key is the corresponding variable name of the required variable).
- Returns:
updated data object now containing also computed variables
- Return type:
- property data_dir: str
Location of the dataset
Note
This can be set explicitly when instantiating the class (e.g. if data is available on local machine). If unspecified, the data location is attempted to be inferred via
get_obsnetwork_dir()- Raises:
FileNotFoundError – if data directory does not exist or cannot be retrieved automatically
- Type:
- property data_id
ID of dataset
- property data_revision
Revision string from file Revision.txt in the main data directory
- exclude_files
files that are supposed to be excluded from reading
- excluded_files
files that were actually excluded from reading
- find_in_file_list(pattern=None)
Find all files that match a certain wildcard pattern
- Parameters:
pattern (
str, optional) – wildcard pattern that may be used to narrow down the search (e.g. usepattern=*Berlin*to find only files that contain Berlin in their filename)- Returns:
list containing all files in
filesthat match pattern- Return type:
- Raises:
IOError – if no matches can be found
- get_file_list(vars_to_retrieve=None, pattern=None)[source]
Perform recursive file search for all input variables
Note
Overloaded implementation of base class, since for Earlinet, the paths are variable dependent
- read(vars_to_retrieve=None, files=None, first_file=None, last_file=None, read_err=None, remove_outliers=True, pattern=None) UngriddedDataStructured[source]
Method that reads list of files as instance of
UngriddedData- Parameters:
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loadedfiles (
list, optional) – list of files to be read. If None, then the file list is used that is returned onget_file_list().first_file (
int, optional) – index of first file in file list to read. If None, the very first file in the list is usedlast_file (
int, optional) – index of last file in list to read. If None, the very last file in the list is usedread_err (bool) –
- if True, uncertainty data is also read (where available). If
unspecified (None), then the default is used (cf.
READ_ERR)- patternstr, optional
string pattern for file search (cf
get_file_list())
- Returns:
data object
- Return type:
- read_file(filename, vars_to_retrieve=None, read_err=None, remove_outliers=True)[source]
Read EARLINET file and return it as instance of
StationData- Parameters:
filename (str) – absolute path to filename to read
vars_to_retrieve (
list, optional) – list of str with variable names to read. If None, useDEFAULT_VARSread_err (bool) – if True, uncertainty data is also read (where available).
remove_outliers (bool) – if True, outliers are removed for each variable using the minimum and maximum attributes for that variable (accessed via pyaerocom.const.VARS[var_name]).
- Returns:
dict-like object containing results
- Return type:
- read_first_file(**kwargs)
Read first file returned from
get_file_list()Note
This method may be used for test purposes.
- Parameters:
**kwargs – keyword args passed to
read_file()(e.g. vars_to_retrieve)- Returns:
dictionary or similar containing loaded results from first file
- Return type:
dict-like
- read_station(station_id_filename, **kwargs)
Read data from a single station into
UngriddedDataFind all files that contain the station ID in their filename and then call
read(), providing the reduced filelist as input, in order to read all files from this station into data object.- Parameters:
- Returns:
loaded data
- Return type:
- Raises:
IOError – if no files can be found for this station ID
- remove_outliers(data, vars_to_retrieve, **valid_rng_vars)
Remove outliers from data
- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_retrieve (list) – list of variable names for which outliers will be removed from data
**valid_rng_vars – additional keyword args specifying variable name and corresponding min / max interval (list or tuple) that specifies valid range for the variable. For each variable that is not explicitly defined here, the default minimum / maximum value is used (accessed via
pyaerocom.const.VARS[var_name])
- var_supported(var_name)
Check if input variable is supported
- Parameters:
var_name (str) – AeroCom variable name or alias
- Raises:
VariableDefinitionError – if input variable is not supported by pyaerocom
- Returns:
True, if variable is supported by this interface, else False
- Return type:
EBAS
EBAS is a database with atmospheric measurement data hosted by the Norwegian Institute for Air Research. Declaration of AEROCOM variables in EBAS and associated information such as acceptable minimum and maximum values occurs in pyaerocom/data/variables.ini .
- class pyaerocom.io.read_ebas.ReadEbas(data_id=None, data_dir=None)[source]
Bases:
ReadUngriddedBaseInterface for reading EBAS data
- Parameters:
data_id – string specifying either of the supported datasets that are defined in
SUPPORTED_DATASETSdata_dir (str) – directory where data is located (NOTE: needs to point to the directory that contains the “ebas_file_index.sqlite3” file and not to the underlying directory “data” which contains the actual NASA Ames files.)
- ASSUME_AAE_SHIFT_WVL = 1.0
- ASSUME_AE_SHIFT_WVL = 1
- AUX_FUNS = {'ac550dryaer': <function compute_ac550dryaer>, 'ang4470dryaer': <function compute_ang4470dryaer_from_dry_scat>, 'proxydryhno3': <function compute_wetoxn_from_concprcpoxn>, 'proxydryhono': <function compute_wetoxn_from_concprcpoxn>, 'proxydryn2o5': <function compute_wetoxn_from_concprcpoxn>, 'proxydryna': <function compute_wetna_from_concprcpna>, 'proxydrynh3': <function compute_wetrdn_from_concprcprdn>, 'proxydrynh4': <function compute_wetrdn_from_concprcprdn>, 'proxydryno2': <function compute_wetoxn_from_concprcpoxn>, 'proxydryno2no2': <function compute_wetoxn_from_concprcpoxn>, 'proxydryno3c': <function compute_wetoxn_from_concprcpoxn>, 'proxydryno3f': <function compute_wetoxn_from_concprcpoxn>, 'proxydryo3': <function make_proxy_drydep_from_O3>, 'proxydryoxn': <function compute_wetoxn_from_concprcpoxn>, 'proxydryoxs': <function compute_wetoxs_from_concprcpoxs>, 'proxydrypm10': <function compute_wetoxs_from_concprcpoxs>, 'proxydrypm25': <function compute_wetoxs_from_concprcpoxs>, 'proxydryrdn': <function compute_wetrdn_from_concprcprdn>, 'proxydryso2': <function compute_wetoxs_from_concprcpoxs>, 'proxydryso4': <function compute_wetoxs_from_concprcpoxs>, 'proxydryss': <function compute_wetna_from_concprcpna>, 'proxywethno3': <function compute_wetoxn_from_concprcpoxn>, 'proxywethono': <function compute_wetoxn_from_concprcpoxn>, 'proxywetn2o5': <function compute_wetoxn_from_concprcpoxn>, 'proxywetnh3': <function compute_wetrdn_from_concprcprdn>, 'proxywetnh4': <function compute_wetrdn_from_concprcprdn>, 'proxywetno2': <function compute_wetoxn_from_concprcpoxn>, 'proxywetno2no2': <function compute_wetoxn_from_concprcpoxn>, 'proxywetno3c': <function compute_wetoxn_from_concprcpoxn>, 'proxywetno3f': <function compute_wetoxn_from_concprcpoxn>, 'proxyweto3': <function make_proxy_wetdep_from_O3>, 'proxywetoxn': <function compute_wetoxn_from_concprcpoxn>, 'proxywetoxs': <function compute_wetoxs_from_concprcpoxs>, 'proxywetpm10': <function compute_wetoxs_from_concprcpoxs>, 'proxywetpm25': <function compute_wetoxs_from_concprcpoxs>, 'proxywetrdn': <function compute_wetrdn_from_concprcprdn>, 'proxywetso2': <function compute_wetoxs_from_concprcpoxs>, 'proxywetso4': <function compute_wetoxs_from_concprcpoxs>, 'sc440dryaer': <function compute_sc440dryaer>, 'sc550dryaer': <function compute_sc550dryaer>, 'sc700dryaer': <function compute_sc700dryaer>, 'vmro3max': <function calc_vmro3max>, 'wetna': <function compute_wetna_from_concprcpna>, 'wetnh4': <function compute_wetnh4_from_concprcpnh4>, 'wetno3': <function compute_wetno3_from_concprcpno3>, 'wetoxn': <function compute_wetoxn_from_concprcpoxn>, 'wetoxs': <function compute_wetoxs_from_concprcpoxs>, 'wetoxsc': <function compute_wetoxs_from_concprcpoxsc>, 'wetoxst': <function compute_wetoxs_from_concprcpoxst>, 'wetrdn': <function compute_wetrdn_from_concprcprdn>, 'wetrdnpr': <function compute_wetrdnpr_from_concprcprdn>, 'wetso4': <function compute_wetso4_from_concprcpso4>}
Functions supposed to be used for computation of auxiliary variables
- AUX_REQUIRES = {'ac550dryaer': ['ac550aer', 'acrh'], 'ang4470dryaer': ['sc440dryaer', 'sc700dryaer'], 'proxydryhno3': ['concprcpoxn', 'pr'], 'proxydryhono': ['concprcpoxn', 'pr'], 'proxydryn2o5': ['concprcpoxn', 'pr'], 'proxydryna': ['concprcpna', 'pr'], 'proxydrynh3': ['concprcprdn', 'pr'], 'proxydrynh4': ['concprcprdn', 'pr'], 'proxydryno2': ['concprcpoxn', 'pr'], 'proxydryno2no2': ['concprcpoxn', 'pr'], 'proxydryno3c': ['concprcpoxn', 'pr'], 'proxydryno3f': ['concprcpoxn', 'pr'], 'proxydryo3': ['vmro3'], 'proxydryoxn': ['concprcpoxn', 'pr'], 'proxydryoxs': ['concprcpoxs', 'pr'], 'proxydrypm10': ['concprcpoxs', 'pr'], 'proxydrypm25': ['concprcpoxs', 'pr'], 'proxydryrdn': ['concprcprdn', 'pr'], 'proxydryso2': ['concprcpoxs', 'pr'], 'proxydryso4': ['concprcpoxs', 'pr'], 'proxydryss': ['concprcpna', 'pr'], 'proxywethno3': ['concprcpoxn', 'pr'], 'proxywethono': ['concprcpoxn', 'pr'], 'proxywetn2o5': ['concprcpoxn', 'pr'], 'proxywetnh3': ['concprcprdn', 'pr'], 'proxywetnh4': ['concprcprdn', 'pr'], 'proxywetno2': ['concprcpoxn', 'pr'], 'proxywetno2no2': ['concprcpoxn', 'pr'], 'proxywetno3c': ['concprcpoxn', 'pr'], 'proxywetno3f': ['concprcpoxn', 'pr'], 'proxyweto3': ['vmro3'], 'proxywetoxn': ['concprcpoxn', 'pr'], 'proxywetoxs': ['concprcpoxs', 'pr'], 'proxywetpm10': ['concprcpoxs', 'pr'], 'proxywetpm25': ['concprcpoxs', 'pr'], 'proxywetrdn': ['concprcprdn', 'pr'], 'proxywetso2': ['concprcpoxs', 'pr'], 'proxywetso4': ['concprcpoxs', 'pr'], 'sc440dryaer': ['sc440aer', 'scrh'], 'sc550dryaer': ['sc550aer', 'scrh'], 'sc700dryaer': ['sc700aer', 'scrh'], 'vmro3max': ['vmro3'], 'wetna': ['concprcpna', 'pr'], 'wetnh4': ['concprcpnh4', 'pr'], 'wetno3': ['concprcpno3', 'pr'], 'wetoxn': ['concprcpoxn', 'pr'], 'wetoxs': ['concprcpoxs', 'pr'], 'wetoxsc': ['concprcpoxsc', 'pr'], 'wetoxst': ['concprcpoxst', 'pr'], 'wetrdn': ['concprcprdn', 'pr'], 'wetrdnpr': ['pr'], 'wetso4': ['concprcpso4', 'pr']}
variables required for computation of auxiliary variables
- AUX_USE_META = {'ac550dryaer': 'ac550aer', 'sc440dryaer': 'sc440aer', 'sc550dryaer': 'sc550aer', 'sc700dryaer': 'sc700aer'}
Meta information supposed to be migrated to computed variables
- property AUX_VARS
List of auxiliary variables (keys of attr.
AUX_REQUIRES)Auxiliary variables are those that are not included in original files but are computed from other variables during import
- CACHE_SQLITE_FILE = ['EBASMC']
For the following data IDs, the sqlite database file will be cached if const.EBAS_DB_LOCAL_CACHE is True
- property DEFAULT_VARS
list of default variables to be read
Note
Currently a wrapper for
PROVIDES_VARIABLES- Type:
- property FILE_REQUEST_OPTS
List of options for file retrieval
- IGNORE_COLS_CONTAIN = ['fraction', 'artifact']
Ignore data columns in NASA Ames files that contain any of the listed attributes
- IGNORE_FILES = ['CA0420G.20100101000000.20190125102503.filter_absorption_photometer.aerosol_absorption_coefficient.aerosol.1y.1h.CA01L_Magee_AE31_ALT.CA01L_aethalometer.lev2.nas', 'DK0022R.20180101070000.20191014000000.bulk_sampler..precip.1y.15d.DK01L_bs_22.DK01L_IC.lev2.nas', 'DK0012R.20180101070000.20191014000000.bulk_sampler..precip.1y.15d.DK01L_bs_12.DK01L_IC.lev2.nas', 'DK0008R.20180101070000.20191014000000.bulk_sampler..precip.1y.15d.DK01L_bs_08.DK01L_IC.lev2.nas', 'DK0005R.20180101070000.20191014000000.bulk_sampler..precip.1y.15d.DK01L_bs_05.DK01L_IC.lev2.nas']
list of EBAS data files that are flagged invalid and will not be imported
- IGNORE_META_KEYS = []
- MERGE_STATIONS = {'Birkenes': 'Birkenes II', 'Rörvik': 'Råö', 'Vavihill': 'Hallahus', 'Virolahti II': 'Virolahti III'}
- property NAN_VAL
Irrelevant for implementation of EBAS I/O
- property PROVIDES_VARIABLES
List of variables provided by the interface
- property REVISION_FILE
Name of revision file located in data directory
- SQL_DB_NAME = 'ebas_file_index.sqlite3'
Name of sqlite database file
- TS_TYPE = 'undefined'
- TS_TYPE_CODES = {'1d': 'daily', '1h': 'hourly', '1mn': 'minutely', '1mo': 'monthly', '1w': 'weekly', 'd': 'daily', 'h': 'hourly', 'mn': 'minutely', 'mo': 'monthly', 'w': 'weekly'}
Temporal resolution codes that (so far) can be understood by pyaerocom
- VAR_READ_OPTS = {'pr': {'convert_units': False, 'freq_min_cov': 0.75}, 'prmm': {'freq_min_cov': 0.75}}
Custom reading options for individual variables. Keys need to be valid attributes of
ReadEbasOptionsand anything specified here (for a given variable) will be overwritten from the defaults specified in the options class.
- property all_station_names
List of all available station names in EBAS database
- check_vars_to_retrieve(vars_to_retrieve)
Separate variables that are in file from those that are computed
Some of the provided variables by this interface are not included in the data files but are computed within this class during data import (e.g. od550aer, ang4487aer).
The latter may require additional parameters to be retrieved from the file, which is specified in the class header (cf. attribute
AUX_REQUIRES).This function checks the input list that specifies all required variables and separates them into two lists, one that includes all variables that can be read from the files and a second list that specifies all variables that are computed in this class.
- compute_additional_vars(data, vars_to_compute)[source]
Compute additional variables and put into station data
Note
Extended version of
ReadUngriddedBase.compute_additional_vars()- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_compute (list) – list of variable names that are supposed to be computed. Variables that are required for the computation of the variables need to be specified in
AUX_VARSand need to be available as data vectors in the provided data dictionary (key is the corresponding variable name of the required variable).
- Returns:
updated data object now containing also computed variables
- Return type:
- property data_dir: str
Location of the dataset
Note
This can be set explicitly when instantiating the class (e.g. if data is available on local machine). If unspecified, the data location is attempted to be inferred via
get_obsnetwork_dir()- Raises:
FileNotFoundError – if data directory does not exist or cannot be retrieved automatically
- Type:
- property data_id
ID of dataset
- property data_revision
Revision string from file Revision.txt in the main data directory
- property file_dir
Directory containing EBAS NASA Ames files
- property file_index
SQlite file mapping metadata with filenames
- files_contain
this is filled in method get_file_list and specifies variables to be read from each file
- find_in_file_list(pattern=None)
Find all files that match a certain wildcard pattern
- Parameters:
pattern (
str, optional) – wildcard pattern that may be used to narrow down the search (e.g. usepattern=*Berlin*to find only files that contain Berlin in their filename)- Returns:
list containing all files in
filesthat match pattern- Return type:
- Raises:
IOError – if no matches can be found
- find_var_cols(vars_to_read, loaded_nasa_ames)[source]
Find best-match variable columns in loaded NASA Ames file
For each of the input variables, try to find one or more matches in the input NASA Ames file (loaded data object). If more than one match occurs, identify the best one (an example here is: user wants sc550aer and file contains scattering coefficients at 530 nm and 580 nm: in this case the 530 nm column will be used, cf. also accepted wavelength tolerance for reading of wavelength dependent variables
wavelength_tol_nm).- Parameters:
vars_to_read (list) – list of variables that are supposed to be read
loaded_nasa_ames (EbasNasaAmesFile) – loaded data object
- Returns:
dictionary specifying the best-match variable column for each of the input variables.
- Return type:
- get_file_list(vars_to_retrieve, **constraints)[source]
Get list of files for all variables to retrieve
- Parameters:
vars_to_retrieve (list or str) – list of variables that are supposed to be read
**constraints – further EBAS request constraints deviating from default (default info for each AEROCOM variable can be found in `ebas_config.ini < https://github.com/metno/pyaerocom/blob/master/pyaerocom/data/ ebas_config.ini>`__). For details on possible input parameters see
EbasSQLRequest(or this tutorial)
- Returns:
unified list of file paths each containing either of the specified variables
- Return type:
- get_read_opts(var_name)[source]
Get reading options for input variable
- Parameters:
var_name (str) – name of variable
- Returns:
options
- Return type:
EbasReadOptions
- read(vars_to_retrieve=None, first_file=None, last_file=None, files=None, **constraints)[source]
Method that reads list of files as instance of
UngriddedData- Parameters:
vars_to_retrieve (
listor similar, optional,) – list containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loadedfirst_file (
int, optional) – index of first file in file list to read. If None, the very first file in the list is usedlast_file (
int, optional) – index of last file in list to read. If None, the very last file in the list is usedfiles (list) – list of files
**constraints – further reading constraints deviating from default (default info for each AEROCOM variable can be found in `ebas_config.ini < https://github.com/metno/pyaerocom/blob/master/pyaerocom/data/ ebas_config.ini>`__). For details on possible input parameters see
EbasSQLRequest(or this tutorial)
- Returns:
data object
- Return type:
- read_file(filename, vars_to_retrieve=None, _vars_to_read=None, _vars_to_compute=None)[source]
Read EBAS NASA Ames file
- Parameters:
- Returns:
dict-like object containing results
- Return type:
- read_first_file(**kwargs)
Read first file returned from
get_file_list()Note
This method may be used for test purposes.
- Parameters:
**kwargs – keyword args passed to
read_file()(e.g. vars_to_retrieve)- Returns:
dictionary or similar containing loaded results from first file
- Return type:
dict-like
- read_station(station_id_filename, **kwargs)
Read data from a single station into
UngriddedDataFind all files that contain the station ID in their filename and then call
read(), providing the reduced filelist as input, in order to read all files from this station into data object.- Parameters:
- Returns:
loaded data
- Return type:
- Raises:
IOError – if no files can be found for this station ID
- property readopts_default
Default reading options
These are applied to all variables if not defined explicitly for individual variables in :attr:`REA
- remove_outliers(data, vars_to_retrieve, **valid_rng_vars)
Remove outliers from data
- Parameters:
data (dict-like) – data object containing data vectors for variables that are required for computation (cf. input param
vars_to_compute)vars_to_retrieve (list) – list of variable names for which outliers will be removed from data
**valid_rng_vars – additional keyword args specifying variable name and corresponding min / max interval (list or tuple) that specifies valid range for the variable. For each variable that is not explicitly defined here, the default minimum / maximum value is used (accessed via
pyaerocom.const.VARS[var_name])
- property sqlite_database_file
Path to EBAS SQL database
- var_supported(var_name)
Check if input variable is supported
- Parameters:
var_name (str) – AeroCom variable name or alias
- Raises:
VariableDefinitionError – if input variable is not supported by pyaerocom
- Returns:
True, if variable is supported by this interface, else False
- Return type:
- class pyaerocom.io.read_ebas.ReadEbasOptions(**args)[source]
Bases:
BrowseDictOptions for EBAS reading routine
- prefer_statistics
preferred order of data statistics. Some files may contain multiple columns for one variable, where each column corresponds to one of the here defined statistics that where applied to the data. This attribute is only considered for ebas variables, that have not explicitly defined what statistics to use (and in which preferred order, if applicable). Reading preferences for all Ebas variables are specified in the file ebas_config.ini in the data directory of pyaerocom.
- Type:
- ignore_statistics
columns that have either of these statistics applied are ignored for variable data reading.
- Type:
- wavelength_tol_nm
Wavelength tolerance in nm for reading of (wavelength dependent) variables. If multiple matches occur (e.g. query -> variable at 550nm but file contains 3 columns of that variable, e.g. at 520, 530 and 540 nm), then the closest wavelength to the queried wavelength is used within the specified tolerance level.
- Type:
- shift_wavelengths
(only for wavelength dependent variables). If True, and a data columns candidate is valid within wavelength tolerance around desired wavelength, that column will be considered to be used for data import. Defaults to True.
- Type:
assume an Angstrom Exponent for applying wavelength shifts of data. See
ReadEbas.ASSUME_AE_SHIFT_WVLandReadEbas.ASSUME_AAE_SHIFT_WVLfor AE and AAE assumptions related to scattering and absorption coeffs. Defaults to True.- Type:
- check_correct_MAAP_wrong_wvl
(BETA, do not use): set correct wavelength for certain absorption coeff measurements. Defaults to False.
- Type:
- eval_flags
If True, the flag columns in the NASA Ames files are read and decoded (using
EbasFlagCol.decode()) and the (up to 3 flags for each measurement) are evaluated as valid / invalid using the information in the flags CSV file. The evaluated flags are stored in the data files returned by the reading methodsReadEbas.read()andReadEbas.read_file().- Type:
- keep_aux_vars
if True, auxiliary variables required for computed variables will be written to the
UngriddedDataobject created inReadEbas.read()(e.g. if sc550dryaer is requested, this requires reading of sc550aer and scrh. The latter 2 will be written to the data object if this parameter evaluates to True)- Type:
- convert_units
if True, variable units in EBAS files will be checked and attempted to be converted into AeroCom default unit for that variable. Defaults to True.
- Type:
- try_convert_vmr_conc
attempt to convert vmr data to conc if user requires conc (e.g. user wants conco3 but file only contains vmro3), and vice versa.
- Type:
- ensure_correct_freq
if True, the frequency set in NASA Ames files (provided via attr resolution_code) is checked using time differences inferred from start and stop time of each measurement. Measurements that are not in that resolution (within 5% tolerance level) will be flagged invalid.
- Type:
- freq_from_start_stop_meas
infer frequency from start / stop intervals of individual measurements.
- Type:
- freq_min_cov
defines minimum number of measurements that need to correspond to the detected sampling frequency in the file within the specified tolerance range. Only applies if
ensure_correct_freqis True. E.g. if a file contains 100 measurements and the most common frequency (as inferred from stop-start of each measurement) is daily. Then, if freq_min_cov is 0.75, it will be ensured that at least 75 of the measurements are daily (within +/- 5% tolerance), otherwise this file is discarded. Defaults to 0.- Type:
- Parameters:
**args – key / value pairs specifying any of the supported settings.
- FORBIDDEN_KEYS = []
- clear() None. Remove all items from D.
- property filter_dict
- get(k[, d]) D[k] if k in D, else d. d defaults to None.
- items() a set-like object providing a view on D's items
- keys() a set-like object providing a view on D's keys
- pop(k[, d]) v, remove specified key and return the corresponding value.
If key is not found, d is returned if given, otherwise KeyError is raised.
- popitem() (k, v), remove and return some (key, value) pair
as a 2-tuple; but raise KeyError if D is empty.
- setdefault(k[, d]) D.get(k,d), also set D[k]=d if k not in D
- to_dict()
- update([E, ]**F) None. Update D from mapping/iterable E and F.
If E present and has a .keys() method, does: for k in E: D[k] = E[k] If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v In either case, this is followed by: for k, v in F.items(): D[k] = v
- values() an object providing a view on D's values
EBAS (low level)
Pyearocom module for reading and processing of EBAS NASA Ames files
For details on the file format see here
- class pyaerocom.io.ebas_nasa_ames.EbasColDef(name, is_var, is_flag, unit='1')[source]
Dict-like object for EBAS NASA Ames column definitions
Note
The meta attribute name ‘unit’ can also be accessed using the CF attr name ‘units’
- flag_col
column number of flag column that corresponds to this data column (only relevant if
is_varis True)- Type:
- Parameters:
name (str) – column name
is_var (bool) – True if column corresponds to variable data, False if not
is_flag (bool) – True, if column corresponds to Flag column, False if not
unit (
str, optional) – unit of data in column (if applicable)flag_col (
str, optional) –nameof flag column that corresponds to this data column (only relevant ifis_varis True)
- class pyaerocom.io.ebas_nasa_ames.EbasFlagCol(raw_data, interpret_on_init=True)[source]
Simple helper class to decode and interpret EBAS flag columns
- raw_data
raw flag column (containing X-digit floating point numbers)
- Type:
ndarray
- property FLAG_INFO
Detailed information about EBAS flag definitions
- property decoded
Nx3 numpy array containing decoded flag columns
- property valid
Boolean array specifying valid and invalid measurements
- class pyaerocom.io.ebas_nasa_ames.EbasNasaAmesFile(file=None, only_head=False, replace_invalid_nan=True, convert_timestamps=True, evaluate_flags=False, quality_check=True, **kwargs)[source]
EBAS NASA Ames file interface
Class interface for reading and processing of EBAS NASA Ames file
- time_stamps
array containing datetime64 objects with timestamps
- Type:
ndarray
- flags
dictionary containing
EbasFlagColobjects for each column containing flags- Type:
- Parameters:
file (
str, optional) – EBAS NASA Ames file. if valid file path, then the file is read on init (please note following options for import)only_head (bool) – read only file header
replace_invalid_nan (bool) – replace all invalid values in the table by NaNs. The invalid values for each dependent data column are identified based on the information in the file header.
convert_timestamps (bool) – compute array of numpy datetime64 timestamps from numeric timestamps in data
evaluate_flags (bool) – if True, all flags in all flag columns are decoded from floating point representation to 3 integers, e.g. 0.111222333 -> 111 222 333
quality_check (bool) – perform quality check after import (for details see
_quality_check())**kwargs – optional input args that are passed to init of
NasaAmesHeaderbase class
- ERR_HIGH_STATS = 'percentile:84.13'
- ERR_LOW_STATS = 'percentile:15.87'
- TIMEUNIT2SECFAC = {'Days': 86400, 'days': 86400}
- property base_date
Base date of data as numpy.datetime64[s]
- property col_names
Column names of table
- property col_names_vars
Names of all columns that are flagged as variables
- property col_num
Number of columns in table
- property col_nums_vars
Column index number of all variables
- property data
2D numpy array containing data table
- property data_header
- get_dt_meas(np_freq='s')[source]
Get array with time between individual measurements
This is computed based on start and timestamps, e.g. dt[0] = start[1] - start[0]
- Parameters:
np_freq (str) – string specifying output frequency of gap values
- Returns:
array with time-differences as floating point number in specified input resolution
- Return type:
ndarray
- get_time_gaps_meas(np_freq='s')[source]
Get array with time gaps between individual measurements
This is computed based on start and stop timestamps, e.g. =dt[0] = start[1] - stop[0]
- Parameters:
np_freq (str) – string specifying output frequency of gap values
- Returns:
array with time-differences as floating point number in specified input resolution
- Return type:
ndarray
- static numarr_to_datetime64(basedate, num_arr, mulfac_to_sec)[source]
Convert array of numerical timestamps into datetime64 array
- Parameters:
basedate (datetime64) – reference date
num_arr (ndarray) – numerical time stamps relative to basedate
mulfac_to_sec (float) – multiplicative factor to convert numerical values to unit of seconds
- Returns:
array containing timestamps as datetime64 objects
- Return type:
ndarray
- read_file(nasa_ames_file, only_head=False, replace_invalid_nan=True, convert_timestamps=True, evaluate_flags=False, quality_check=False)[source]
Read NASA Ames file
- Parameters:
nasa_ames_file (str) – EBAS NASA Ames file
only_head (bool) – read only file header
replace_invalid_nan (bool) – replace all invalid values in the table by NaNs. The invalid values for each dependent data column are identified based on the information in the file header.
convert_timestamps (bool) – compute array of numpy datetime64 timestamps from numeric timestamps in data
evaluate_flags (bool) – if True, all data columns get assigned their corresponding flag column, the flags in all flag columns are decoded from floating point representation to 3 integers, e.g. 0.111222333 -> 111 222 333 and if input
`replace_invalid_nan==True`, then the invalid measurements in each column are replaced with NaN’s.quality_check (bool) – perform quality check after import (for details see
_quality_check())
- property shape
Shape of data array
- property time_unit
Time unit of data
- class pyaerocom.io.ebas_nasa_ames.NasaAmesHeader(**kwargs)[source]
Header class for Ebas NASA Ames file
Note
Is used in
EbasNasaAmesFileand should not be used directly.- CONV_FLOAT()
- CONV_INT()
- CONV_MULTIFLOAT()
- CONV_MULTIINT()
- CONV_PI()
- CONV_STR()
- property head_fix
Dictionary containing fixed header info (that is always available)
- property meta
Meta data dictionary (specific for this file)
- property var_defs
List containing column variable definitions
List index is column index in file and value is instance of
EbasColDef
- class pyaerocom.io.ebas_file_index.EbasFileIndex(database=None)[source]
EBAS SQLite I/O interface
Takes care of connection to database and execution of requests
- property ALL_INSTRUMENTS
List of all variables available
- property ALL_MATRICES
List of all matrix values available
- property ALL_STATION_CODES
List of all available station codes in database
Note
Not tested whether the order is the same as the order in
STATION_NAMES, i.e. the lists should not be linked to each other
- property ALL_STATION_NAMES
List of all available station names in database
- property ALL_VARIABLES
List of all variables available
- property database
Path to ebas_file_index.sqlite3 file
- execute_request(request, file_request=False)[source]
Connect to database and retrieve data for input request
- Parameters:
request (
EbasSQLRequestorstr) – request specifications- Returns:
list of tuples containing the retrieved results. The number of items in each tuple corresponds to the number of requested parameters (usually one, can be specified in
make_query_str()using argumentwhat)- Return type:
- get_file_names(request)[source]
Get all files that match the request specifications
- Parameters:
request (
EbasSQLRequestorstr) – request specifications- Returns:
list of file paths that match the request
- Return type:
- class pyaerocom.io.ebas_file_index.EbasSQLRequest(variables=None, start_date=None, stop_date=None, station_names=None, matrices=None, altitude_range=None, lon_range=None, lat_range=None, instrument_types=None, statistics=None, datalevel=None)[source]
Low level dictionary like object for EBAS sqlite queries
- variables
tuple containing variable names to be extracted (e.g.
('aerosol_light_scattering_coefficient', 'aerosol_optical_depth')). If None, all available is used- Type:
tuple, optional
- start_date
start date of data request (format YYYY-MM-DD). If None, all available is used
- Type:
str, optional
- stop_date
stop date of data request (format YYYY-MM-DD). If None, all available is used
- Type:
str, optional
- station_names
tuple containing station_names of request (e.g.
('Birkenes II', 'Asa')).If None, all available is used- Type:
tuple, optional
- matrices
tuple containing station_names of request (e.g.
('pm1', 'pm10', 'pm25', 'aerosol')) If None, all available is used- Type:
tuple, optional
- altitude_range
tuple specifying altitude range of station in m (e.g.
(0.0, 500.0)). If None, all available is used- Type:
tuple, optional
- lon_range
tuple specifying longitude range of station in degrees (e.g.
(-20, 20)). If None, all available is used- Type:
tuple, optional
- lat_range
tuple specifying latitude range of station in degrees (e.g.
(50, 80)). If None, all available is used- Type:
tuple, optional
- Parameters:
Attributes (see)
- make_file_query_str(distinct=True, **kwargs)[source]
Wrapper for base method
make_query_str()
- class pyaerocom.io.ebas_varinfo.EbasVarInfo(var_name: str, init: bool = True, **kwargs)[source]
Interface for mapping between EBAS variable information and AeroCom
For more information about EBAS variable and data information see EBAS website.
- matrix
list of EBAS matrix values that are accepted, default is None, i.e. all available matrices are used
- Type:
list, optional
- requires
for variables that are computed and not directly available in EBAS. Provided as list of (AeroCom) variables that are required to compute
var_name(e.g. for sc550dryaer this would be [sc550aer,scrh]).- Type:
list, optional
- scale_factor
multiplicative scale factor that is applied in order to convert EBAS variable into AeroCom variable (e.g. 1.4 for conversion of EBAS OC measurement to AeroCom concoa variable)
- Type:
float, optional
- Parameters:
- instrument
list of instrument names (EBAS side, optional)
- make_sql_request(**constraints) EbasSQLRequest[source]
Create an SQL request for the specifications in this object
- Parameters:
constraints – request constraints deviating from default. For details on parameters see
EbasSQLRequest- Returns:
the SQL request object that can be used to retrieve corresponding file names using instance of
EbasFileIndex.get_file_names().- Return type:
- make_sql_requests(**constraints) list[EbasSQLRequest][source]
Create a list of SQL requests for the specifications in this object
- Parameters:
requests (dict, optional) – other SQL requests linked to this one (e.g. if this variable requires)
constraints – request constraints deviating from default. For details on parameters see
EbasSQLRequest
- Returns:
list of
EbasSQLRequestinstances for this component and potential required components.- Return type:
- matrix
list of matrix names (EBAS side, optional)
- parse_from_ini(var_name: str, conf_reader: ConfigParser | None = None)[source]
Parse EBAS info for input AeroCom variable (works also for aliases)
- Parameters:
var_name (str) – AeroCom variable name
conf_reader (ConfigParser) – open config parser object
- Raises:
VarNotAvailableError – if variable is not supported
- Returns:
True, if default could be loaded, False if not
- Return type:
- requires
list of additional variable required for retrieval of this variable
- scale_factor
scale factor for conversion to Aerocom units
- statistics
list containing variable statistics info (EBAS side, optional)
EEA data
EEA base reader
Reader for European air pollution data from EEA AqERep files.
Interface for reading EEA AqERep files (formerly known as Airbase data).
- class pyaerocom.io.read_eea_aqerep_base.ReadEEAAQEREPBase(data_id=None, data_dir=None)[source]
Class for reading EEA AQErep data
Extended class derived from low-level base class
ReadUngriddedBasethat contains some more functionality.Note
Currently only single variable reading into an
UngriddedDataobject is supported.- ALTITUDENAME = 'altitude'
name of altitude variable in metadata file
- AUX_FUNS = {'concNno': NotImplementedError(), 'concNno2': NotImplementedError(), 'concSso2': NotImplementedError(), 'vmrno2': NotImplementedError(), 'vmro3': NotImplementedError(), 'vmro3max': NotImplementedError()}
Functions that are used to compute additional variables (i.e. one for each variable defined in AUX_REQUIRES)
- AUX_REQUIRES = {'concNno': ['concno'], 'concNno2': ['concno2'], 'concSso2': ['concso2'], 'vmrno2': ['concno2'], 'vmro3': ['conco3'], 'vmro3max': ['conco3']}
dictionary containing information about additionally required variables for each auxiliary variable (i.e. each variable that is not provided by the original data but computed on import)
- CONV_FACTOR = {'concNno': np.float64(0.466788868521913), 'concNno2': np.float64(0.3044517868011477), 'concSso2': np.float64(0.50052292274792), 'vmrno2': np.float64(0.514), 'vmro3': np.float64(0.493), 'vmro3max': np.float64(0.493)}
- CONV_UNIT = {'concNno': 'µgN/m3', 'concNno2': 'µgN/m3', 'concSso2': 'µgS/m3', 'vmrno2': 'ppb', 'vmro3': 'ppb', 'vmro3max': 'ppb'}
- property DATASET_NAME
Name of the dataset
- DATA_PRODUCT = ''
- DEFAULT_METADATA_FILE = 'metadata.csv'
- property DEFAULT_VARS
List of default variables
- END_TIME_NAME = 'datetimeend'
filed name of the end time of the measurement (in lower case)
- FILE_COL_DELIM = ','
Column delimiter
- FILE_MASKS = {'concNno': '**/??_38_*_timeseries.csv*', 'concNno2': '**/??_8_*_timeseries.csv*', 'concSso2': '**/??_1_*_timeseries.csv*', 'concco': '**/??_10_*_timeseries.csv*', 'concno': '**/??_38_*_timeseries.csv*', 'concno2': '**/??_8_*_timeseries.csv*', 'conco3': '**/??_7_*_timeseries.csv*', 'concpm10': '**/??_5_*_timeseries.csv*', 'concpm25': '**/??_6001_*_timeseries.csv*', 'concso2': '**/??_1_*_timeseries.csv*', 'vmrno2': '**/??_8_*_timeseries.csv*', 'vmro3': '**/??_7_*_timeseries.csv*', 'vmro3max': '**/??_7_*_timeseries.csv*'}
file masks for the data files
- INSTRUMENT_NAME = 'unknown'
there’s no general instrument name in the data
- LATITUDENAME = 'latitude'
Name of latitude variable in metadata file
- LONGITUDENAME = 'longitude'
name of longitude variable in metadata file
- MAX_LINES_TO_READ = 8784
- NAN_VAL = {}
Dictionary specifying values corresponding to invalid measurements there’s no value for NaNs in this data set. It uses an empty string
- PROVIDES_VARIABLES: list[str] = ['concso2', 'conco3', 'concno2', 'concco', 'concno', 'concpm10', 'concpm25', 'vmro3', 'vmro3max', 'vmrno2', 'concSso2', 'concNno', 'concNno2']
List of variables that are provided by this dataset (will be extended by auxiliary variables on class init, for details see __init__ method of base class ReadUngriddedBase)
- START_TIME_NAME = 'datetimebegin'
field name of the start time of the measurement (in lower case)
- TS_TYPE = 'variable'
There is no global ts_type but it is specified in the data files…
- TS_TYPES_FILE = {'day': 'daily', 'hour': 'hourly'}
sampling frequencies found in data files
- VAR_CODES = {'1': 'concso2', '10': 'concco', '38': 'concno', '5': 'concpm10', '6001': 'concpm25', '7': 'conco3', '8': 'concno2'}
dictionary that connects the EEA variable codes with aerocom variable names
- VAR_CODE_NAME = 'airpollutantcode'
column name that holds the EEA variable code
- VAR_NAMES_FILE = {'concNno': 'concentration', 'concNno2': 'concentration', 'concSso2': 'concentration', 'concco': 'concentration', 'concno': 'concentration', 'concno2': 'concentration', 'conco3': 'concentration', 'concpm10': 'concentration', 'concpm25': 'concentration', 'concso2': 'concentration', 'vmrno2': 'concentration', 'vmro3': 'concentration', 'vmro3max': 'concentration'}
- VAR_UNITS_FILE = {'mg/m3': 'mg m-3', 'ppb': 'ppb', 'µg/m3': 'ug m-3', 'µgN/m3': 'ug N m-3', 'µgS/m3': 'ug S m-3'}
units of variables in files (needs to be defined for each variable supported)
- WEBSITE = 'https://discomap.eea.europa.eu/map/fme/AirQualityExport.htm'
this class reads the European Environment Agency’s Eionet data for details please read https://www.eea.europa.eu/about-us/countries-and-eionet
- get_file_list(pattern=None)[source]
Search all files to be read
Uses
_FILEMASK(+ optional input search pattern, e.g. station_name) to find valid files for query.
- get_station_coords(meta_key)[source]
get a station’s coordinates
- Parameters:
meta_key (str) – string with the internal station key
- read(vars_to_retrieve=None, files=None, first_file=None, last_file=None, metadatafile=None)[source]
Method that reads list of files as instance of
UngriddedData- Parameters:
vars_to_retrieve (
listor similar, optional) – List containing variable IDs that are supposed to be read. If None, all variables inPROVIDES_VARIABLESare loaded.files (
list, optional) – List of files to be read. If None, then the file list used is the returned fromget_file_list().first_file (
int, optional) – Index of the first file in :obj:’file’ to be read. If None, the very first file in the list is used.last_file (
int, optional) – Index of the last file in :obj:’file’ to be read. If None, the very last file in the list is used.metadatafile (:obj:'str', optional) – full qualified path to metadata file. If None, the default metadata file will be used
- Returns:
data object
- Return type:
EEA E2a product (NRT)
Near realtime EEA data.
Interface for reading EEA AqERep files (formerly known as Airbase data).
EEA E1a product (QC)
Quality controlled EEA data.
Interface for reading EEA AqERep files (formerly known as Airbase data).
AirNow data
Reader for air quality measurements from North America.
- class pyaerocom.io.read_airnow.ReadAirNow(data_id=None, data_dir=None)[source]
Reading routine for North-American Air Now observations
- BASEYEAR = 2000
- DEFAULT_VARS = ['concbc', 'concpm10', 'concpm25', 'vmrco', 'vmrnh3', 'vmrno', 'vmrno2', 'vmrnox', 'vmrnoy', 'vmro3', 'vmrso2']
Default variables
- FILE_COL_DELIM = '|'
Column delimiter
- FILE_COL_NAMES = ['date', 'time', 'station_id', 'station_name', 'time_zone', 'variable', 'unit', 'value', 'institute']
Columns in data files
- FILE_COL_ROW_NUMBER = 9
- PROVIDES_VARIABLES: list[str] = ['concbc', 'concpm10', 'concpm25', 'vmrco', 'vmrnh3', 'vmrno', 'vmrno2', 'vmrnox', 'vmrnoy', 'vmro3', 'vmrso2']
List of variables that are provided
- REPLACE_STATNAME = {'&': 'and', "'": '', '.': ' ', '/': ' ', ':': ' '}
- ROW_VAR_COL = 5
- STATION_META_DTYPES = {'address': <class 'str'>, 'altitude': <class 'float'>, 'area_classification': <class 'str'>, 'city': <class 'str'>, 'comment': <class 'str'>, 'latitude': <class 'float'>, 'longitude': <class 'float'>, 'modificationdate': <class 'str'>, 'station_classification': <class 'str'>, 'station_id': <class 'str'>, 'station_name': <class 'str'>, 'timezone': <class 'str'>}
conversion functions for metadata dtypes
- STATION_META_MAP = {'address': 'address', 'aqsid': 'station_id', 'city': 'city', 'comment': 'comment', 'elevation': 'altitude', 'environment': 'area_classification', 'lat': 'latitude', 'lon': 'longitude', 'modificationdate': 'modificationdate', 'name': 'station_name', 'populationclass': 'station_classification', 'timezone': 'timezone'}
Mapping of columns in station metadata file to pyaerocom standard
- STAT_METADATA_FILENAME = 'allStations_20191224.csv'
file containing station metadata
- TS_TYPE = 'hourly'
Frequency of measurements
- UNIT_MAP = {'C': 'celsius', 'M/S': 'm s-1', 'MILLIBAR': 'mbar', 'MM': 'mm', 'PERCENT': '%', 'PPB': 'ppb', 'PPM': 'ppm', 'UG/M3': 'ug m-3', 'WATTS/M2': 'W m-2'}
Units found in data files
- VAR_MAP = {'concbc': 'BC', 'concpm10': 'PM10', 'concpm25': 'PM2.5', 'vmrco': 'CO', 'vmrnh3': 'NH3', 'vmrno': 'NO', 'vmrno2': 'NO2', 'vmrnox': 'NOX', 'vmrnoy': 'NOY', 'vmro3': 'OZONE', 'vmrso2': 'SO2'}
Variable names in data files
- read(vars_to_retrieve=None, first_file=None, last_file=None)[source]
Read variable data
- Parameters:
vars_to_retrieve (str or list, optional) – List of variables to be retrieved. The default is None.
first_file (int, optional) – Index of first file to be read. The default is None, in which case index 0 in file list is used.
last_file (int, optional) – Index of last file to be read. The default is None, in which case last index in file list is used.
- Returns:
data – loaded data object.
- Return type:
- read_file(filename, vars_to_retrieve=None)[source]
This method is returns just the raw content of a file as a dict
- Parameters:
filename (str) – absolute path to filename to read
vars_to_retrieve (
list, optional) – list of str with variable names to read. If None, useDEFAULT_VARSvars_as_series (bool) – if True, the data columns of all variables in the result dictionary are converted into pandas Series objects
- Returns:
dict-like object containing results
- Return type:
- Raises:
- property station_metadata
Dictionary containing global metadata for each site
MarcoPolo data
Reader for air quality measurements for China from the EU-FP7 project MarcoPolo.
GHOST
GHOST (Globally Harmonised Observational Surface Treatment) project developed at the Earth Sciences Department of the Barcelona Supercomputing Center (see e.g., Petetin et al., 2020 for more information).
Further I/O features
Note
The pyaerocom.io package also includes all relevant data import and reading routines. These are introduced above, in Section reading.
AeroCom database browser
- class pyaerocom.io.aerocom_browser.AerocomBrowser(*args, **kwargs)[source]
Interface for browsing all Aerocom data directories
Note
Use
browse()to find directories matching a certain search pattern. The class methodsfind_matches()andfind_dir()both usebrowse(), the only difference is, that thefind_matches()adds the search result (a list with strings) to- property dirs_found
All directories that were found
- find_data_dir(name_or_pattern, ignorecase=True)[source]
Find match of input name or pattern in Aerocom database
- Parameters:
- Returns:
data directory of match
- Return type:
- Raises:
DataSearchError – if no matches or no unique match can be found
- find_matches(name_or_pattern, ignorecase=True)[source]
Search all Aerocom data directories that match input name or pattern
- Parameters:
- Returns:
list of names that match the pattern (corresponding paths can be accessed from this class instance)
- Return type:
- Raises:
DataSearchError – if no matches can be found
- property ids_found
All data IDs that were found
File naming conventions
Iris helpers
Module containing helper functions related to iris I/O methods. These contain reading of Cubes, and some methods to perform quality checks of the data, e.g.
checking and correction of time definition
number and length of dimension coordinates must match data array
Longitude definition from -180 to 180 (corrected if defined on 0 -> 360 interval)
- pyaerocom.io.iris_io.check_and_regrid_lons_cube(cube)[source]
Checks and corrects for if longitudes of
gridare 0 -> 360Note
This method checks if the maximum of the current longitudes array exceeds 180. Thus, it is not recommended to use this function after subsetting a cube, rather, it should be checked directly when the file is loaded (cf.
load_input())- Parameters:
cube (iris.cube.Cube) – gridded data loaded as iris.Cube
- Returns:
True, if longitudes were on 0 -> 360 and have been rolled, else False
- Return type:
- pyaerocom.io.iris_io.check_dim_coords_cube(cube)[source]
Checks, and if necessary and applicable, updates coords names in Cube
- Parameters:
cube (iris.cube.Cube) – input cube
- Returns:
updated or unchanged cube
- Return type:
iris.cube.Cube
- pyaerocom.io.iris_io.check_time_coord(cube, ts_type, year)[source]
Method that checks the time coordinate of an iris Cube
This method checks if the time dimension of a cube is accessible and according to the standard (i.e. fully usable). It only checks, and does not correct. For the latter, please see
correct_time_coord().
- pyaerocom.io.iris_io.concatenate_iris_cubes(cubes, error_on_mismatch=True)[source]
Concatenate list of
iris.Cubeinstances cubes into single CubeHelper method for concatenating list of cubes
This method is not supposed to be called directly but rather
concatenate_cubes()(which ALWAYS returns instance ofCubeor raises Exception) orconcatenate_possible_cubes()(which ALWAYS returns instance ofCubeListor raises Exception)- Parameters:
cubes (CubeList or list(Cubes)) – list of individual cubes
error_on_mismatch – boolean specifying whether an Exception is supposed to be raised or not
- Returns:
result of concatenation
- Return type:
Cube- Raises:
iris.exceptions.ConcatenateError – if
error_on_mismatch=Trueand input cubes could not all concatenated into a single instance ofiris.Cubeclass.
- pyaerocom.io.iris_io.correct_time_coord(cube, ts_type, year)[source]
Method that corrects the time coordinate of an iris Cube
- Parameters:
- Returns:
the same instance of the input cube with corrected time dimension axis
- Return type:
Cube
- pyaerocom.io.iris_io.load_cube_custom(file, var_name=None, file_convention=None, perform_fmt_checks=None)[source]
Load netcdf file as iris.Cube
- Parameters:
file (str) – netcdf file
var_name (str) – name of variable to read
quality_check (bool) – if True, then a quality check of data is performed against the information provided in the filename
file_convention (
FileConventionRead, optional) – Aerocom file convention. If provided, then the data content (e.g. dimension definitions) is tested against definition in file nameperform_fmt_checks (bool) – if True, additional quality checks (and corrections) are (attempted to be) performed.
- Returns:
loaded data as Cube
- Return type:
iris.cube.Cube
- pyaerocom.io.iris_io.load_cubes_custom(files, var_name=None, file_convention=None, perform_fmt_checks=True)[source]
Load multiple NetCDF files into CubeList
Note
This function does not apply any concatenation or merging of the variable data in the individual files, it only loads the files into individual instances of
iris.cube.Cube, which can be accessed via the returned list.- Parameters:
files (list) – list of netcdf file paths
var_name (str) – name of variable to be imported from input files.
file_convention (
FileConventionRead, optional) – Aerocom file convention. If provided, then the data content (e.g. dimension definitions) is tested against definition in file nameperform_fmt_checks (bool) – if True, additional quality checks (and corrections) are (attempted to be) performed.
- Returns:
list – loaded cube instances.
list – list containing all files from which the input variable could be successfully loaded.
- pyaerocom.io.aux_read_cubes.add_cubes(cube1, cube2)[source]
Method to add cubes from 2 gridded data objects
- pyaerocom.io.aux_read_cubes.apply_rh_thresh_cubes(cube, rh_cube, rh_max=None)[source]
Method that applies a low RH filter to input cube
- pyaerocom.io.aux_read_cubes.compute_angstrom_coeff_cubes(cube1, cube2, lambda1=None, lambda2=None)[source]
Compute Angstrom coefficient cube based on 2 optical densitiy cubes
- Parameters:
cube1 (iris.cube.Cube) – AOD at wavelength 1
cube2 (iris.cube.Cube) – AOD at wavelength 2
lambda1 (float) – wavelength 1
2 (lambda) – wavelength 2
- Returns:
Cube containing Angstrom exponent(s)
- Return type:
Cube
- pyaerocom.io.aux_read_cubes.divide_cubes(cube1, cube2)[source]
Method to divide 2 cubes with each other
- pyaerocom.io.aux_read_cubes.lifetime_from_load_and_dep(load, wetdep, drydep)[source]
Compute lifetime from load and wet and dry deposition
- pyaerocom.io.aux_read_cubes.mmr_from_vmr(cube)[source]
Convvert gas volume/mole mixing ratios into mass mixing ratios.
- Parameters:
cube (iris.cube.Cube) – A cube containing gas vmr data to be converted into mmr.
- Returns:
cube_out – Cube containing mmr data.
- Return type:
iris.cube.Cube
- pyaerocom.io.aux_read_cubes.mmr_to_vmr_cube(data)[source]
Convert cube containing MMR data to VMR
- Parameters:
data (iris.Cube or GriddedData) – input data object containing MMR data for a certain variable. Needs to have var_name attr. assigned and valid MMR AeroCom variable name (e.g. mmro3, mmrno2)
- Raises:
AttributeError – if attr. var_name of input data does not start with mmr
- Returns:
cube containing mixing ratios expressed as VMR in units of nmole mole-1
- Return type:
iris.Cube
Handling of cached ungridded data objects
Caching class for reading and writing of ungridded data Cache objects
- class pyaerocom.io.cachehandler_ungridded.CacheHandlerUngridded(reader=None, cache_dir=None, **kwargs)[source]
Interface for reading and writing of cache files
Cache filename mask is
<data_id>_<var>.pkl
e.g. EBASMC_scatc550aer.pkl
- reader
reading class for dataset
- Type:
- loaded_data
dictionary containing successfully loaded instances of single variable
UngriddedDataobjects (keys are variable names)- Type:
- CACHE_HEAD_KEYS = ['pyaerocom_version', 'newest_file_in_read_dir', 'newest_file_date_in_read_dir', 'data_revision', 'reader_version', 'ungridded_data_class', 'ungridded_data_version', 'cacher_version']
Cache file header keys that are checked (and required unchanged) when reading a cache file
- property cache_dir
Directory where cache data objects are stored
- check_and_load(var_or_file_name, force_use_outdated=False, cache_dir=None)[source]
Check if cache file exists and load
Note
If a cache file exists for this database, but cannot be loaded or is outdated against pyaerocom updates, then it will be removed (the latter only if
pyaerocom.const.RM_CACHE_OUTDATEDis True).- Parameters:
var_or_file_name (str) – name of output filename or variable that is supposed to be stored. Default usage is to provide variable and then
default_file_name()is used. Can be None if input data contains only a single variable.eadforce_use_outdated (bool) – if True, read existing cache file even if it is not up to date or pyaerocom version changed (not recommended to use)
cache_dir (str, optional) – output directory (default is pyaerocom cache dir accessed via
cache_dir()).
- Returns:
True, if cache file exists and could be successfully loaded, else False. Note: if import is successful, the corresponding data object (instance of
pyaerocom.UngriddedDatacan be accessed via :attr:`loaded_data’- Return type:
- Raises:
TypeError – if cached file is not an instance of
pyaerocom.UngriddedDataclass (which should not happen)
- property data_id
Data ID of the associated dataset
- file_path(var_or_file_name, cache_dir=None)[source]
File path of cache file
- Parameters:
var_or_file_name (str) – name of output filename or variable that is supposed to be stored. Default usage is to provide variable and then
default_file_name()is used. Can be None if input data contains only a single variable.cache_dir (str, optional) – output directory (default is pyaerocom cache dir accessed via
cache_dir()).
- Returns:
output file path
- Return type:
- property reader
Instance of reader class
- property src_data_dir
Data source directory of the associated dataset
Needed to check whether an existing cache file is outdated
- write(data: UngriddedDataContainer, var_or_file_name=None, cache_dir=None)[source]
Write single-variable instance of UngriddedData to cache
- Parameters:
data (UngriddedDataContainer) – object containing the data (possibly containing multiple variables)
var_or_file_name (str, optional) – name of output filename or variable that is supposed to be stored. Default usage is to provide variable and then
default_file_name()is used. Can be None if input data contains only a single variable.cache_dir (str, optional) – output directory (default is pyaerocom cache dir accessed via
cache_dir()).
- Returns:
output file path
- Return type:
I/O utils
High level I/O utility methods for pyaerocom
- pyaerocom.io.utils.browse_database(model_or_obs, verbose=False)[source]
Browse Aerocom database using model or obs ID (or wildcard)
Searches database for matches and prints information about all matches found (e.g. available variables, years, etc.)
- Parameters:
- Returns:
list with data_ids of all matches
- Return type:
Example
>>> import pyaerocom as pya >>> pya.io.utils.browse_database('AATSR*ORAC*v4*') Pyaerocom ReadGridded --------------------- Data ID: AATSR_ORAC_v4.02 ...
I/O helpers
I/O helper methods of the pyaerocom package
- pyaerocom.io.helpers.COUNTRY_CODE_FILE = 'country_codes.json'
country code file name will be prepended with the path later on
- pyaerocom.io.helpers.add_file_to_log(filepath, err_msg)[source]
Add input file path to error logdir
The logdir location can be accessed via
pyaerocom.const.LOGFILESDIR
- pyaerocom.io.helpers.aerocom_savename(data_id, var_name, vert_code, year, ts_type)[source]
Generate filename in AeroCom conventions
ToDo: complete docstring
- pyaerocom.io.helpers.get_all_supported_ids_ungridded()[source]
Get list of datasets that are supported by
ReadUngridded- Returns:
list with supported network names
- Return type:
- pyaerocom.io.helpers.get_country_name_from_iso(iso_code: str | None = None, filename: str | Path | None = None, return_as_dict: bool = False)[source]
get the country name from the 2 digit iso country code
the underlaying json file was taken from this github repository https://github.com/lukes/ISO-3166-Countries-with-Regional-Codes
- Parameters:
iso_code (
str) – string containing the 2 character iso code of the country (e.g. no for Norway)filename (
str, optional) – optional string with the json file to readreturn_as_dict (
bool, optional) – flag to get the entire list of countries as a dictionary with the country codes as keys and the country names as value Useful if you have to get the names for a lot of country codes
- Returns:
string with country name or dictionary with iso codes as keys and the country names as values
empty string if the country code was not found
- Raises:
ValueError – if the country code ins invalid
- pyaerocom.io.helpers.get_metadata_from_filename(filename)[source]
Try access metadata information from filename
- pyaerocom.io.helpers.get_obsnetwork_dir(obs_id)[source]
Returns data path for obsnetwork ID
- Parameters:
obs_id (str) – ID of obsnetwork (e.g. AeronetSunV2Lev2.daily)
- Returns:
corresponding directory from
pyaerocom.const- Return type:
- Raises:
ValueError – if obs_id is invalid
IOError – if directory does not exist
- pyaerocom.io.helpers.get_standard_name(var_name)[source]
Get standard name of aerocom variable
- Parameters:
var_name (str) – HTAP2 variable name
- Returns:
corresponding standard name
- Return type:
- Raises:
VarNotAvailableError – if input variable is not defined in variables.ini file
VariableDefinitionError – if standarad name is not set for variable in variables.ini file
Metadata and vocabulary standards
- class pyaerocom.metastandards.AerocomDataID(data_id=None, **meta_info)[source]
Class representing a model data ID following AeroCom PhaseIII conventions
The ID must contain 4 substrings with meta parameters:
<ModelName>-<MeteoConfigSpecifier>_<ExperimentName>-<PerturbationName>
E.g.
NorESM2-met2010_CTRL-AP3
For more information see AeroCom diagnostics spreadsheet
This interface can be used to make sure a provided data ID is following this convention and to extract the corresponding meta parameters as dictionary (
to_dict()) or to create an data_id from the corresponding meta parametersfrom_dict().- DELIM = '_'
- KEYS = ['model_name', 'meteo', 'experiment', 'perturbation']
- SUBDELIM = '-'
- property data_id
str AeroCom data ID
- static from_dict(meta)[source]
Create instance of AerocomDataID from input meta dictionary
- static from_values(values)[source]
Create data_id from list of values
Note
The values have to be in the right order, cf.
KEYS- Parameters:
- Raises:
ValueError – if length of input list mismatches length of
KEYS- Returns:
generated data_id
- Return type:
- to_dict()[source]
Convert data_id to dictionary
- Returns:
dictionary with metadata information
- Return type:
- property values
- class pyaerocom.metastandards.DataSource(**info)[source]
Dict-like object defining a data source
- data_id
name (or ID) of dataset (e.g. AeronetSunV3Lev2.daily)
- dataset_name
name of dataset (e.g. AERONET)
- data_product
data product (e.g. SDA, Inv, Sun for Aeronet)
- data_version
version of data (e.g. 3)
- data_level
level of data (e.g. 2)
- revision_date
last revision date of dataset
- ts_type_src
sampling frequency as defined in data files (use None if undefined)
- stat_merge_pref_attr
optional, a metadata attribute that is available in data and that is used to order the individual stations by relevance in case overlaps occur. The associated values of this attribute need to be sortable (e.g. revision_date). This is only relevant in case overlaps occur.
- Type:
- SUPPORTED_VERT_LOCS = ['ground', 'space', 'airborne']
- property data_dir
Directory containing data files
- class pyaerocom.metastandards.StationMetaData(**info)[source]
This object defines a standard for station metadata in pyaerocom
Variable names associated with meta data can vary significantly between different conventions (e.g. conventions in modellers community vs. observations community).
Note
This object is a dictionary and can be easily expanded
In many cases, only some of the attributes are relevant
- station_name
name or ID of a station. Note, that the concept of a station in pyaerocom is not necessarily related to a fixed coordinate. A station can also be a satellite, ship, or a human walking around and measuring something
- Type:
- ts_type
frequency of data (e.g. monthly). Note the difference between
ts_type_srcofDataSource, which specifies the freq. of the original files.- Type:
Variables
Variable collection
- class pyaerocom.variable.Variable(var_name=None, init=True, cfg=None, **kwargs)[source]
Interface that specifies default settings for a variable
See variables.ini file for an overview of currently available default variables.
- Parameters:
var_name (str) – string ID of variable (see file variables.ini for valid IDs)
init (bool) – if True, input variable name is attempted to be read from config file
cfg (ConfigParser) – open config parser that holds the information in config file available (i.e.
ConfigParser.read()has been called with config file as input)**kwargs – any valid class attribute (e.g. map_vmin, map_vmax, …)
- var_name_aerocom
AEROCOM variable name (see e.g. AEROCOM protocol for a list of available variables)
- Type:
- is_dry
flag that is set based on filename that indicates if variable data corresponds to dry conditions.
- Type:
- default_vert_code
default vertical code to be loaded (i.e. Column, ModelLevel, Surface). Only relevant during reading and in case conflicts occur (e.g. abs550aer, 2010, Column and Surface files)
- Type:
str, optional
- obs_wavelength_tol_nm
wavelength tolerance (+/-) for reading of obsdata. Default is 10, i.e. if this variable is defined at 550 nm and obsdata contains measured values of this quantity within interval of 540 - 560, then these data is used
- Type:
float literal_eval_list = lambda val: list(literal_eval(val))
- map_vmin
data value corresponding to lower end of colormap in map plots of this quantity
- Type:
- map_vmax
data value corresponding to upper end of colormap in map plots of this quantity
- Type:
- ALT_NAMES = {'unit': 'units'}
- VMAX_DEFAULT = inf
- VMIN_DEFAULT = -inf
- property aliases
Alias variable names that are frequently found or used
- Returns:
list containing valid aliases
- Return type:
- get_cmap_bins(infer_if_missing=True)[source]
Get cmap discretisation bins
- Parameters:
infer_if_missing (bool) – if True and
map_cbar_levelsis not defined, try to infer using_cmap_bins_from_vmin_vmax().- Raises:
AttributeError – if unavailable
- Returns:
levels
- Return type:
- property has_unit
Boolean specifying whether variable has unit
- property is_3d
True if str ‘3d’ is contained in
var_name_input
- property is_alias
- property is_at_dry_conditions
Indicate whether variable denotes dry conditions
- property is_deposition
Indicates whether input variables is a deposition rate
Note
This function only identifies wet and dry deposition based on the variable names, there might be other variables that are deposition variables but cannot be identified by this function.
- property is_emission
Indicates whether input variables is an emission rate
Note
This function only identifies wet and dry deposition based on the variable names, there might be other variables that are deposition variables but cannot be identified by this function.
- property is_rate
Indicates whether variable name is a rate
Rates include e.g. deposition or emission rate variables but also precipitation
- Returns:
True if variable is rate, else False
- Return type:
- property is_wavelength_dependent
Indicates whether this variable is wavelength dependent
- property long_name
Wrapper for
description
- property plot_info
Dictionary containing plot information
- plot_info_keys = ['scat_xlim', 'scat_ylim', 'scat_loglog', 'scat_scale_factor', 'map_vmin', 'map_vmax', 'map_cmap', 'map_c_under', 'map_c_over', 'map_cbar_levels', 'map_cbar_ticks']
- property unit
Unit of variable (old name, deprecated)
- property unit_str
string representation of unit
- property upper_limit
Old attribute name for
maximum(following HTAP2 defs)
- property var_name_aerocom
AeroCom variable name of the input variable
- property var_name_info
- property var_name_input
Input variable
Variable class
- class pyaerocom.variable.Variable(var_name=None, init=True, cfg=None, **kwargs)[source]
Interface that specifies default settings for a variable
See variables.ini file for an overview of currently available default variables.
- Parameters:
var_name (str) – string ID of variable (see file variables.ini for valid IDs)
init (bool) – if True, input variable name is attempted to be read from config file
cfg (ConfigParser) – open config parser that holds the information in config file available (i.e.
ConfigParser.read()has been called with config file as input)**kwargs – any valid class attribute (e.g. map_vmin, map_vmax, …)
- var_name_aerocom
AEROCOM variable name (see e.g. AEROCOM protocol for a list of available variables)
- Type:
- is_dry
flag that is set based on filename that indicates if variable data corresponds to dry conditions.
- Type:
- default_vert_code
default vertical code to be loaded (i.e. Column, ModelLevel, Surface). Only relevant during reading and in case conflicts occur (e.g. abs550aer, 2010, Column and Surface files)
- Type:
str, optional
- obs_wavelength_tol_nm
wavelength tolerance (+/-) for reading of obsdata. Default is 10, i.e. if this variable is defined at 550 nm and obsdata contains measured values of this quantity within interval of 540 - 560, then these data is used
- Type:
float literal_eval_list = lambda val: list(literal_eval(val))
- map_vmin
data value corresponding to lower end of colormap in map plots of this quantity
- Type:
- map_vmax
data value corresponding to upper end of colormap in map plots of this quantity
- Type:
- ALT_NAMES = {'unit': 'units'}
- VMAX_DEFAULT = inf
- VMIN_DEFAULT = -inf
- property aliases
Alias variable names that are frequently found or used
- Returns:
list containing valid aliases
- Return type:
- get_cmap_bins(infer_if_missing=True)[source]
Get cmap discretisation bins
- Parameters:
infer_if_missing (bool) – if True and
map_cbar_levelsis not defined, try to infer using_cmap_bins_from_vmin_vmax().- Raises:
AttributeError – if unavailable
- Returns:
levels
- Return type:
- property has_unit
Boolean specifying whether variable has unit
- property is_3d
True if str ‘3d’ is contained in
var_name_input
- property is_alias
- property is_at_dry_conditions
Indicate whether variable denotes dry conditions
- property is_deposition
Indicates whether input variables is a deposition rate
Note
This function only identifies wet and dry deposition based on the variable names, there might be other variables that are deposition variables but cannot be identified by this function.
- property is_emission
Indicates whether input variables is an emission rate
Note
This function only identifies wet and dry deposition based on the variable names, there might be other variables that are deposition variables but cannot be identified by this function.
- property is_rate
Indicates whether variable name is a rate
Rates include e.g. deposition or emission rate variables but also precipitation
- Returns:
True if variable is rate, else False
- Return type:
- property is_wavelength_dependent
Indicates whether this variable is wavelength dependent
- property long_name
Wrapper for
description
- property plot_info
Dictionary containing plot information
- plot_info_keys = ['scat_xlim', 'scat_ylim', 'scat_loglog', 'scat_scale_factor', 'map_vmin', 'map_vmax', 'map_cmap', 'map_c_under', 'map_c_over', 'map_cbar_levels', 'map_cbar_ticks']
- property unit
Unit of variable (old name, deprecated)
- property unit_str
string representation of unit
- property upper_limit
Old attribute name for
maximum(following HTAP2 defs)
- property var_name_aerocom
AeroCom variable name of the input variable
- property var_name_info
- property var_name_input
Input variable
Variable helpers
- pyaerocom.variable_helpers.get_aliases(var_name: str, parser: ConfigParser | None = None)[source]
Get aliases for a certain variable
Variable name info
- class pyaerocom.varnameinfo.VarNameInfo(var_name)[source]
This class can be used to retrieve information from variable names
- DEFAULT_VERT_CODE_PATTERNS = {'abs*': 'Column', 'ang*': 'Column', 'dry*': 'Surface', 'emi*': 'Surface', 'load*': 'Column', 'od*': 'Column', 'wet*': 'Surface'}
- PATTERNS = {'od': 'od\\d+aer'}
- property contains_numbers
Boolean specifying whether this variable name contains numbers
- property contains_wavelength_nm
Boolean specifying whether this variable contains a certain wavelength
- in_wavelength_range(low, high)[source]
Boolean specifying whether variable is within wavelength range
- property is_wavelength_dependent
Boolean specifying whether this variable name is wavelength dependent
- translate_to_wavelength(to_wavelength)[source]
Create new variable name at a different wavelength
- Parameters:
to_wavelength (float) – new wavelength in nm
- Returns:
new variable name
- Return type:
- property wavelength_nm
Wavelength in nm (if applicable)
Helpers for auxiliary variables
- pyaerocom.aux_var_helpers.calc_abs550aer(data)[source]
Compute AOD at 550 nm using Angstrom coefficient and 500 nm AOD
- Parameters:
data (dict-like) – data object containing imported results
- Returns:
AOD(s) at shifted wavelength
- Return type:
floatorndarray
- pyaerocom.aux_var_helpers.calc_ang4487aer(data)[source]
Compute Angstrom coefficient (440-870nm) from 440 and 870 nm AODs
- Parameters:
data (dict-like) – data object containing imported results
Note
Requires the following two variables to be available in provided data object:
od440aer
od870aer
- Raises:
AttributeError – if either ‘od440aer’ or ‘od870aer’ are not available in data object
- Returns:
array containing computed angstrom coefficients
- Return type:
ndarray
- pyaerocom.aux_var_helpers.calc_od550aer(data)[source]
Compute AOD at 550 nm using Angstrom coefficient and 500 nm AOD
- Parameters:
data (dict-like) – data object containing imported results
- Returns:
AOD(s) at shifted wavelength
- Return type:
floatorndarray
- pyaerocom.aux_var_helpers.calc_od550gt1aer(data)[source]
Compute coarse mode AOD at 550 nm using Angstrom coeff. and 500 nm AOD
- Parameters:
data (dict-like) – data object containing imported results
- Returns:
AOD(s) at shifted wavelength
- Return type:
float or ndarray
- pyaerocom.aux_var_helpers.calc_od550lt1aer(data)[source]
Compute fine mode AOD at 550 nm using Angstrom coeff. and 500 nm AOD
- Parameters:
data (dict-like) – data object containing imported results
- Returns:
AOD(s) at shifted wavelength
- Return type:
floatorndarray
- pyaerocom.aux_var_helpers.calc_od550lt1ang(data)[source]
- Compute AOD at 550 nm using Angstrom coeff. and 500 nm AOD,
that is filtered for angstrom coeff < 1 to get AOD representative of coarse particles.
- Parameters:
data (dict-like) – data object containing imported results
- Returns:
AOD(s) at shifted wavelength
- Return type:
floatorndarray
- pyaerocom.aux_var_helpers.compute_ac550dryaer(data)[source]
Compute aerosol dry absorption coefficient applying RH threshold
Cf.
_compute_dry_helper()- Parameters:
dict – data object containing scattering and RH data
- Returns:
modified data object containing new column sc550dryaer
- Return type:
- pyaerocom.aux_var_helpers.compute_ang4470dryaer_from_dry_scat(data)[source]
Compute angstrom exponent between 440 and 700 nm
- Parameters:
dict (StationData or) – data containing dry scattering coefficients at 440 and 700 nm (i.e. keys sc440dryaer and sc700dryaer)
- Returns:
extended data object containing angstrom exponent
- Return type:
StationData or dict
- pyaerocom.aux_var_helpers.compute_angstrom_coeff(od1, od2, lambda1, lambda2)[source]
Compute Angstrom coefficient based on 2 optical densities
- pyaerocom.aux_var_helpers.compute_od_from_angstromexp(to_lambda, od_ref, lambda_ref, angstrom_coeff)[source]
Compute AOD at specified wavelength
Uses Angstrom coefficient and reference AOD to compute the corresponding wavelength shifted AOD
- Parameters:
- Returns:
AOD(s) at shifted wavelength
- Return type:
floatorndarray
- pyaerocom.aux_var_helpers.compute_sc440dryaer(data)[source]
Compute dry scattering coefficient applying RH threshold
Cf.
_compute_dry_helper()- Parameters:
dict – data object containing scattering and RH data
- Returns:
modified data object containing new column sc550dryaer
- Return type:
- pyaerocom.aux_var_helpers.compute_sc550dryaer(data)[source]
Compute dry scattering coefficient applying RH threshold
Cf.
_compute_dry_helper()- Parameters:
dict – data object containing scattering and RH data
- Returns:
modified data object containing new column sc550dryaer
- Return type:
- pyaerocom.aux_var_helpers.compute_sc700dryaer(data)[source]
Compute dry scattering coefficient applying RH threshold
Cf.
_compute_dry_helper()- Parameters:
dict – data object containing scattering and RH data
- Returns:
modified data object containing new column sc550dryaer
- Return type:
- pyaerocom.aux_var_helpers.compute_wetoxn_from_concprcpoxn(data)[source]
Compute wdep from conc in precip and precip data
Note
In addition to the returned numpy array, the input instance of
StationDatais modified by additional metadata and flags for the new variable. See also_compute_wdep_from_concprcp_helper().- Parameters:
StationData – data object containing concprcp and precip data
- Returns:
array with wet deposition values
- Return type:
- pyaerocom.aux_var_helpers.compute_wetoxs_from_concprcpoxs(data)[source]
Compute wdep from conc in precip and precip data
Note
In addition to the returned numpy array, the input instance of
StationDatais modified by additional metadata and flags for the new variable. See also_compute_wdep_from_concprcp_helper().- Parameters:
StationData – data object containing concprcp and precip data
- Returns:
array with wet deposition values
- Return type:
- pyaerocom.aux_var_helpers.compute_wetoxs_from_concprcpoxsc(data)[source]
Compute wdep from conc in precip and precip data
Note
In addition to the returned numpy array, the input instance of
StationDatais modified by additional metadata and flags for the new variable. See also_compute_wdep_from_concprcp_helper().- Parameters:
StationData – data object containing concprcp and precip data
- Returns:
array with wet deposition values
- Return type:
- pyaerocom.aux_var_helpers.compute_wetoxs_from_concprcpoxst(data)[source]
Compute wdep from conc in precip and precip data
Note
In addition to the returned numpy array, the input instance of
StationDatais modified by additional metadata and flags for the new variable. See also_compute_wdep_from_concprcp_helper().- Parameters:
StationData – data object containing concprcp and precip data
- Returns:
array with wet deposition values
- Return type:
- pyaerocom.aux_var_helpers.compute_wetrdn_from_concprcprdn(data)[source]
Compute wdep from conc in precip and precip data
Note
In addition to the returned numpy array, the input instance of
StationDatais modified by additional metadata and flags for the new variable. See also_compute_wdep_from_concprcp_helper().- Parameters:
StationData – data object containing concprcp and precip data
- Returns:
array with wet deposition values
- Return type:
- pyaerocom.aux_var_helpers.concx_to_vmrx(data: float | _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | bool | int | complex | str | bytes | _NestedSequence[bool | int | float | complex | str | bytes], p_pascal: float, T_kelvin: float, conc_unit: str, mmol_var: float, mmol_air: float | None = None, to_unit: str | None = None)[source]
Convert mass concentration to volume mixing ratio (vmr)
- Parameters:
data (float or ndarray) – array containing vmr values
p_pascal (float) – pressure in Pa of input data
T_kelvin (float) – temperature in K of input data
conc_unit (str) – unit of input data
mmol_var (float) – molar mass of variable represented by input data
mmol_air (float, optional) – Molar mass of air. Uses average density of dry air if None. The default is None.
to_unit (str, optional) – Unit to which output data is converted. If None, output unit is kg m-3. The default is None.
- Returns:
input data converted to volume mixing ratio
- Return type:
float or ndarray
- pyaerocom.aux_var_helpers.mmrx_to_concx(data: float | _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | bool | int | complex | str | bytes | _NestedSequence[bool | int | float | complex | str | bytes], p_pascal: float, T_kelvin: float, mmr_unit: str, to_unit: str | None = None)[source]
Convert mass mixing ratio (mmr) to mass concentration
- Parameters:
data (float or ndarray) – array containing vmr values
p_pascal (float) – pressure in Pa of input data
T_kelvin (float) – temperature in K of input data
mmr_unit (str) – unit of input data
to_unit (str, optional) – Unit to which output data is converted. If None, output unit is kg m-3. The default is None.
- Returns:
input data converted to mass concentration
- Return type:
float or ndarray
- pyaerocom.aux_var_helpers.vmrx_to_concx(data: float | _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | bool | int | complex | str | bytes | _NestedSequence[bool | int | float | complex | str | bytes], p_pascal: float, T_kelvin: float, vmr_unit: str, mmol_var: float, mmol_air: float | None = None, to_unit: str | None = None)[source]
Convert volume mixing ratio (vmr) to mass concentration
- Parameters:
data (float or ndarray) – array containing vmr values
p_pascal (float) – pressure in Pa of input data
T_kelvin (float) – temperature in K of input data
vmr_unit (str) – unit of input data
mmol_var (float) – molar mass of variable represented by input data
mmol_air (float, optional) – Molar mass of air. Uses average density of dry air if None. The default is None.
to_unit (str, optional) – Unit to which output data is converted. If None, output unit is kg m-3. The default is None.
- Returns:
input data converted to mass concentration
- Return type:
float or ndarray
Variable categorisations
Variable categorisation groups
These are needed in some cases to infer, e.g. units associated with variable
names. Used in pyaerocom.variable.Variable to identify certain groups.
Note
The below definitions are far from complete
- pyaerocom.var_groups.dep_add_vars = []
additional deposition rate variables (that do not start with wet* or dry*)
- pyaerocom.var_groups.drydep_startswith = 'dry'
start string of dry deposition variables
- pyaerocom.var_groups.emi_add_vars = []
additional emission rate variables (that do not start with emi*)
- pyaerocom.var_groups.emi_startswith = 'emi'
start string of emission variables
- pyaerocom.var_groups.totdep_startswith = 'dep'
start string of total deposition variables
- pyaerocom.var_groups.wetdep_startswith = 'wet'
start string of wet deposition variables
Regions and data filtering
Region class and helper functions
This module contains functionality related to regions in pyaerocom
- class pyaerocom.region.Region(region_id: str | None = None, **kwargs)[source]
Class specifying a region
- Parameters:
region_id (str) – ID of region (e.g. “EUROPE”). If the input region ID is registered as a default region in
pyaerocom.region_defs, then the default information is automatically imported on class instantiation.**kwargs – additional class attributes (see above for available default attributes). Note, any attr. values provided by kwargs are preferred over potentially defined default attrs. that are imported automatically.
- contains_coordinate(lat: float, lon: float) float[source]
Check if input lat/lon coordinate is contained in region
- class pyaerocom.region.RegionName[source]
String class for ordering of region names. Region names are sorted such that ALL_REGION_NAME always comes first, and any other regions are sorted alphabetically.
- pyaerocom.region.all()[source]
Wrapper for
get_all_default_region_ids()
- pyaerocom.region.find_closest_region_coord(lat: float, lon: float, regions: dict | None = None, *, regions_how: str) list[str][source]
Finds list of regions sorted by their center closest to input coordinate
- Parameters:
lat (float) – latitude of coordinate
lon (float) – longitude of coordinate
regions (dict, optional) – dictionary containing instances of
Regionas values, which are considered. If None, then all default regions are used.regions_how (str) – string value of either “default”, “htap”, “country”, or “none” (See EvalSetup for details)
- Returns:
sorted list of region IDs of identified regions
- Return type:
- pyaerocom.region.get_all_default_region_ids()[source]
Get list containing IDs of all default regions
- Returns:
IDs of all predefined default regions
- Return type:
- pyaerocom.region.get_all_default_regions()[source]
Get dictionary containing all default regions from region.ini file
- pyaerocom.region.get_old_aerocom_default_regions()[source]
Load dictionary with default AeroCom regions
Region definitions
Definitions of rectangular regions used in pyaerocom
NOTE: replaces former regions.ini in pyaerocom/data dir
- pyaerocom.region_defs.ALL_REGION_NAME = 'ALL'
Name of region containing absolute all valid data points (WORLD in old aerocom notation)
Region filter
- class pyaerocom.filter.Filter(name=None, region=None, altitude_filter=None, land_ocn=None, **kwargs)[source]
Class that can be used to filter gridded and ungridded data objects
Note
BETA version (currently being tested)
Can only filter spatially
Might be renamed to RegionFilter at some point in the future
- ALTITUDE_FILTERS = {'noMOUNTAINS': [-1000000.0, 1000.0], 'wMOUNTAINS': None}
dictionary specifying altitude filters
- LAND_OCN_FILTERS = ['LAND', 'OCN']
- NO_ALTITUDE_FILTER_NAME = 'wMOUNTAINS'
- NO_REGION_FILTER_NAME = 'ALL'
- property alt_range
Altitude range of filter
- apply(data_obj)[source]
Apply filter to data object
- Parameters:
data_obj (
UngriddedData,GriddedData) – input data object that is supposed to be filtered- Returns:
filtered data object
- Return type:
UngriddedData,GriddedData- Raises:
IOError – if input is invalid
- property land_ocn
- property lat_range
Latitude range of region
- property lon_range
Longitude range of region
- property name
Name of filter
String containing up to 3 substrings (delimited using dash -) containing: <region_id>-<altitude_filter>-<land_or_sea_only_info>
- property region
Region associated with this filter (instance of
Region)
- property region_name
Name of region
- property spl
- property valid_alt_filter_codes
Valid codes for altitude filters
- property valid_land_sea_filter_codes
Codes specifying land/sea filters
- property valid_regions
Names of valid regions (AeroCom regions and HTAP regions)
Land / Sea masks
Helper methods for access of and working with land/sea masks. pyaerocom provides automatic access to HTAP land sea masks from this URL:
https://pyaerocom.met.no/pyaerocom-suppl
Filtering by these masks is implemented in Filter and all relevant
data classes (i.e. GriddedData, UngriddedData,
ColocatedData).
- pyaerocom.helpers_landsea_masks.available_htap_masks()[source]
List of HTAP mask names
- Returns:
Returns a list of available htap region masks.
- Return type:
- pyaerocom.helpers_landsea_masks.check_all_htap_available()[source]
Check for missing HTAP masks on local computer and download
- pyaerocom.helpers_landsea_masks.download_htap_masks(regions_to_download=None)[source]
Download HTAP mask
URL: https://pyaerocom.met.no/pyaerocom-suppl.
- Parameters:
regions_to_download (list) – List containing the regions to download.
- Returns:
List of file paths that point to the mask files that were successfully downloaded
- Return type:
- Raises:
ValueError – if one of the input regions does not exist
DataRetrievalError – if download fails for one of the input regions
- pyaerocom.helpers_landsea_masks.get_htap_mask_files(*region_ids)[source]
Get file paths to input HTAP regions
- Parameters:
*region_ids – ID’s of regions for which mask files are supposed to be retrieved
- Returns:
list of file paths for each input region
- Return type:
- Raises:
FileNotFoundError – if default local directory for storage of HTAP masks does not exist
NameError – if multiple mask files are found for the same region
- pyaerocom.helpers_landsea_masks.get_lat_lon_range_mask_region(mask, latdim_name=None, londim_name=None)[source]
Get outer lat/lon rectangle of a binary mask
- Parameters:
- Returns:
dictionary containing lat and lon ranges of the mask.
- Return type:
- pyaerocom.helpers_landsea_masks.get_mask_value(lat, lon, mask)[source]
Get value of mask at input lat / lon position
- Parameters:
lat (float) – latitude
lon (float) – longitude
mask (xarray.DataArray) – data array
- Returns:
nearest neighbour mask value to input lat lon
- Return type:
- pyaerocom.helpers_landsea_masks.load_region_mask_iris(*regions)[source]
Loads regional mask to iris.
- Parameters:
region_id (str) – Chosen region.
- Returns:
cube representing merged mask from input regions
- Return type:
iris.cube.Cube
Time and frequencies
Handling of time frequencies
Temporal resampling
Module containing time resampling functionality
- class pyaerocom.time_resampler.TimeResampler(input_data=None)[source]
Object that can be use to resample timeseries data
It supports hierarchical resampling of
xarray.DataArrayobjects andpandas.Seriesobjects.Hierarchical means, that resampling constraints can be applied for each level, that is, if hourly data is to be resampled to monthly, it may be specified to first required minimum number of hours per day, and minimum days per month, to create the output data.
- AGGRS_UNIT_PRESERVE = ('mean', 'median', 'std', 'max', 'min')
- DEFAULT_HOW = 'mean'
- property fun
Resampling method (depends on input data type)
- property input_data
Input data object that is to be resampled
- property last_units_preserved
Boolean indicating if last resampling operation preserves units
- resample(to_ts_type, input_data=None, from_ts_type=None, how=None, min_num_obs=None, **kwargs)[source]
Resample input data
- Parameters:
input_data (pandas.Series or xarray.DataArray) – data to be resampled
from_ts_type (str or TsType, optional) – current temporal resolution of data
how (str) – string specifying how the data is to be aggregated, default is mean
min_num_obs (dict or int, optional) –
integer or nested dictionary specifying minimum number of observations required to resample from higher to lower frequency. For instance, if input_data is hourly and to_ts_type is monthly, you may specify something like:
min_num_obs = {'monthly' : {'daily' : 7}, 'daily' : {'hourly' : 6}}
to require at least 6 hours per day and 7 days per month.
**kwargs – additional input arguments passed to resampling method
- Returns:
resampled data object
- Return type:
Global constants
Vertical coordinate support
Note
BETA: most functionality of this module is currently not implemented in any of the pyaerocom standard API.
Methods to convert different standards of vertical coordinates
For details see here:
http://cfconventions.org/Data/cf-conventions/cf-conventions-1.0/build/apd.html
Note
UNDER DEVELOPMENT -> NOT READY YET
- class pyaerocom.vert_coords.AltitudeAccess(gridded_data)[source]
- ADD_FILE_OPT = {'pres': ['temp']}
- ADD_FILE_REQ = {'deltaz3d': ['ps']}
Additional variables that are required to compute altitude levels
- ADD_FILE_VARS = ['z', 'z3d', 'pres', 'deltaz3d']
Additional variable names (in AEROCOM convention) that are used to search for additional files that can be used to access or compute the altitude levels at each grid point
- property coord_list
List of AeroCom coordinate names for altitude access
- property reader
Instance of
ReadGridded
- search_aux_coords(coord_list) bool[source]
Search and assign coordinates provided by input list
All coordinates that are found are assigned to this object and can be accessed via
self[coord_name].- Parameters:
coord_list (list) – list containing AeroCom coordinate names
- Returns:
True if all coordinates can be accessed, else False
- Return type:
- Raises:
CoordinateNameError – if one of the input coordinate names is not supported by pyaerocom. See coords.ini file of pyaerocom for available coordinates.
- class pyaerocom.vert_coords.VerticalCoordinate(name=None)[source]
- CONVERSION_METHODS = {'ahspc': <function atmosphere_hybrid_sigma_pressure_coordinate_to_pressure>, 'asc': <function atmosphere_sigma_coordinate_to_pressure>}
- CONVERSION_REQUIRES = {'ahspc': ['a', 'b', 'ps', 'p0'], 'asc': ['sigma', 'ps', 'ptop'], 'gph': []}
- FUNS_YIELD = {'ahspc': 'air_pressure', 'asc': 'air_pressure', 'gph': 'altitude'}
- NAMES_NOT_SUPPORTED = ['model_level_number']
- NAMES_SUPPORTED = {'air_pressure': 'pres', 'altitude': 'z', 'atmosphere_hybrid_sigma_pressure_coordinate': 'ahspc', 'atmosphere_sigma_coordinate': 'asc', 'geopotential_height': 'gph'}
- REGISTERED = ['altitude', 'air_pressure', 'geopotential_height', 'atmosphere_sigma_coordinate', 'atmosphere_hybrid_sigma_pressure_coordinate', 'model_level_number']
registered names
- STANDARD_NAMES = {'ahspc': 'atmosphere_hybrid_sigma_pressure_coordinate', 'asc': 'atmosphere_sigma_coordinate', 'gph': 'geopotential_height', 'pres': 'air_pressure', 'z': 'altitude'}
- calc_pressure(lev: ndarray, **kwargs) ndarray[source]
Compute pressure levels for input vertical coordinate
- Parameters:
vals (ndarray) – level values that are supposed to be converted into pressure
**kwargs – additional keyword args required for computation of pressure levels (cf.
CONVERSION_METHODSand corresponding inputs for method available)
- Returns:
pressure levels in Pa
- Return type:
ndarray
- property fun
Function used to convert levels into pressure
- pyaerocom.vert_coords.atmosphere_hybrid_sigma_pressure_coordinate_to_pressure(a: ndarray, b: ndarray, ps: float, p0: float | None = None) ndarray[source]
Convert atmosphere_hybrid_sigma_pressure_coordinate to pressure in Pa
Formula:
Either
\[p(k) = a(k) \cdot p_0 + b(k) \cdot p_{surface}\]or
\[p(k) = ap(k) + b(k) \cdot p_{surface}\]- Parameters:
a (ndarray) – sigma level values (a(k) in formula 1, and ap(k) in formula 2)
b (ndarray) – dimensionless fraction per level (must be same length as a)
ps (float) – surface pressure
p0 – reference pressure (only relevant for alternative formula 1)
- Returns:
computed pressure levels in Pa (standard_name=air_pressure)
- Return type:
ndarray
- pyaerocom.vert_coords.atmosphere_sigma_coordinate_to_pressure(sigma: ndarray | float, ps: float, ptop: float) ndarray | float[source]
Convert atmosphere sigma coordinate to pressure in Pa
Note
This formula only works at one lon lat coordinate and at one instant in time.
Formula:
\[p(k) = p_{top} + \sigma(k) \cdot (p_{surface} - p_{top})\]
Trends computation
Trends engine
- class pyaerocom.trends_engine.TrendsEngine[source]
Trend computation engine (does not need to be instantiated)
- static compute_trend(data, ts_type, start_year, stop_year, min_num_yrs, season=None, slope_confidence=None)[source]
Compute trend
- Parameters:
data (pd.Series) – input timeseries data
ts_type (str) – frequency of input data (must be monthly or yearly)
min_num_yrs (int) – minimum number of years for trend computation
season (str, optional) – which season to use, defaults to whole year (no season)
slope_confidence (float, optional) – confidence of slope, between 0 and 1, defaults to 0.68.
- Returns:
trends results for input data
- Return type:
Helper methods
Helper methods for computation of trends
Note
Most methods here are private and not to be used directly. Please use
TrendsEngine instead.
- pyaerocom.trends_helpers._compute_trend_error(m, m_err, v0, v0_err)[source]
Computes error of trend estimate using gaussian error propagation
The (normalised) trend is computed as T = m / v0
where m denotes the slope of a regression line and v0 denotes the normalistation value. This method computes the uncertainty of T (delta_T) using gaussian error propagation of uncertainties accompanying m and v0.
- Parameters:
- Returns:
error of T in computed using gaussian error propagation of trend formula in units of %/yr
- Return type:
- pyaerocom.trends_helpers._find_area(lat, lon, regions_dict=None)[source]
Find area corresponding to input lat/lon coordinate
Utility functions
- pyaerocom.utils.create_varinfo_table(model_ids, vars_or_var_patterns, read_data=False, sort_by_cols=['Var', 'Model'])[source]
Create an info table for model list based on variables
The method iterates over all models in
model_listand creates an instance ofReadGridded. Variable matches are searched based on input listvars_or_var_patterns(you may also use wildcards to specify a family of variables) and for each match the information below is collected. The search also includes variables that are not directly available in the model data but can be computed from other available variables. That is, all variables that are defined inReadGridded.AUX_REQUIRES.The output table (DataFrame) then consists of the following columns:
Var: variable name
Model: model name
Years: available years
Freq: frequency
Vertical: information about vertical dimension (inferred from Aerocom file name)
At stations: data is at stations (inferred from filename)
AUX vars: Auxiliary variable required to compute Var (col 1). Only relevant for variables that are computed by the interface
Dim: number of dimensions (only retrieved if read_data is True)
Dim names: names of dimension coordinates (only retrieved if read_data is True)
Shape: Shape of data (only retrieved if read_data is True)
Read ok: reading was successful (only retrieved if read_data is True)
- Parameters:
model_ids (list) – list of model ids to be analysed (can also be string -> single model)
vars_or_var_patterns (list) – list of variables or variable patterns to be analysed (can also be string -> single variable or variable family)
read_data (bool) – if True, more information about the imported data will be available in the table (e.g. no. of dimensions, names of dimension coords) but the routine will run longer since the data is imported
sort_by_cols (list) – column sort order (use header names in listing above). Defaults to [‘Var’, ‘Model’]
- Returns:
dataframe including result table (ready to be saved as csv or other tabular format or to be displayed in a jupyter notebook)
- Return type:
Example
>>> from pyaerocom import create_varinfo_table >>> models = ['INCA-BCext_CTRL2016-PD', ... 'GEOS5-freegcm_CTRL2016-PD'] >>> vars = ['ang4487aer', 'od550aer', 'ec*'] >>> create_varinfo_table(models, vars) At model: INCA-BCext_CTRL2016-PD (0 of 2) At model: GEOS5-freegcm_CTRL2016-PD (1 of 2) ...
- pyaerocom.utils.dicts_equal(d1: dict, d2: dict) bool[source]
Recursively checks equality of dicts ensuring that ndarrays are compared item-wise.
- Parameters:
d1 – First dict.
d2 – Second Dict.
- Returns:
boolean indicating equality.
- pyaerocom.utils.recursive_defaultdict(d: Mapping | None = None)[source]
Creates a recursive default dict which creates empty subdicts automatically on access. Useful to avoid lots of boiler plate code for creating empty subdicts.
Example:
` dd = recursive_defaultdict() dd["A"]["B"]["C"]["D"]["E"] = "Hello world" `Optionally takes a parameter d (eg. dictionary) to initialize the defaultdict. Every existing subdictionary will recursively be turned into a recursive_defaultdict.
See also: https://docs.python.org/3/library/collections.html#collections.defaultdict
Helpers
General helper methods for the pyaerocom library.
- pyaerocom.helpers.calc_climatology(s, start, stop, min_count=None, set_year=None, resample_how='mean')[source]
Compute climatological timeseries from pandas.Series
- Parameters:
s (pandas.Series) – time series data
start (numpy.datetime64 or similar) – start time of data used to compute climatology
stop (numpy.datetime64 or similar) – start time of data used to compute climatology
mincount_month (int, optional) – minimum number of observations required per aggregated month in climatological interval. Months not meeting this requirement will be set to NaN.
set_year (int, optional) – if specified, the output data will be assigned the input year. Else the middle year of the climatological interval is used.
resample_how (str) – string specifying how the climatological timeseries is to be aggregated
- Returns:
dataframe containing climatological timeseries as well as columns std and count
- Return type:
DataFrame
- pyaerocom.helpers.check_coord_circular(coord_vals, modulus, rtol=1e-05)[source]
Check circularity of coordinate
- Parameters:
- Returns:
True if circularity is given, else False
- Return type:
- Raises:
ValueError – if circularity is given and results in overlap (right end of input array is mapped to a value larger than the first one at the left end of the array)
- pyaerocom.helpers.copy_coords_cube(to_cube, from_cube, inplace=True)[source]
Copy all coordinates from one cube to another
Requires the underlying data to be the same shape.
Warning
This operation will delete all existing coordinates and auxiliary coordinates and will then copy the ones from the input data object. No checks of any kind will be performed
- Parameters:
to_cube
other (GriddedData or Cube) – other data object (needs to be same shape as this object)
- Returns:
data object containing coordinates from other object
- Return type:
- pyaerocom.helpers.delete_all_coords_cube(cube, inplace=True)[source]
Delete all coordinates of an iris cube
- Parameters:
cube (iris.cube.Cube) – input cube that is supposed to be cleared of coordinates
inplace (bool) – if True, then the coordinates are deleted in the input object, else in a copy of it
- Returns:
input cube without coordinates
- Return type:
iris.cube.Cube
- pyaerocom.helpers.extract_latlon_dataarray(arr, lat, lon, lat_dimname=None, lon_dimname=None, method='nearest', new_index_name=None, check_domain=True)[source]
Extract individual lat / lon coordinates from DataArray lon/lat can also be x/y coordinates if the DataArray has only projected axes.
- Parameters:
arr (DataArray) – data (must contain lat and lon dimensions)
lat (array or similar) – 1D array containing latitude coordinates
lon (array or similar) – 1D array containing longitude coordinates
lat_dimname (str, optional) – name of latitude dimension in input data (if None, it assumes standard name)
lon_dimname (str, optional) – name of longitude dimension in input data (if None, it assumes standard name)
method (str) – how to interpolate to input coordinates (defaults to nearest neighbour)
new_index_name (str, optional) – name of flattend latlon dimension (defaults to latlon)
check_domain (bool) – if True, lat/lon domain of datarray is checked and all input coordinates that are outside of the domain are ignored.
- Returns:
data at input coordinates
- Return type:
DataArray
- pyaerocom.helpers.get_constraint(lon_range=None, lat_range=None, time_range=None, meridian_centre=True)[source]
Function that creates an
iris.Constraintbased on inputNote
Please be aware of the definition of the longitudes in your data when cropping within the longitude dimension. The longitudes in your data may be defined either from -180 <= lon <= 180 (pyaerocom standard) or from 0 <= lon <= 360. In the former case (-180 -> 180) you can leave the additional input parameter
meridian_centre=True(default).- Parameters:
lon_range (
tuple, optional) – 2-element tuple containing longitude range for cropping Example input to crop around meridian: lon_range=(-30, 30)lat_range (
tuple, optional) – 2-element tuple containing latitude range for cropping.time_range (
tuple, optional) –2-element tuple containing time range for cropping. Allowed data types for specifying the times are
a combination of 2
pandas.Timestampinstances ora combination of two strings that can be directly converted into
pandas.Timestampinstances (e.g. time_range=(“2010-1-1”, “2012-1-1”)) ordirectly a combination of indices (
int).
meridian_centre (bool) – specifies the coordinate definition range of longitude array. If True, then -180 -> 180 is assumed, else 0 -> 360
- Returns:
the combined constraint from all valid input parameters
- Return type:
iris.Constraint
- pyaerocom.helpers.get_lat_rng_constraint(low, high)[source]
Create latitude constraint based on input range
- pyaerocom.helpers.get_lon_rng_constraint(low, high, meridian_centre=True)[source]
Create longitude constraint based on input range
- Parameters:
- Returns:
the corresponding iris.Constraint instance
- Return type:
iris.Constraint
- Raises:
ValueError – if first coordinate in lon_range equals or exceeds second
LongitudeConstraintError – if the input implies cropping over border of longitude array (e.g. 160 -> - 160 if -180 <= lon <= 180).
- pyaerocom.helpers.get_standard_name(var_name)[source]
Converts AeroCom variable name to CF standard name
Also handles alias names for variables, etc. or strings corresponding to older conventions (e.g. names containing 3D).
- pyaerocom.helpers.get_time_rng_constraint(start, stop)[source]
Create iris.Constraint for data extraction along time axis
- Parameters:
start (
Timestampor :obj:` str`) – start time of desired subset. If string, it must be convertible intopandas.Timestamp(e.g. “2012-1-1”)stop (
Timestampor :obj:` str`) – start time of desired subset. If string, it must be convertible intopandas.Timestamp(e.g. “2012-1-1”)
- Returns:
iris Constraint instance that can, e.g., be used as input for
pyaerocom.griddeddata.GriddedData.extract()- Return type:
iris.Constraint
- pyaerocom.helpers.isnumeric(val)[source]
Check if input value is numeric
- Parameters:
val – input value to be checked
- Returns:
True, if input value corresponds to a range, else False.
- Return type:
- pyaerocom.helpers.isrange(val)[source]
Check if input value corresponds to a range
Checks if input is list, or array or tuple with 2 entries, or alternatively a slice that has defined start and stop and has set step to None.
Note
No check is performed, whether first entry is smaller than second entry if all requirements for a range are fulfilled.
- Parameters:
val – input value to be checked
- Returns:
True, if input value corresponds to a range, else False.
- Return type:
- pyaerocom.helpers.lists_to_tuple_list(*lists)[source]
Convert input lists (of same length) into list of tuples
e.g. input 2 lists of latitude and longitude coords, output one list with tuple coordinates at each index
- pyaerocom.helpers.make_datetime_index(start, stop, freq)[source]
Make pandas.DatetimeIndex for input specs
Note
If input frequency is specified in PANDAS_RESAMPLE_OFFSETS, an offset will be added (e.g. 15 days for monthly data).
- Parameters:
start – start time. Preferably as
pandas.Timestamp, else it will be attempted to be converted.stop – stop time. Preferably as
pandas.Timestamp, else it will be attempted to be converted.freq – frequency of datetime index.
- Return type:
DatetimeIndex
- pyaerocom.helpers.make_datetimeindex_from_year(freq, year)[source]
Create pandas datetime index
- Parameters:
- Returns:
index object
- Return type:
- pyaerocom.helpers.make_dummy_cube(var_name: str, start_yr: int = 2000, stop_yr: int = 2020, freq: str = 'daily', dtype=<class 'float'>) Cube[source]
- pyaerocom.helpers.make_dummy_cube_latlon(lat_res_deg: float = 2, lon_res_deg: float = 3, lat_range: list[float] | tuple[float, float] = (-90, 90), lon_range: list[float] | tuple[float, float] = (-180, 180))[source]
Make an empty Cube with given latitude and longitude resolution
Dimensions will be lat, lon
- pyaerocom.helpers.merge_station_data(stats, var_name, pref_attr=None, sort_by_largest=True, fill_missing_nan=True, add_meta_keys=None, resample_how=None, min_num_obs=None)[source]
Merge multiple StationData objects (from one station) into one instance
Note
all input
StationDataobjects need to have same attributesstation_name,latitude,longitudeandaltitude- Parameters:
stats (list) – list containing
StationDataobjects (note: all of these objects must contain variable data for the specified input variable)var_name (str) – data variable name that is to be merged
pref_attr – optional argument that may be used to specify a metadata attribute that is available in all input
StationDataobjects and that is used to order the input stations by relevance. The associated values of this attribute need to be sortable (e.g. revision_date). This is only relevant in case overlaps occur. If unspecified the relevance of the stations is sorted based on the length of the associated data arrays.sort_by_largest (bool) – if True, the result from the sorting is inverted. E.g. if
pref_attris unspecified, then the stations will be sorted based on the length of the data vectors, starting with the shortest, ending with the longest. This sorting result will then be inverted, ifsort_by_largest=True, so that the longest time series get’s highest importance. If, e.g.pref_attr='revision_date', then the stations are sorted by the associated revision date value, starting with the earliest, ending with the latest (which will also be inverted if this argument is set to True)fill_missing_nan (bool) – if True, the resulting time series is filled with NaNs. NOTE: this requires that information about the temporal resolution (ts_type) of the data is available in each of the StationData objects.
add_meta_keys (str or list, optional) – additional non-standard metadata keys that are supposed to be considered for merging.
resample_how (str or dict, optional) – in case input stations come in different frequencies they are merged to the lowest common freq. This parameter can be used to control, which aggregator(s) are to be used (e.g. mean, median).
min_num_obs (str or dict, optional) – in case input stations come in different frequencies they are merged to the lowest common freq. This parameter can be used to control minimum number of observation constraints for the downsampling.
- Returns:
merged data
- Return type:
- pyaerocom.helpers.numpy_to_cube(data, dims=None, var_name=None, units=None, **attrs)[source]
Make a cube from a numpy array
- Parameters:
data (ndarray) – input data
dims (list, optional) – list of
iris.coord.DimCoordinstances in order of dimensions of input data array (length of list and shapes of each of the coordinates must match dimensions of input data)var_name (str, optional) – name of variable
units (str) – unit of variable
**attrs – additional attributes to be added to metadata
- Return type:
iris.cube.Cube
- Raises:
DataDimensionError – if input dims is specified and results in conflict
- pyaerocom.helpers.resample_time_dataarray(arr, freq, how=None, min_num_obs=None)[source]
Resample the time dimension of a
xarray.DataArrayNote
The dataarray must have a dimension coordinate named “time”
- Parameters:
arr (DataArray) – data array to be resampled
freq (str) – new temporal resolution (can be pandas freq. string, or pyaerocom ts_type)
how (str) – how to aggregate (e.g. mean, median)
min_num_obs (int, optional) – minimum number of observations required per period (when downsampling). E.g. if input is in daily resolution and freq is monthly and min_num_obs is 10, then all months that have less than 10 days of data are set to nan.
- Returns:
resampled data array object
- Return type:
DataArray
- Raises:
IOError – if data input arr is not an instance of
DataArrayDataDimensionError – if time dimension is not available in dataset
- pyaerocom.helpers.resample_timeseries(ts, freq, how=None, min_num_obs=None)[source]
Resample a timeseries (pandas.Series)
- Parameters:
ts (Series) – time series instance
freq (str) – new temporal resolution (can be pandas freq. string, or pyaerocom ts_type)
how – aggregator to be used, accepts everything that is accepted by
pandas.core.resample.Resampler.agg()and in addition, percentiles may be provided as str using e.g. 75percentile as input for the 75% percentile.min_num_obs (int, optional) – minimum number of observations required per period (when downsampling). E.g. if input is in daily resolution and freq is monthly and min_num_obs is 10, then all months that have less than 10 days of data are set to nan.
- Returns:
resampled time series object
- Return type:
Series
- pyaerocom.helpers.same_meta_dict(meta1, meta2, ignore_keys=['PI'], num_keys=['longitude', 'latitude', 'altitude'], num_rtol=0.01)[source]
Compare meta dictionaries
- Parameters:
meta1 (dict) – meta dictionary that is to be compared with
meta2meta2 (dict) – meta dictionary that is to be compared with
meta1ignore_keys (list) – list containing meta keys that are supposed to be ignored
num_keys (keys that contain numerical values)
num_rtol (float) – relative tolerance level for comparison of numerical values
- Returns:
True, if dictionaries are the same, else False
- Return type:
- pyaerocom.helpers.start_stop(start, stop=None, stop_sub_sec=True)[source]
Create pandas timestamps from input start / stop values
Note
If input suggests climatological data in AeroCom format (i.e. year=9999) then the year is converted to 2222 instead since pandas cannot handle year 9999.
- Parameters:
start – start time (any format that can be converted to pandas.Timestamp)
stop – stop time (any format that can be converted to pandas.Timestamp)
stop_sub_sec (bool) – if True and if input for stop is a year (e.g. 2015) then one second is subtracted from stop timestamp (e.g. if input stop is 2015 and denotes “until 2015”, then for the returned stop timestamp one second will be subtracted, so it would be 31.12.2014 23:59:59).
- Returns:
pandas.Timestamp – start timestamp
pandas.Timestamp – stop timestamp
- Raises:
ValueError – if input cannot be converted to pandas timestamps
- pyaerocom.helpers.start_stop_from_year(year)[source]
Create start / stop timestamp from year
- Parameters:
year (int) – the year for which start / stop is to be instantiated
- Returns:
numpy.datetime64 – start datetime
numpy.datetime64 – stop datetime
- pyaerocom.helpers.str_to_iris(key, **kwargs)[source]
Mapping function that converts strings into iris analysis objects
Please see dictionary
STR_TO_IRISin this module for valid definitions- Parameters:
key (str) – key of
STR_TO_IRISdictionary- Returns:
corresponding iris analysis object (e.g. Aggregator, method)
- Return type:
obj
- pyaerocom.helpers.to_datestring_YYYYMMDD(value)[source]
Convert input time to string with format YYYYMMDD
- Parameters:
value – input time, may be string, datetime, numpy.datetime64 or pandas.Timestamp
- Returns:
input formatted to string YYYYMMDD
- Return type:
- Raises:
ValueError – if input is not supported
Mathematical helpers
Mathematical low level utility methods of pyaerocom
- pyaerocom.mathutils.closest_index(num_array, value)[source]
Returns index in number array that is closest to input value
- pyaerocom.mathutils.corr(ref_data, data, weights=None)[source]
Compute correlation coefficient
- Parameters:
data_ref (ndarray) – x data
data (ndarray) – y data
weights (ndarray, optional) – array containing weights for each point in data
- Returns:
correlation coefficient
- Return type:
- pyaerocom.mathutils.estimate_value_range(vmin, vmax, extend_percent=0)[source]
Round and extend input range to estimate lower and upper bounds of range
- pyaerocom.mathutils.exponent(num)[source]
Get exponent of input number
- Parameters:
num (
floator iterable) – input number- Returns:
exponent of input number(s)
- Return type:
intorndarraycontaining ints
Example
>>> from pyaerocom.mathutils import exponent >>> exponent(2340) np.int64(3)
- pyaerocom.mathutils.is_strictly_monotonic(iter1d) bool[source]
Check if 1D iterable is strictly monotonic
- Parameters:
iter1d – 1D iterable object to be tested
- Return type:
- pyaerocom.mathutils.numbers_in_str(input_string)[source]
This method finds all numbers in a string
Note
Beta version, please use with care
Detects only integer numbers, dots are ignored
- Parameters:
input_string (str) – string containing numbers
- Returns:
list of strings specifying all numbers detected in string
- Return type:
Example
>>> numbers_in_str('Bla42Blub100') ['42', '100']
- pyaerocom.mathutils.range_magnitude(low, high)[source]
Returns magnitude of value range
- Parameters:
- Returns:
magnitudes spanned by input numbers
- Return type:
Example
>>> range_magnitude(0.1, 100) np.int64(3) >>> range_magnitude(100, 0.1) np.int64(-3) >>> range_magnitude(1e-3, 1e6) np.int64(9)
- pyaerocom.mathutils.sum(data, weights=None)[source]
Summing operation with option to perform weighted sum
- pyaerocom.mathutils.weighted_corr(ref_data, data, weights)[source]
Compute weighted correlation
- Parameters:
data_ref (ndarray) – x data
data (ndarray) – y data
weights (ndarray) – array containing weights for each point in data
- Returns:
weighted correlation coefficient
- Return type:
- pyaerocom.mathutils.weighted_cov(ref_data, data, weights)[source]
Compute weighted covariance
- Parameters:
data_ref (ndarray) – x data
data (ndarray) – y data
weights (ndarray) – array containing weights for each point in data
- Returns:
covariance
- Return type:
- pyaerocom.mathutils.weighted_sum(data, weights)[source]
Compute weighted sum using numpy dot product
- Parameters:
data (ndarray) – data array that is supposed to be summed up
weights (ndarray) – array containing weights for each point in data
- Returns:
weighted sum of values in input array
- Return type:
Geodesic calculations and topography
Module for geographical calculations
This module contains low-level methods to perform geographical calculations, (e.g. distance between two coordinates)
- pyaerocom.geodesy.calc_distance(lat0, lon0, lat1, lon1, alt0=None, alt1=None, auto_altitude_srtm=False)[source]
Calculate distance between two coordinates
- Parameters:
lat0 (float) – latitude of first point in decimal degrees
lon0 (float) – longitude of first point in decimal degrees
lat1 (float) – latitude of secondpoint in decimal degrees
lon1 (float) – longitude of second point in decimal degrees
alt0 (
float, optional) – altitude of first point in malt1 (
float, optional) – altitude of second point in mauto_altitude_srtm (bool) – if True, then all altitudes that are unspecified are set to the corresponding topographic altitude of that coordinate, using SRTM (only works for coordinates where SRTM topographic data is accessible).
- Returns:
distance between points in km
- Return type:
- pyaerocom.geodesy.calc_latlon_dists(latref, lonref, latlons)[source]
Calculate distances of (lat, lon) coords to input lat, lon coordinate
- Parameters:
- Returns:
list of computed geographic distances to input reference coordinate for all (lat, lon) coords in latlons
- Return type:
- pyaerocom.geodesy.find_coord_indices_within_distance(latref, lonref, latlons, radius=1)[source]
Find indices of coordinates that match input coordinate
- Parameters:
- Returns:
Indices of latlon coordinates in :param:`latlons` that are within the specified radius around (latref, lonref). The indices are sorted by distance to the input coordinate, starting with the closest
- Return type:
ndarray
- pyaerocom.geodesy.get_country_info_coords(coords)[source]
Get country information for input lat/lon coordinates
- Parameters:
coords (list or tuple) – list of coord tuples (lat, lon) or single coord tuple
- Raises:
ValueError – if input format is incorrect
- Returns:
list of dictionaries containing country information for each input coordinate
- Return type:
- pyaerocom.geodesy.get_topo_altitude(lat, lon, topo_dataset='srtm', topodata_loc=None, try_etopo1=True)[source]
Retrieve topographic altitude for a certain location
Supports topography datasets supported by geonum. These are currently (20 Feb. 19) srtm (SRTM dataset, default, automatic access if online) and etopo1 (ETOPO1 dataset, lower resolution, must be available on local machine or server).
- Parameters:
lat (float) – latitude of coordinate
lon (float) – longitude of coordinate
topo_dataset (str) – name of topography dataset
topodata_loc (str) – filepath or directory containing supported topographic datasets
try_etopo1 (bool) – if True and if access fails via input arg topo_dataset, then try to access altitude using ETOPO1 dataset.
- Returns:
dictionary containing input latitude, longitude, altitude and topographic dataset name used to retrieve the altitude.
- Return type:
- Raises:
ValueError – if altitude data cannot be accessed
- pyaerocom.geodesy.get_topo_data(lat0, lon0, lat1=None, lon1=None, topo_dataset='srtm', topodata_loc=None, try_etopo1=False)[source]
Retrieve topographic altitude for a certain location
Supports topography datasets supported by geonum. These are currently (20 Feb. 19) srtm (SRTM dataset, default, automatic access if online) and etopo1 (ETOPO1 dataset, lower resolution, must be available on local machine or server).
- Parameters:
lat0 (float) – start longitude for data extraction
lon0 (float) – start latitude for data extraction
lat1 (float) – stop longitude for data extraction (default: None). If None only data around lon0, lat0 will be extracted.
lon1 (float) – stop latitude for data extraction (default: None). If None only data around lon0, lat0 will be extracted
topo_dataset (str) – name of topography dataset
topodata_loc (str) – filepath or directory containing supported topographic datasets
try_etopo1 (bool) – if True and if access fails via input arg topo_dataset, then try to access altitude using ETOPO1 dataset.
- Returns:
data object containing topography data in specified range
- Return type:
geonum.TopoData
- Raises:
ValueError – if altitude data cannot be accessed
- pyaerocom.geodesy.haversine(lat0, lon0, lat1, lon1, earth_radius=6371.0)[source]
Haversine formula
Approximate horizontal distance between 2 points assuming a spherical earth using haversine formula.
Note
This code was copied from geonum library (date 12/11/2018, J. Gliss)
- Parameters:
lat0 (float) – latitude of first point in decimal degrees
lon0 (float) – longitude of first point in decimal degrees
lat1 (float) – latitude of second point in decimal degrees
lon1 (float) – longitude of second point in decimal degrees
earth_radius (float) – average earth radius in km, defaults to 6371.0
- Returns:
horizontal distance between input coordinates in km
- Return type:
- pyaerocom.geodesy.is_within_radius_km(lat0, lon0, lat1, lon1, maxdist_km, alt0=0, alt1=0, **kwargs)[source]
Checks if two lon/lat coordinates are within a certain distance to each other
- Parameters:
lat0 (float) – latitude of first point in decimal degrees
lon0 (float) – longitude of first point in decimal degrees
lat1 (float) – latitude of second point in decimal degrees
lon1 (float) – longitude of second point in decimal degrees
maxdist_km (float) – maximum distance between two points in km
alt0 (float) – altitude of first point in m
alt1 (float) – altitude of second point in m
- Returns:
True, if coordinates are within specified distance to each other, else False
- Return type:
Units and unit conversion
Units helpers in base package
- pyaerocom.units.units_helpers.convert_unit(data: T, /, from_unit: str, to_unit: str, var_name: str | None = None, ts_type: str | None = None, *, inplace: bool = False, callback: Callable[[UnitConversionCallbackInfo], None] | None = None) T[source]
Convert unit of data
- Parameters:
data (np.ndarray or similar) – input data
from_unit (cf_units.Unit or str) – current unit of input data
to_unit (cf_units.Unit or str) – new unit of input data
var_name (str, optional) – name of variable. If provided, and standard conversion with
cf_unitsfails, then custom unit conversion is attempted.ts_type (str, optional) – frequency of data. May be needed for conversion of rate variables such as precip, deposition, etc, that may be defined implicitly without proper frequency specification in the unit string.
- Returns:
data in new unit
- Return type:
data
- pyaerocom.units.units_helpers.get_unit_conversion_fac(from_unit: str, to_unit: str, var_name: str | None = None, ts_type: str | None = None) float[source]
Gets a unit conversion factor for converting from one unit to another.
- Parameters:
from_unit – From unit.
to_unit – To unit.
var_name – aerocom var name, defaults to None
ts_type – ts_type, defaults to None
- Returns:
Conversion factor.
- Raises:
UnitConversionError if unable to convert between units.
Units helpers in io sub-package
Configuration and global constants
Basic configuration class
Will be initiated on input and is accessible via pyaerocom.const.
Class containing relevant paths for read and write routines
A loaded instance of this class is created on import of pyaerocom and can be accessed via pyaerocom.const.
TODO: provide more information
Config defaults related to gridded data
- class pyaerocom.grid_io.GridIO(**kwargs)[source]
Global I/O settings for gridded data
This class includes options related to the import of gridded data. This includes both options related to file search as well as preprocessing options.
- TS_TYPES
list of strings specifying temporal resolution options encrypted in file names.
- Type:
- PERFORM_FMT_CHECKS
perform formatting checks when reading netcdf data, using metadata encoded in filenames (requires that NetCDF file follows a registered naming convention)
- Type:
- DEL_TIME_BOUNDS
if True, preexisting bounds on time are deleted when grid data is loaded. Else, nothing is done. Aerocom default is True
- Type:
- SHIFT_LONS
if True, longitudes are shifted to -180 <= lon <= 180 when data is loaded (in case they are defined 0 <= lon <= 360. Aerocom default is True.
- Type:
- CHECK_TIME_FILENAME
the times stored in NetCDF files may be wrong or not stored according to the CF conventions. If True, the times are checked and if
CORRECT_TIME_FILENAME, corrected for on data import based what is encrypted in the file name. In case of Aerocom models, it is ensured that the filename contains both the year and the temporal resolution in the filenames (for details seepyaerocom.io.FileConventionRead). Aerocom default is True- Type:
- CORRECT_TIME_FILENAME
if True and time dimension in data is found to be different from filename, it is attempted to be corrected
- Type:
- EQUALISE_METADATA
if True (and if metadata varies between different NetCDF files that are supposed to be merged in time), the metadata in all loaded objects is unified based on the metadata of the first grid (otherwise, concatenating them in time might not work using the Iris interface). This might need to be reviewed and should be used with care if specific metadata aspects of individual files need to be accessed. Aerocom default is True
- Type:
- USE_FILECONVENTION
if True, file names are strictly required to follow one of the file naming conventions that can be specified in the file file_conventions.ini. Aerocom default is True.
- Type:
- INCLUDE_SUBDIRS
if True, search for files is expanded to all subdirecories included in data directory. Aerocom default is False.
- Type:
- INFER_SURFACE_LEVEL
if True then surface level for 4D gridded data is inferred automatically when necessary (e.g. when extracting surface time series from 4D gridded data object that does not contain sufficient information about vertical dimension)
- Type:
- UNITS_ALIASES = {'/m': 'm-1'}
Config details related to observations
Settings and helper methods / classes for I/O of observation data
Note
Some settings like paths etc can be found in pyaerocom.config.py
- class pyaerocom.obs_io.AuxInfoUngridded(data_id, vars_supported, aux_requires, aux_merge_how, aux_funs=None, aux_units=None)[source]
- MAX_VARS_PER_METHOD = 2
- check_status()[source]
Check if specifications are correct and consistent
- Raises:
ValueError – If one of the class attributes is invalid
NotImplementedError – If computation method contains more than 2 variables / datasets
- pyaerocom.obs_io.OBS_ALLOW_ALT_WAVELENGTHS = True
This boolean can be used to enable / disable the former (i.e. use available wavelengths of variable in a certain range around variable wavelength).
- pyaerocom.obs_io.OBS_WAVELENGTH_TOL_NM = 10.0
Wavelength tolerance for observations if data for required wavelength is not available
Access to minimal test dataset
- pyaerocom.sample_data_access.minimal_dataset.download_minimal_dataset(file_name: str = 'testdata-minimal.tar.gz.20251014', /, extract_dir_override: str | None = None)[source]
Download test_data_file and extracts it.
- Parameters:
file_name – The file name to be downloaded.
extract_dir – An optional folder override to where to extract the file. By default files are extracted into ~/MyPyaerocom
Low-level helper classes and functions
Small helper utility functions for pyaerocom
- class pyaerocom._lowlevel_helpers.AsciiFileLoc(default=None, assert_exists=False, auto_create=False, tooltip=None)[source]
- class pyaerocom._lowlevel_helpers.BrowseDict(*args, **kwargs)[source]
Dictionary-like object with getattr and setattr options
Dictionary that supports reading and writing values with . syntax.
For example:
d = BrowseDict()
d.a = 1 d[“b”] = 2
print(d) # BrowseDict: {‘a’: 1, ‘b’: 2}
- FORBIDDEN_KEYS = []
- class pyaerocom._lowlevel_helpers.Loc(default=None, assert_exists=False, auto_create=False, tooltip=None)[source]
Abstract descriptor representing a path location
Descriptor: TODO See here: https://docs.python.org/3/howto/descriptor.html#complete-practical-example
Note
Child classes need to implement
create()value is allowed to be None in which case no checks are performed
- class pyaerocom._lowlevel_helpers.RegridResDeg[source]
Typed dict for regridding resolution degrees
- pyaerocom._lowlevel_helpers.check_dir_access(path)[source]
Uses multiprocessing approach to check if location can be accessed
- pyaerocom._lowlevel_helpers.check_write_access(path)[source]
Check if input location provides write access
- Parameters:
path (str) – directory to be tested
- pyaerocom._lowlevel_helpers.chk_make_subdir(base, name)[source]
Check if sub-directory exists in parent directory
- pyaerocom._lowlevel_helpers.dict_to_str(dictionary, indent=0, ignore_null=False)[source]
Custom function to convert dictionary into string (e.g. for print)
- pyaerocom._lowlevel_helpers.invalid_input_err_str(argname, argval, argopts)[source]
Just a small helper to format an input error string for functions
- pyaerocom._lowlevel_helpers.list_to_shortstr(lst, indent=0)[source]
Custom function to convert a list into a short string representation
- pyaerocom._lowlevel_helpers.merge_dicts(dict1, dict2, discard_failing=True)[source]
Merge two dictionaries
- Parameters:
dict1 (dict) – first dictionary
dict2 (dict) – second dictionary
discard_failing (bool) – if True, any key, value pair that cannot be merged from the 2nd into the first will be skipped, which means, the value of the output dict for that key will be the one of the first input dict. All keys that could not be merged can be accessed via key ‘merge_failed’ in output dict. If False, any Exceptions that may occur will be raised.
- Returns:
merged dictionary
- Return type:
Custom exceptions
Module containing pyaerocom custom exceptions
Units
Main API
- pyaerocom.units.units_helpers.convert_unit(data: T, /, from_unit: str, to_unit: str, var_name: str | None = None, ts_type: str | None = None, *, inplace: bool = False, callback: Callable[[UnitConversionCallbackInfo], None] | None = None) T[source]
Convert unit of data
- Parameters:
data (np.ndarray or similar) – input data
from_unit (cf_units.Unit or str) – current unit of input data
to_unit (cf_units.Unit or str) – new unit of input data
var_name (str, optional) – name of variable. If provided, and standard conversion with
cf_unitsfails, then custom unit conversion is attempted.ts_type (str, optional) – frequency of data. May be needed for conversion of rate variables such as precip, deposition, etc, that may be defined implicitly without proper frequency specification in the unit string.
- Returns:
data in new unit
- Return type:
data
- pyaerocom.units.units_helpers.get_unit_conversion_fac(from_unit: str, to_unit: str, var_name: str | None = None, ts_type: str | None = None) float[source]
Gets a unit conversion factor for converting from one unit to another.
- Parameters:
from_unit – From unit.
to_unit – To unit.
var_name – aerocom var name, defaults to None
ts_type – ts_type, defaults to None
- Returns:
Conversion factor.
- Raises:
UnitConversionError if unable to convert between units.
Unit
- class pyaerocom.units.units.Unit(unit: str, calendar: str | None = None, *, aerocom_var: str | None = None, ts_type: str | TsType | None = None, **kwargs)[source]
Pyaerocom specific encapsulation of cf_units.Unit that extends it with additional needed behaviour.
The first additional behaviour is to handle variables that measure only a portion of the real mass. Eg. if concso4 is provided as “ug S/m3”, we want the mass in terms of SO4, so the values must be scaled up by a constant factor MolecularMass(“SO4”)/MolecularMass(“S”).
The second behaviour is adding implicit frequency for rate variables and a ts_type. If tstype and aerocom_var are provided in __init__, units of the form “mg m-2” will automatically have the temporal frequency appended. For instance, assuming tstype=’daily’, it becomes “mg m-2 d-1”
Third, cf_units.Unit does not natively support conversion of eg. pd.Series. This wrapper allows conversion of any data structure that supports __mul__.
- convert(value: int, other: str | Self, inplace: bool = False, *, callback: None | Callable[[UnitConversionCallbackInfo], None] = None, **kwargs) float[source]
- convert(value: T, other: str | Self, inplace: bool = False, *, callback: None | Callable[[UnitConversionCallbackInfo], None] = None, **kwargs) T
Implements unit conversion to a different unit that should work with any data structure that supports __mul__ and / or __imul__.
- Parameters:
value – The value to be converted.
other – The unit to which to convert (will be passed to PyaerocomUnit.__init__())
callback –
Callback function for eg. logging, defaults to None The callback function will receive a NamedTuple with the following keys:
”factor” - float: The numerical conversion factor used. “from_aerocom_var” - str: The aerocom var name. “from_ts_type” - str: The ts_type of the from units. “from_cf_unit” - str: The base cf_unit converted from. “to_cf_unit” - str: The base cf_unit converted to.
kwargs – Will be passed as additional keyword args to PyaerocomUnit.__init__() for ‘other’.
- Returns:
Unit converted data.
- date2num(date: datetime | Iterable[datetime]) float | ndarray[source]
Returns the numeric time value calculated from the datetime object using the current calendar and unit time reference.
- Parameters:
date – Date to be converted.
- Returns:
See also: https://cf-units.readthedocs.io/en/latest/unit.html#cf_units.Unit.date2num
- classmethod from_cf_units(unit: Unit) Self[source]
Initialize from a cf_units.Unit instance.
- Parameters:
unit – The input unit.
- Returns:
The output unit.
- is_convertible(other: str | Unit) bool[source]
Return whether this unit is convertible to other. It handles a couple of additional cases when checking convertibility, namely:
- Units that contain elements (eg. kg N m-2) need to have compatible mass ratios:
This is assumed to be the case if element and species are the same, the aerocom
variable is the same (to account for variables that don’t have a clear mass ratio — eg. wetrdn.)
- Parameters:
other – Other Unit.
- num2date(time_value: float | ndarray, only_use_cftime_datetimes: bool = True, only_use_python_datetimes: bool = False) datetime | ndarray[source]
Returns a datetime-like object calculated from the numeric time value using the current calendar and the unit time reference.
- Parameters:
time_value – Time value(s)
only_use_cftime_datetimes – If True, will always return cftime datetime objects, regardless of calendar. If False, returns datetime.datetime instances where possible. Defaults to True.
only_use_python_datetimes – If True, will always return datetime.datetime instances where possible, and raise an exception if not. Ignored if only_use_cftime_datetimes is True. Defaults to False.
- Returns:
Datetime or ndarray of datetime.
See also: https://cf-units.readthedocs.io/en/latest/unit.html#cf_units.Unit.num2date
Datetime
- pyaerocom.units.datetime.utils.cftime_to_datetime64(times, cfunit=None, calendar=None)[source]
Convert numerical timestamps with epoch to numpy datetime64
This method was designed to enhance the performance of datetime conversions and is based on the corresponding information provided in the cftime package (see here). Particularly, this object does, what the
num2date()therein does, but faster, in case the time stamps are not defined on a non standard calendar.- Parameters:
times (
listorndarrayoriris.coords.DimCoord) – array containing numerical time stamps (relative to basedate ofcfunit). Can also be a single number.cfunit (
strorUnit, optional) – CF unit string (e.g. day since 2018-01-01 00:00:00.00000000 UTC) or unit. Required if times is not an instance ofiris.coords.DimCoordcalendar (
str, optional) – string specifying calendar (only required ifcfunitis of typestr).
- Returns:
numpy array containing timestamps as datetime64 objects
- Return type:
ndarray
- Raises:
ValueError – if cfunit is
strand calendar is not provided or invalid, or if the cfunit string is invalid
Example
>>> cfunit_str = 'day since 2018-01-01 00:00:00.00000000 UTC' >>> cftime_to_datetime64(10, cfunit_str, "gregorian") array(['2018-01-11T00:00:00.000000'], dtype='datetime64[us]')
- pyaerocom.units.datetime.utils.get_tot_number_of_seconds(ts_type: str, dtime: Series | None = None)[source]
Get total no. of seconds for a given frequency
- Parameters:
- Raises:
AttributeError – DESCRIPTION.
- Returns:
DESCRIPTION.
- Return type:
TYPE
- pyaerocom.units.datetime.utils.infer_time_resolution(time_stamps, dt_tol_percent=5, minfrac_most_common=0.8) TsType[source]
Infer time resolution based on input time-stamps
Calculates time difference dt between consecutive timestamps provided via input array or list. Then it counts the most common dt (e.g. 86400 s for daily). Before inferring the frequency it then checks all other dts occurring in the input array to see if they are within a certain interval around the most common one (e.g. +/- 5% as default, via arg dt_tol_percent), that is, 86390 would be included if most common dt is 86400 s but not 80000s. Then it checks if the number of dts that are within that tolerance level around the most common dt exceed a certain fraction (arg minfrac_most_common) of the total number of dts that occur in the input array (default is 80%). If that is the case, the most common frequency is attempted to be derived using
TsType.from_total_seconds()based on the most common dt (in this example that would be daily).- Parameters:
time_stamps (pandas.DatetimeIndex, or similar) – list of time stamps
dt_tol_percent (int) – tolerance in percent of accepted range of time diffs with respect to most common time difference.
minfrac_most_common (float) – minimum required fraction of time diffs that have to be equal to, or within tolerance range, the most common time difference.
- Raises:
TemporalResolutionError – if frequency cannot be derived.
- Returns:
inferred frequency
- Return type:
- pyaerocom.units.datetime.utils.is_year(val) bool[source]
Check if input is / may be year
- Parameters:
val – input that is supposed to be checked
- Returns:
True if input is a number between -2000 and 10000, else False
- Return type:
- pyaerocom.units.datetime.utils.seconds_in_periods(timestamps, ts_type)[source]
Calculates the number of seconds for each period in timestamps.
- Parameters:
timestamps (numpy.datetime64 or numpy.ndarray) – Either a single datetime or an array of datetimes.
ts_type (str) – Frequency of timestamps.
- Returns:
Array with same length as timestamps containing number of seconds for each period.
- Return type:
np.array
- pyaerocom.units.datetime.utils.to_datetime64(value)[source]
Convert input value to numpy.datetime64
- Parameters:
value – input value that is supposed to be converted, needs to be either str, datetime.datetime, pandas.Timestamp or an integer specifying the desired year.
- Returns:
input timestamp converted to datetime64
- Return type:
datetime64
- pyaerocom.units.datetime.utils.to_pandas_timestamp(value)[source]
Convert input to instance of
pandas.Timestamp- Parameters:
value – input value that is supposed to be converted to time stamp
- Return type:
General helper methods for the pyaerocom library.
- class pyaerocom.units.datetime.tstype.TsType(val)[source]
- FROM_PANDAS = {'D': 'daily', 'MS': 'monthly', 'Q': 'season', 'W-MON': 'weekly', 'YS': 'yearly', 'h': 'hourly', 'min': 'minutely'}
- TOL_SECS_PERCENT = 5
- TO_NUMPY = {'daily': 'D', 'hourly': 'h', 'minutely': 'm', 'monthly': 'M', 'weekly': 'W', 'yearly': 'Y'}
- TO_PANDAS = {'daily': 'D', 'hourly': 'h', 'minutely': 'min', 'monthly': 'MS', 'season': 'Q', 'weekly': 'W-MON', 'yearly': 'YS'}
- TO_SI = {'daily': 'd', 'hourly': 'h', 'minutely': 'min', 'monthly': 'month', 'secondly': 's', 'weekly': 'week', 'yearly': 'yr'}
- TSTR_TO_CF = {'daily': 'days', 'hourly': 'hours', 'monthly': 'days', 'yearly': 'days'}
- TS_MAX_VALS = {'daily': 180, 'hourly': 168, 'minutely': 360, 'monthly': 120, 'weekly': 104}
- VALID = ('minutely', 'hourly', 'daily', 'weekly', 'monthly', 'yearly', 'native', 'coarsest')
- VALID_ITER = ('minutely', 'hourly', 'daily', 'weekly', 'monthly', 'yearly')
- check_match_total_seconds(total_seconds: int | float) bool[source]
Check if this object matches with input interval length in seconds
- static from_total_seconds(total_seconds: int | float) TsType[source]
Try to infer TsType based on interval length
- Parameters:
- Raises:
TemporalResolutionError – If no TsType can be inferred for input number of seconds
- Return type:
- property next_lower: TsType
Next lower resolution code
This will go to the next lower base resolution, that is if current is 3daily, it will return weekly, however, if current exceeds next lower base, it will iterate that base, that is, if current is 8daily, next lower will be 2weekly (and not 9daily).
- property num_secs: float
Number of seconds in one period
Note
Be aware that for monthly frequency the number of seconds is not well defined!
- to_timedelta64() timedelta64[source]
Convert frequency to timedelta64 object
Can be used, e.g. as tolerance when reindexing pandas Series
- Return type:
timedelta64
- pyaerocom.units.datetime.tstype.get_highest_resolution(ts_type: str | TsType, *ts_types: str | TsType) str[source]
Get the highest resolution from several ts_type codes
- Parameters:
ts_type (str) – first ts_type
*ts_types – one or more additional ts_type codes
- Returns:
the ts_type that corresponds to the highest resolution
- Return type:
- Raises:
ValueError – if one of the input ts_type codes is not supported
- pyaerocom.units.datetime.tstype.get_lowest_resolution(ts_type: str | TsType, *ts_types: str | TsType) str[source]
Get the lowest resolution from several ts_type codes
- Parameters:
ts_type (str) – first ts_type
*ts_types – one or more additional ts_type codes
- Returns:
the ts_type that corresponds to the lowest resolution
- Return type:
- Raises:
ValueError – if one of the input ts_type codes is not supported
- pyaerocom.units.datetime.tstype.sort_ts_types(ts_types: list[str | TsType]) list[str][source]
Sort a list of ts_types in ascending order, returning them as strings.
- Parameters:
ts_types (list) – list of strings (or instance of
TsType) to be sorted- Returns:
list of strings with sorted frequencies
- Return type:
- Raises:
TemporalResolutionError – if one of the input ts_types is not supported